







mysql
数据库设计范式
- 1NF:关系R属于第一范式,当且仅当R中的每一个属性A的值域只包含原子项
- 2NF:在满足1NF的基础上,消除主属性对码的部分依赖.如果主键有好几个,那么非主键必须全部依赖主键,不能部分依赖主键。我的理解是减少主键,如果一个主键就可以确定一行,那就没必要设置第2个主键。
- 3NF:在满足2NF的基础上,消除非主属性对码的传递函数依赖
总结:1范式将列拆分,2范式给表找主键,3范式将非主键部分再进行拆分表。
sql语言
- DQL
- DML
- TCL:事务控制
- DCL:权限控制
- DDL:数据库操作
- CCL:指针控制
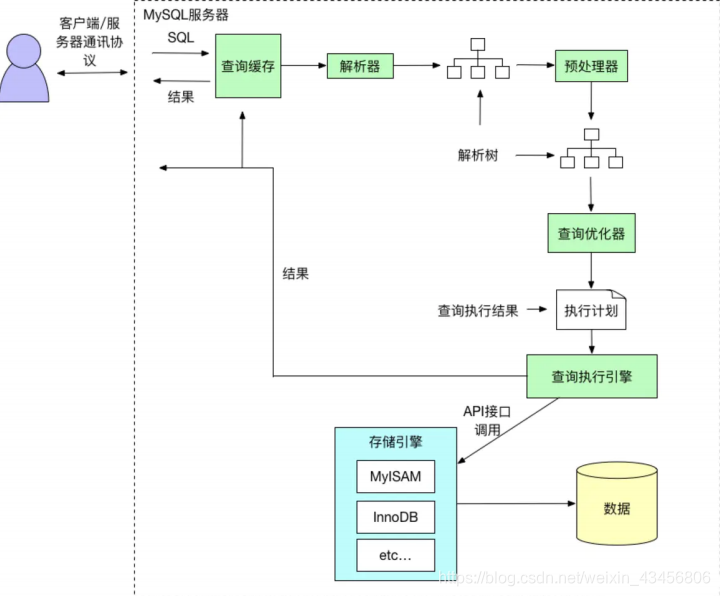
MySQL架构层:connectionPool->sql Interface->Parser(将sql优化)->Optimizer(拆分sql)->Cacher&Buffer(查看缓存)->存储引擎(MyISAM、InnoDB、Archive)->文件,日志
mysql存储
独占模式
- 日志组文件:ib_logfile0和ib_logfile1,默认5M
- 表结构文件:*.frm
- 独占表空间文件:*.ibd
- 字符集和排序规则文件:db.opt
- binlog二进制日志文件:记录主数据库服务器的DDL和DML操作
- 二进制日志索引文件:Master-bin.index
- information_schema:存储mysql的元数据,tables表存储所有数据库的表名称(schema数据库的实例)
共享模式 - 数据都在ibdata1
sql语句
- show columns from 表名
- show create table from 表名
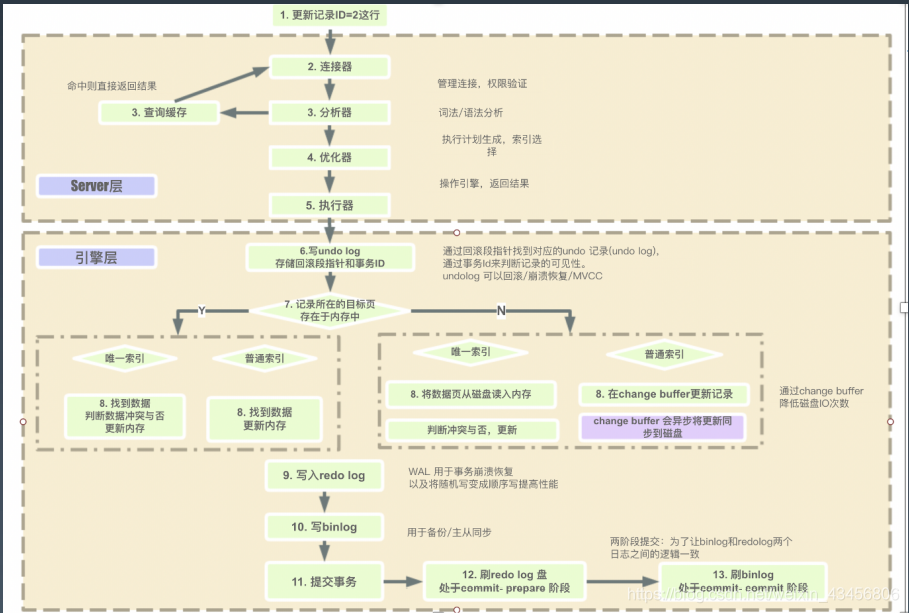
mysql简化执行流程
执行引擎和状态
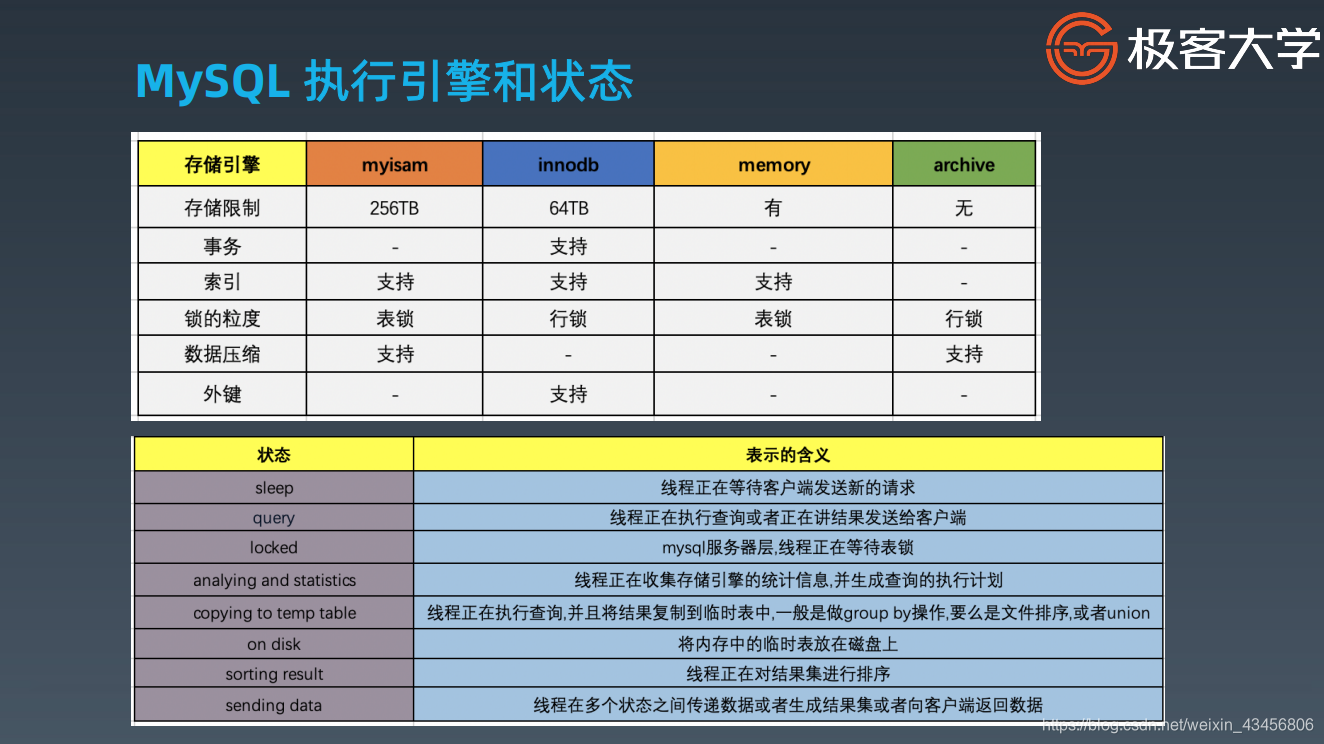
MyISAM没有事务、InnoDB对事务支持好、Archive压缩文件适合冷备份、memory是内存型数据库
mysql对sql的执行顺序
- from
- on
- join
- where
- goup by
- having+聚合函数
- select
- order by
- limit
索引原理
将索引按照块放到b+树中,一般不超过三层,叶子节点为数据,也就是说,按照索引查数据,一次能查出很多条而不是一条。
参数配置优化
查看参数配置:show variables libe xxx
my.cnf文件
【mysqld】给server端用的参数
【mysql】给客户端(命令行)用的参数
参数配置优化
- 环境请求变量
- max_connections 最大连接数
- back_log
- wait_timeout和interative_timeout 超时连接数
- 缓冲区变量(对查询性能有影响)
- key_buffer_size
- query_chche_size(查询缓存简称QC),缓存的查询数据大小直接相关
- max_connect_errors
- sort_buffer_size
- max_allowed_packet=32M 发包的数量
- join_buffer_size=2M
- thread_chche_size=300
- 配置Innodb的几个变量
- innodb_buffer_pool_size
- innodb_thread_concurrency=0
- innodb_long_buffer_size
- read_buffer_size=1M
- bulk_insert_buffer_size=64M
mysql数据库设计优化
- 如何恰当选择引擎?创建表时create语句后加engine可以选择对应的数据库引擎
- 库表如何命名?
- 如何合理拆分宽表?
- 如何选择恰当数据类型:明确、尽量小
- char、varchar 的选择
- (text/blob/clob)的使用问题?
- 文件、图片是否要存入到数据库?
- 时间日期的存储问题?注意时区问题
- 数值的精度问题?
- 是否使用外键、触发器?
- 唯一约束和索引的关系?唯一约束(主键)本身是索引
- 是否可以冗余字段?
- 是否使用游标、变量、视图、自定义函数、存储过程?
- 自增主键的使用问题?单表主键,分布式主键
- 能够在线修改表结构(DDL 操作)?修改数据库导致锁整表
- 逻辑删除还是物理删除?
- 要不要加 create_time,update_time 时间戳?
- 数据库碎片问题?
- 如何快速导入导出、备份数据?
mysql事务与锁
事务可靠性模型
- 原子性:一次失误中的操作要么全部成功,要么全部失败
- 一致性:跨表.跨行,跨事务,数据库始终保持一致状态(两个原子性的操作不一定是原子性)
- 隔离性(可见性):保护事务不会互相干扰,包含4种隔离级别
- 持久性:事务提交成功后,不会丢数据,
mysql事务
SHOW ENGINE INNODB STATUS;
- 表级锁:表明事务稍后要进行那种类型的锁定
- 共享意向锁:打算在某些行上设置共享锁
- 排他意向锁:打算对某些行设置排他锁
- insert意向锁:insert操作设置的间隙锁
- 其他:自增锁,lock tables
- 行级锁:
- 记录锁:始终锁定索引记录
- 间隙锁
- 临键锁
- 死锁
- 阻塞与互相等待
- 增删改,锁定读
- 死锁检测和自动回滚
- 锁粒度与程序设计
- 四种隔离级别
- 读未提交:其他事务未提交的数据,当前事务可以看到.会出现胀读
- 读已提交:当前事务在运行过程中,因其他事务的提交,而导致当前事务两次读取的结果不一致.特点:每次查询时会创建一个快照
- 可重复读:特点:事务开始时会创建一个快照
- 可串行化:事务必须串行进行,多版本.
- mysql可以默认是全局的隔离级别.可以设置会话的隔离级别.
- undo.log
- 保证事务的原子性
- 用处:事务回滚
- 每一条insert和update都对应delete和相反的update
- 保存位置:system tablespace
- redo.log
- 确保事务持久性
- 当事务提交后,先计入日志,在写入库文件
- MVCC 支持读已提交和可重复读
sql优化
- 使用合适的数据类型
- 存储引擎选择:
- InnoDB:聚集索引,锁粒度是行,InnoDB支持事务
- TokuDB(归档库):高压缩比,添加索引不影响读操作
- 避免隐式转换
- 索引
- hash
- B+树:一般是三层,
- 为什么主键是单调递增的?页分裂,主键在B+树中是一块一块的,如果不是递增,则增加一个新主键有可能会导致树的调整.
- 增加索引是DDL操作,会锁表.
- 为什么主键长度不能太大?主键太大导致B+树上能放的主键变少
- 聚集索引和二级索引.主键索引的叶子节点直接是数据,二级索引叶子节点是主键.
写入优化
- 大量写入数据的的优化 select * from 表名 where (列1,列2)=(条件1,条件1)
- PerparedStatement减少sql解析
- Multiple Values/Add Batch减少交互
- Load Data,直接导入
模糊查询
- like 如果在前面添加%对导致不走索引
- 全文检索:solr/ES
连接查询
连接查询优化
驱动表的选择,避免笛卡尔积.
索引失效
- null,not,not in,函数都会导致索引失效
- 减少使用or,可以使用union(union all的区别)(如果or的左艳没有关系的话不能用union代替or),和like
乐观锁和悲观锁
- 悲观锁
select * from xxx for update(加锁)
update xxx
commit; - 乐观锁
select * form xxx
update xxx where value=oldValue

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









