






推荐系统实战Task02——小白日记
数据分析:
数据分析的价值主要在于熟悉了解整个数据集的基本情况包括每个文件里有哪些数据,具体的文件中的每个字段表示什么实际含义,以及数据集中特征之间的相关性,在推荐场景下主要就是分析用户本身的基本属性,文章基本属性,以及用户和文章交互的一些分布,这些都有利于后面的召回策略的选择,以及特征工程。
数据处理:
1、 导入包
2、 读取数据集中的所有文件
item_df = pd.read_csv(path+'articles.csv')
item_df = item_df.rename(columns={'article_id': 'click_article_id'}) #重命名,方便后续match
由于train_click_log.csv文件和test_click_log.csv文件的文章id字段都叫做’click_article_id’,为了方便后续进行match匹配,对’article_id’字段进行更换列名
3、对读取的数据进行处理
(1)对每个用户的点击时间戳进行排序
# 对每个用户的点击时间戳进行排序
trn_click['rank'] = trn_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
tst_click['rank'] = tst_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
分别为trn_click(读取的训练集)和tst_click(读取的测试集)增添一个rank列,此列是通过以user_id进行分组,对click_timestamp进行降序排序的结果。
此处采用了pandas DataFrame的.groupby().rank()这个操作
DataFrame.rank(axis=0, method='average', numeric_only=None, na_option='keep', ascending=True, pct=False)
功能:计算沿着轴的数值数据(1到n),返回排序的下标。
参数解释:
| 参数 | 含义 |
|---|---|
| axis | 0表示按行排序,1表示按列排序,默认为0 |
| method | 有‘average’, ‘min’, ‘max’, ‘first’取值,默认值为 average,表示出现相同值时的排名依据。 average表示在相等分组中,为各个值分配平均排名;min 表示使用整个分组的最小排名;max 表示使用整个分组的最大排名;first 表示按值在原始数据中的出现顺序分配排名 。 |
| numeric_only | 接受boolean值,默认值 None,仅包含float,int和boolean数据,仅对DataFrame或Panel对象有效 |
| na_option | 有‘keep’, ‘top’, ‘bottom’取值,默认值为keep,表示对nan值的处理;keep表示将nan值保留在原来的位置;top表示如果升序,将NA值排名第一;bottom 表示如果降序,将NA值排名第一 。 |
| ascending | boolean, 默认值 为True,True 为升序排名 ,False为降序排名 |
| pct | boolean, 默认值 False,表示计算数据的百分比等级 |
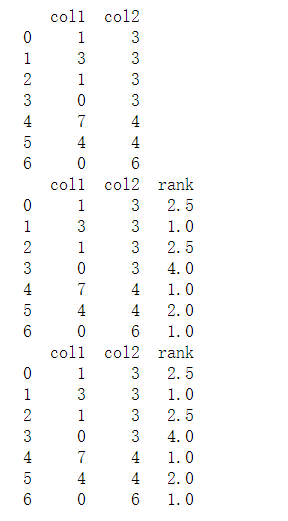
举个栗子
list1 = [1,3,1,0,7,4,0]
list2 = [3,3,3,3,4,4,6]
df1 = pd.DataFrame({'col1':list1,'col2':list2})
print(df1)
df2=df1
df2['rank'] = df2.groupby(['col2']).rank(method='min',ascending=False)
df1['rank'] = df1.groupby(['col2'])['col1'].rank(method='average',ascending=False)
print(df2)
print(df1)
结果如下:
(2)计算用户点击文章的次数
#计算用户点击文章的次数,并添加新的一列count
trn_click['click_cnts'] = trn_click.groupby(['user_id'])['click_timestamp'].transform('count')
tst_click['click_cnts'] = tst_click.groupby(['user_id'])['click_timestamp'].transform('count')
(3)将trn_click和item_df进行左连接
trn_click = trn_click.merge(item_df, how='left', on=['click_article_id'])
trn_click.head()
ps:同样对tst_click进行相同操作,在此就不一一将代码贴出来了
(4) 将trn_click和tst_click进行纵向合并
user_click_merge = trn_click.append(tst_click) #两表纵向合并
user_click_count = user_click_merge.groupby(['user_id', 'click_article_id'])['click_timestamp'].agg({'count'}).reset_index()
经观察,训练集和测试集的用户是完全不一样的,训练集的用户ID由0 ~ 199999,而测试集A的用户ID由200000 ~ 249999。
对user_click_merge以’user_id’, 'click_article_id’进行分组,并对’click_timestamp’聚合(count数量统计)
(5)时间进行归一化操作
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
user_click_merge['click_timestamp'] = mm.fit_transform(user_click_merge[['click_timestamp']])
user_click_merge['created_at_ts'] = mm.fit_transform(user_click_merge[['created_at_ts']])
user_click_merge = user_click_merge.sort_values('click_timestamp')
数据可视化
(1)对trn_click进行信息查看
trn_click.info() #用于获取trn_click的简要摘要
trn_click.describe() #对trn_click生成描述性统计
trn_click.groupby('user_id')['click_article_id'].count().min()
# 计算trn_click中每个用户最少点击文章数
trn_click.user_id.nunique() #计算trn——click中的用户数量
plt.figure()
plt.figure(figsize=(15, 20))
i = 1
for col in ['click_article_id', 'click_timestamp', 'click_environment', 'click_deviceGroup', 'click_os', 'click_country',
'click_region', 'click_referrer_type', 'rank', 'click_cnts']:
plot_envs = plt.subplot(5, 2, i)
i += 1
v = trn_click[col].value_counts().reset_index()[:10]
fig = sns.barplot(x=v['index'], y=v[col])
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(col)
plt.tight_layout()
plt.show()
创建画布,从trn_click中提取出我们所需要的列,对其进行value统计,将value_counts前十位以柱状图的形式呈现。
结果如下:

总结:
从点击时间clik_timestamp来看,分布较为平均,可不做特殊处理。由于时间戳是13位的,后续将时间格式转换成10位方便计算。
从点击环境click_environment来看,仅有1922次(占0.1%)点击环境为1;仅有24617次(占2.3%)点击环境为2;剩余(占97.6%)点击环境为4。
从点击设备组click_deviceGroup来看,设备1占大部分(60.4%),设备3占36%。
(2)对item_df(存储文章信息)进行信息查看
item_df.head().append(item_df.tail()) #文章数据集前五和后行数据进行查看
item_df.shape # 查看item_df的大小(364047,4)
#这里的364047刚好是文章的数量,因为article_id一列值具有唯一性
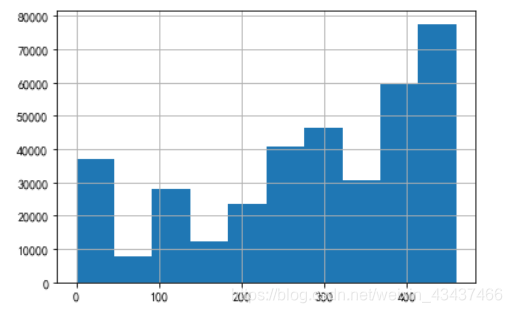
print(item_df['category_id'].nunique()) #输出文章主题数(结果为461)
item_df['category_id'].hist() #画出文章主题数'category_id'的分布直方图
(3)对user_click_count(存储文章信息)进行信息查看
print(user_click_count[user_click_count['count']>7]) #输出count大于7的数据
user_click_count['count'].unique() #对count列进行unique函数去重复元素,并按元素由大到小返回一个新的无元素重复的元组或者列表
user_click_count.loc[:,'count'].value_counts() #统计用户点击文章次数
(4)对user_click_merge进行信息查看
#用户重复点击次数统计
user_click_count = user_click_merge.groupby(['user_id', 'click_article_id'])['click_timestamp'].agg({'count'}).reset_index()
user_click_count[:10]
def plot_envs(df, cols, r, c):
plt.figure()
plt.figure(figsize=(10, 5))
i = 1
for col in cols:
plt.subplot(r, c, i)
i += 1
v = df[col].value_counts().reset_index()
fig = sns.barplot(x=v['index'], y=v[col])
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(col)
plt.tight_layout()
plt.show()
sample_user_ids = np.random.choice(tst_click['user_id'].unique(), size=5, replace=False)
sample_users = user_click_merge[user_click_merge['user_id'].isin(sample_user_ids)]
cols = ['click_environment','click_deviceGroup', 'click_os', 'click_country', 'click_region','click_referrer_type']
for _, user_df in sample_users.groupby('user_id'):
plot_envs(user_df, cols, 2, 3)
在tst_click中随机挑选5个user_id,然后对挑选出的5个用户分别画出列表cols中含有的列的柱状图。
作用:通过随机抽样画其柱状图来观察这些用户的点击环境、点击系统等等变化是否变化明显。
我的问题:为什么这5位用户要在tst_click中进行挑选,而不是在user_click_merge中进行挑选,这样可挑选的数据不是更多吗?
(4)点击时间差平均值和前后点击文章的创建时间差的平均值的计算
def mean_diff_time_func(df, col):
df = pd.DataFrame(df, columns={col})
df['time_shift1'] = df[col].shift(1).fillna(0)
df['diff_time'] = abs(df[col] - df['time_shift1'])
return df['diff_time'].mean()
mean_diff_click_time = user_click_merge.groupby('user_id')['click_timestamp', 'created_at_ts'].apply(lambda x: mean_diff_time_func(x, 'click_timestamp'))
mean_diff_created_time = user_click_merge.groupby('user_id')['click_timestamp', 'created_at_ts'].apply(lambda x: mean_diff_time_func(x, 'created_at_ts'))
(5)查看这些用户前后查看文章的相似性
item_idx_2_rawid_dict = dict(zip(item_emb_df['article_id'], item_emb_df.index))
del item_emb_df['article_id']
item_emb_np = np.ascontiguousarray(item_emb_df.values, dtype=np.float32)
#函数将一个内存不连续存储的数组转换为内存连续存储的数组,使得运行速度更快。
# 随机选择5个用户,查看这些用户前后查看文章的相似性
sub_user_ids = np.random.choice(user_click_merge.user_id.unique(), size=15, replace=False)
sub_user_info = user_click_merge[user_click_merge['user_id'].isin(sub_user_ids)]
def get_item_sim_list(df):
sim_list = []
item_list = df['click_article_id'].values
for i in range(0, len(item_list)-1):
emb1 = item_emb_np[item_idx_2_rawid_dict[item_list[i]]]
emb2 = item_emb_np[item_idx_2_rawid_dict[item_list[i+1]]]
sim_list.append(np.dot(emb1,emb2)/(np.linalg.norm(emb1)*(np.linalg.norm(emb2))))
sim_list.append(0)
return sim_list
for _, user_df in sub_user_info.groupby('user_id'):
item_sim_list = get_item_sim_list(user_df)
plt.plot(item_sim_list)
通过对各种字段进行统计,对数据有进一步的总结
总结:
训练集和测试集的用户id没有重复。
有极少数用户存在文章重复点击的情况。
用户点击文章的次数有很大的区分度,之后可以根据这个制作衡量用户活跃度的特征。
存在着热门新闻与冷门新闻。
用户看的新闻,具有比较强的相关性,依据相关性可以为用户推荐新闻提供很大的帮助。
存在小部分用户阅读类型广泛。
用户点击的文章字数有比较大的区别, 这个可以作为用户对于文章字数的喜爱导向。
不同用户点击文章的时间差也会有所区别, 这个可以反映用户对于文章时效性的偏好。
代码不太理解的地方
tmp = user_click_merge.sort_values('click_timestamp')
tmp['next_item'] = tmp.groupby(['user_id'])['click_article_id'].transform(lambda x:x.shift(-1))
union_item = tmp.groupby(['click_article_id','next_item'])['click_timestamp'].agg({'count'}).reset_index().sort_values('count', ascending=False)
print(union_item)
union_item[['count']].describe()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









