







前言
实践过程可不看,末尾直接是答案!
一、需求描述
写一段代码,要求输入任意一个字典(可有其他参数输入),无论它是什么样的结构,都能通过该段代码获取其取值路径,例如字典:
test_data = {
"a":{"b":1},
"c":[2,{"d":3}],
"e":"success",
}需要输出:
test_data["a"]["b"]
test_data["c"][0]
test_data["c"][1]["d"]
test_data["e"]二、方案分析
1、这是一个拆解字典的过程,很容易想到使用遍历dict.items()的方法进行处理
2、字典可包含python所有数据类型,如字典、列表、元组、字符串等等
3、根据需求描述,没有对数据类型进行限制,因此这里只对Json格式数据类型进行处理
4、这里先实现需求的部分功能(后续继续优化),限制数据类型范围为:字典、列表和其他(如字符串、数字等无法拆分的末端值)
5、这里需要对路径进行循环利用,如果一个字典深度很长,那么在循环处理时,就得不断使用for来不断解包,感觉递归更好一些
6、递归的时候,如果一开始解压的是字典,那么当遇到列表的情况,可能就无法递归了
7、感觉这问题没法解决了呀?我相信只要是有逻辑的东西,就一定可以通过代码实现!先动手试试吧!
三、实践过程
1、采用递归方式,同时递归字典或列表:版本1
def get_value_path(data):
'''递归一个序列(传入列表或字典),如果列表中的元素不是字典或列表,则输出;如果是列表,则继续递归,直到全部输出非字典或列表的元素'''
if isinstance(data, list):
for index,value in enumerate(data):
get_value_path(value)
elif isinstance(data, dict):
for key,value in data.items():
get_value_path(value)
else:
yield data
if __name__ == "__main__":
test_data = {
"a": {"b": 1},
"c": [2, {"d": 3}],
"e": "success",
}
for value in get_value_path(test_data):
print(value)(1)实践结果:
最终的输出为空,即没有任何输出

(2)案例分析:
①程序逻辑应该简单明了,即判断传入数据是列表或字典则继续递归,不是则输出
②上述没有输出,是因为假设第一次解压的是字典,第二次解压的是列表,意味着在两个不同的for循环中切换,但程序是顺序执行的,因此在一个循环中就已经遍历了所有,以至于没有输出,过程如下:
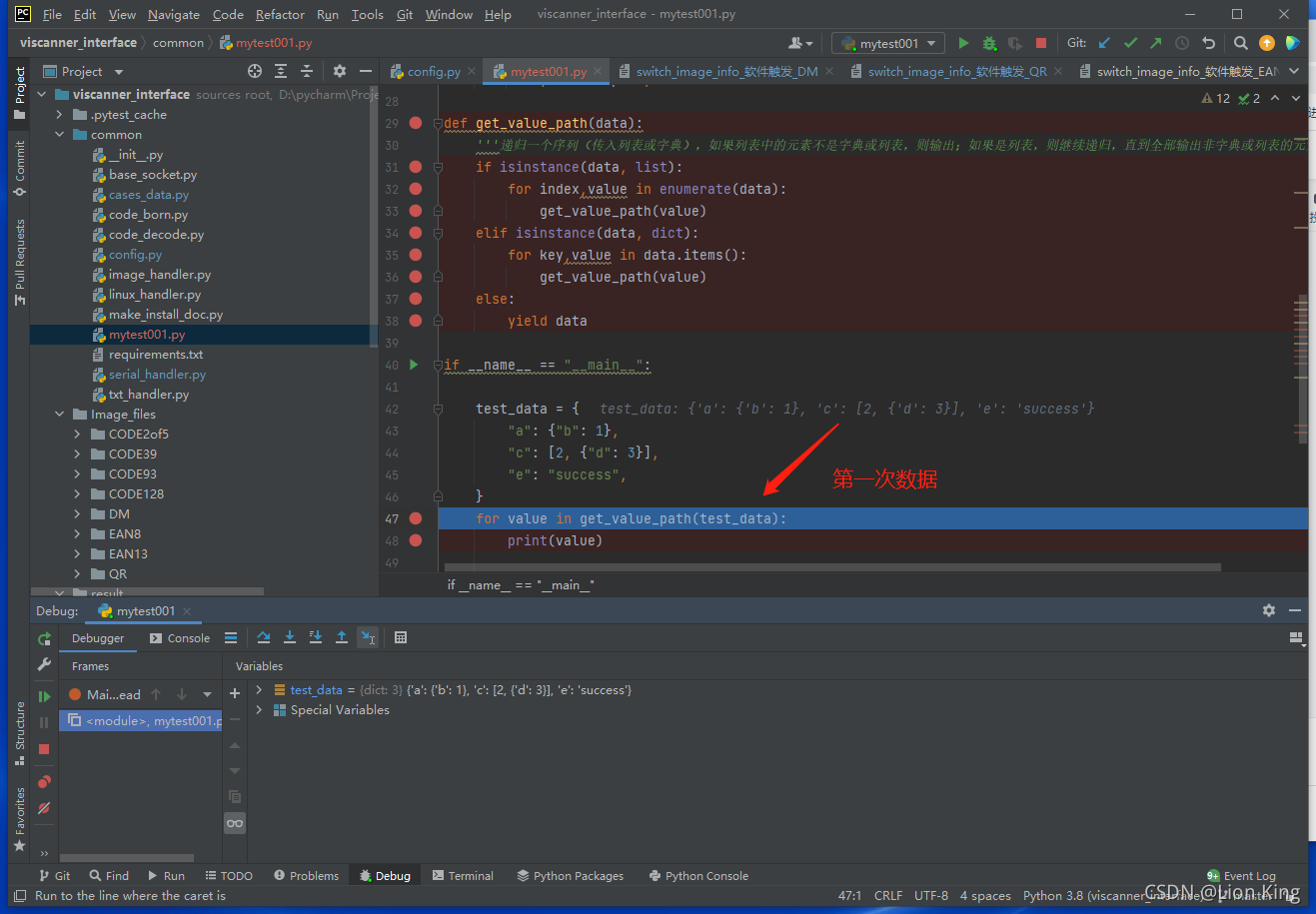
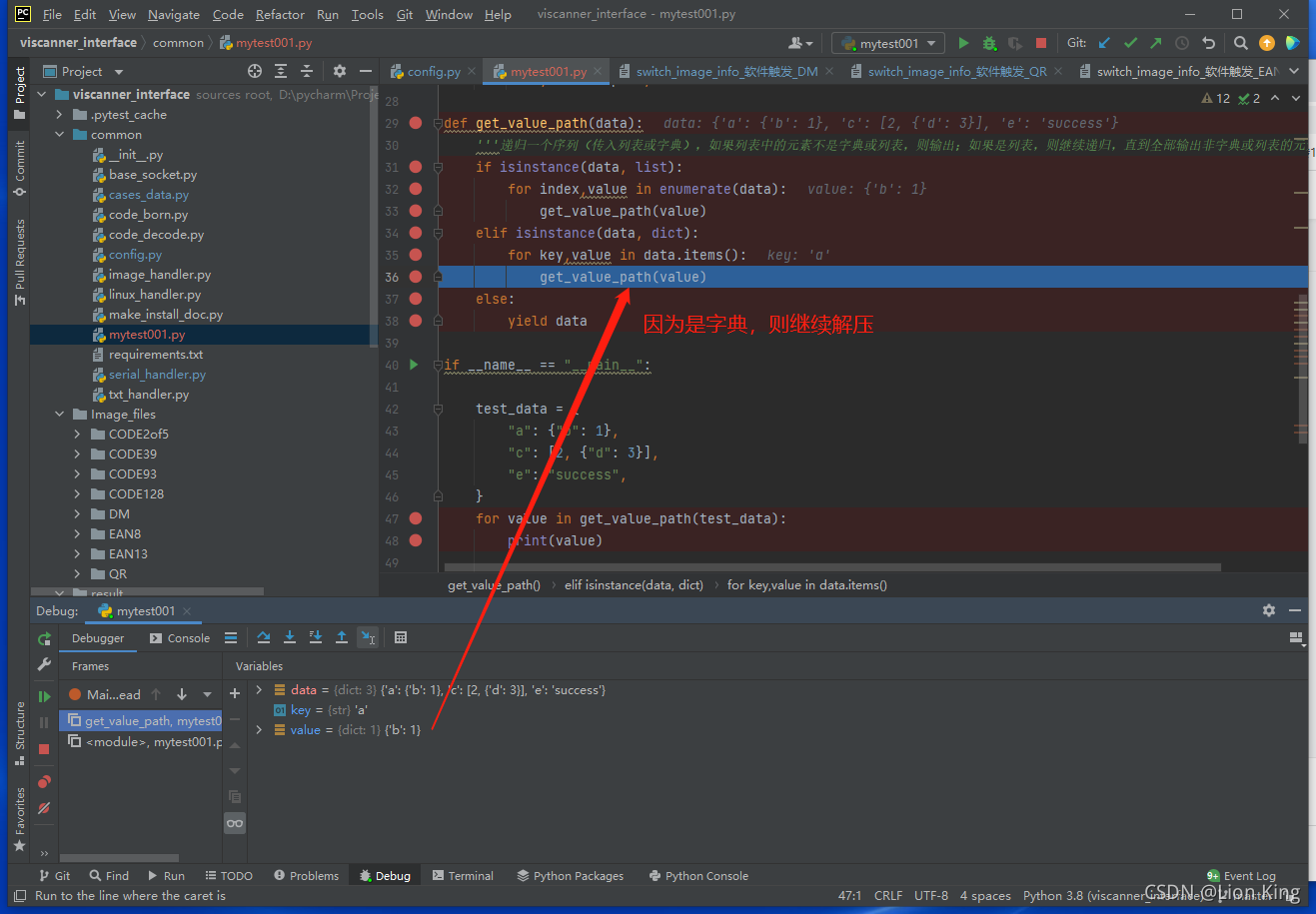
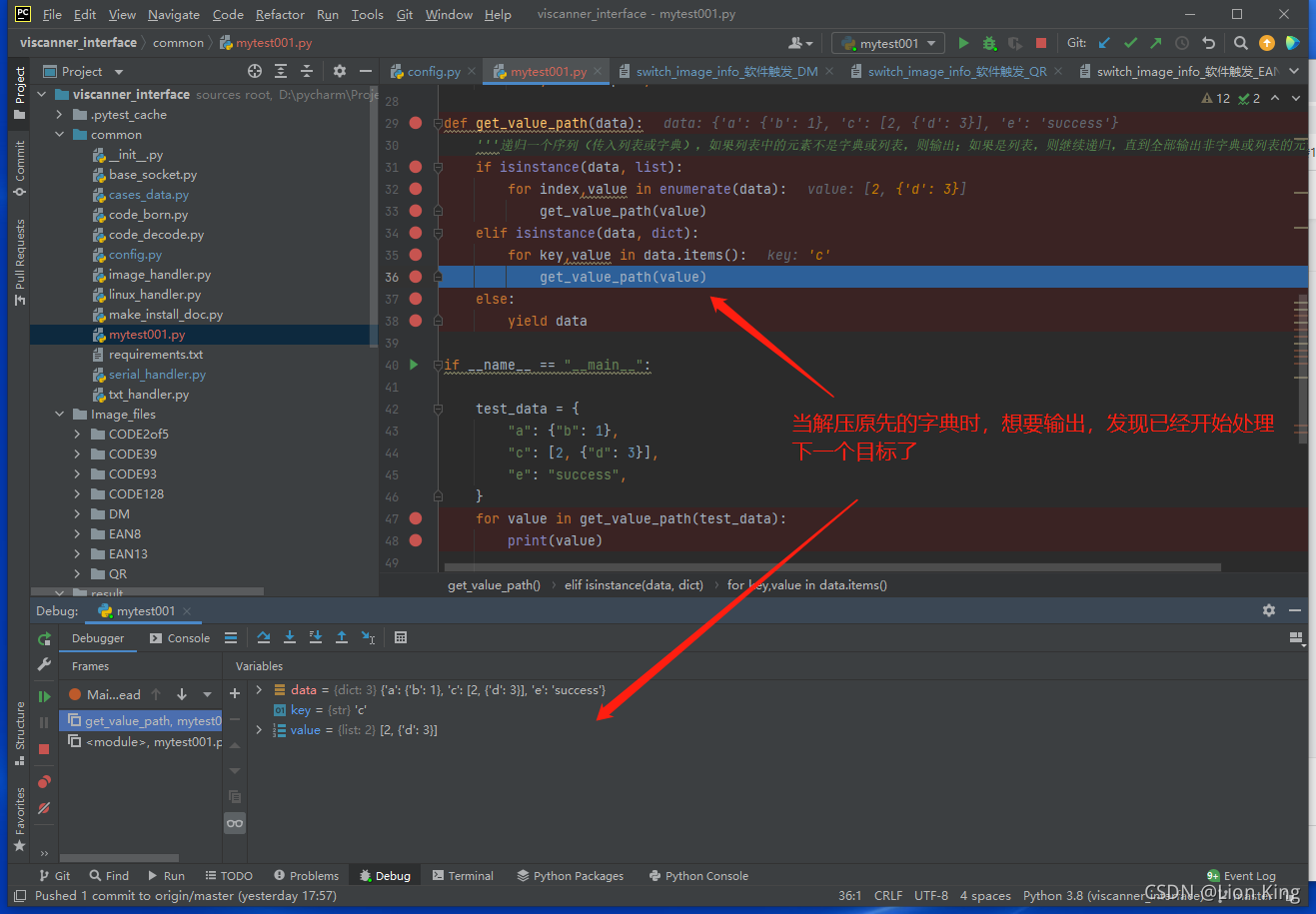
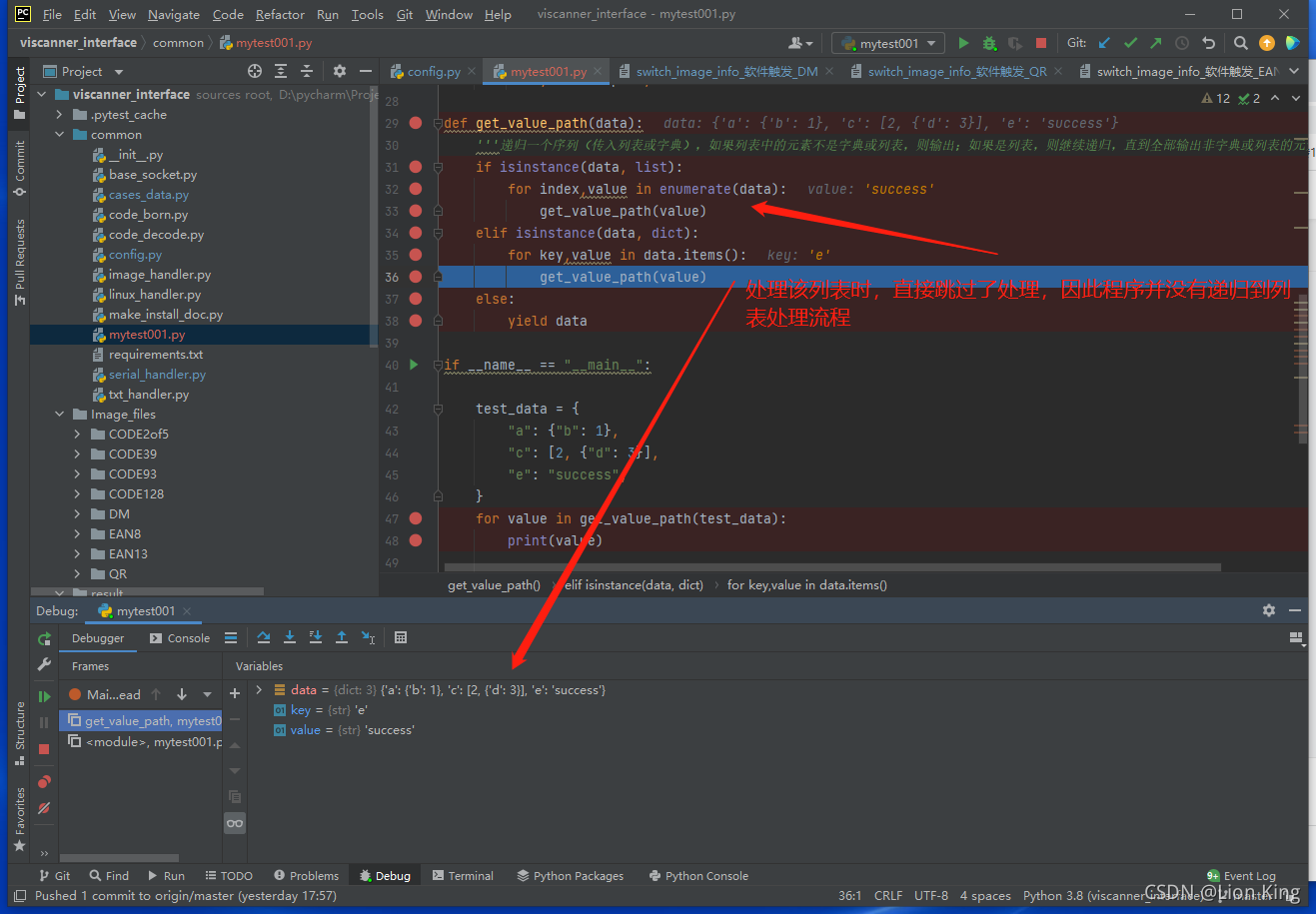
(3)思考:
应该需要在for循环中,使用yield继续输出
2、采用递归方式,同时递归字典或列表:版本2
def get_value_path(data):
'''递归一个序列(传入列表或字典),如果列表中的元素不是字典或列表,则输出;如果是列表,则继续递归,直到全部输出非字典或列表的元素'''
if isinstance(data, list):
for index,value in enumerate(data):
if isinstance(value, list):
get_value_path(value)
elif isinstance(value, dict):
get_value_path(value)
else:
yield value
elif isinstance(data, dict):
for key,value in data.items():
if isinstance(value, list):
get_value_path(value)
elif isinstance(value, dict):
get_value_path(value)
else:
yield value
else:
yield data
if __name__ == "__main__":
test_data = {
"a": {"b": 1},
"c": [2, {"d": 3}],
"e": "success",
}
for value in get_value_path(test_data):
print(value)(1)实践结果:
只输出了一个值:success

(2)案例分析:
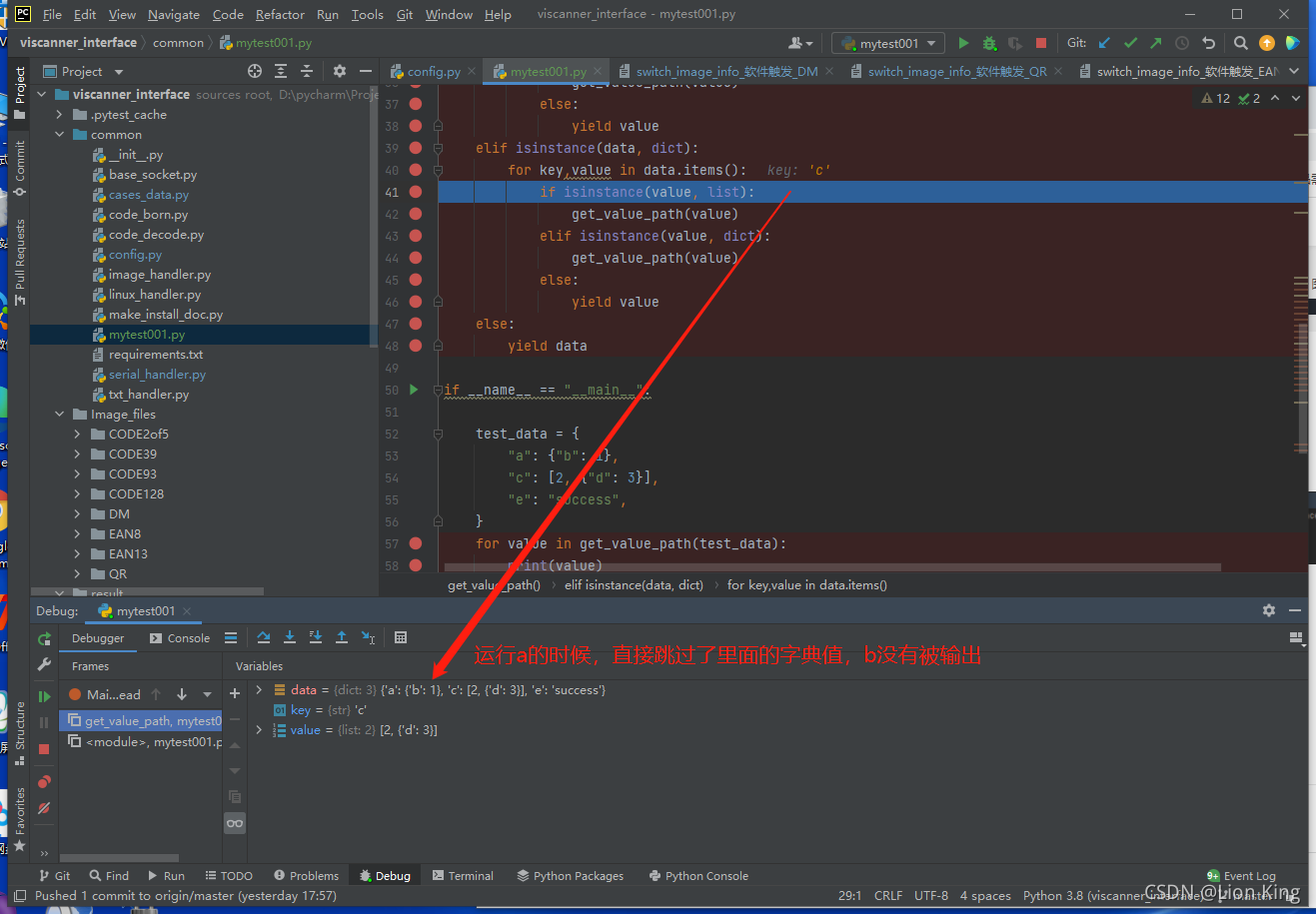
(3)思考:
这是为什么呢?这个程序只对一级包做了处理,没法处理到二级包?整个解包过程确实是对一级包做的处理,因为for循环在这里递归的时候,数据取的就是一级包的数据(即使将value全部更换为data),实验如下:
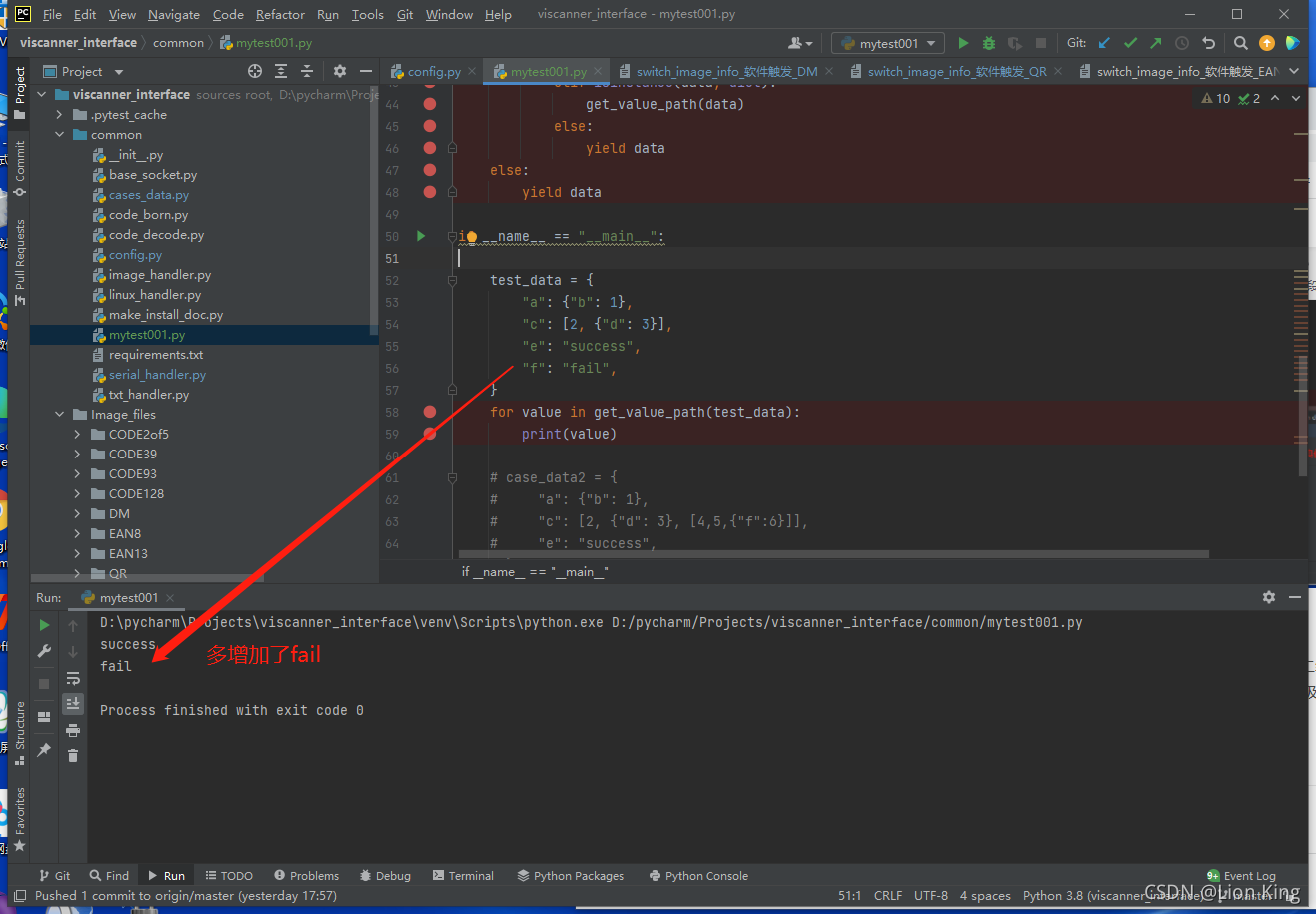
那要想解包到第二层,该怎么做呢?
3、采用递归方式,同时递归字典或列表:版本3
def get_value_path(data):
'''递归一个序列(传入列表或字典),如果列表中的元素不是字典或列表,则输出;如果是列表,则继续递归,直到全部输出非字典或列表的元素'''
if isinstance(data, list):
for index,data in enumerate(data):
if isinstance(data, list):
for index, data in enumerate(data):
if isinstance(data, list):
get_value_path(data)
elif isinstance(data, dict):
get_value_path(data)
else:
yield data
# get_value_path(data)
elif isinstance(data, dict):
for key, data in data.items():
if isinstance(data, list):
get_value_path(data)
elif isinstance(data, dict):
get_value_path(data)
else:
yield data
# get_value_path(data)
else:
yield data
elif isinstance(data, dict):
for key,data in data.items():
if isinstance(data, list):
for index, data in enumerate(data):
if isinstance(data, list):
get_value_path(data)
elif isinstance(data, dict):
get_value_path(data)
else:
yield data
# get_value_path(data)
elif isinstance(data, dict):
for key, data in data.items():
if isinstance(data, list):
get_value_path(data)
elif isinstance(data, dict):
get_value_path(data)
else:
yield data
# get_value_path(data)
else:
yield data
else:
yield data
if __name__ == "__main__":
test_data = {
"a": {"b": 1},
"c": [2, {"d": 3}],
"e": "success",
"f": "fail",
}
for value in get_value_path(test_data):
print(value)(1)实践结果:
采用嵌套的方式,能解到第二层:

(2)案例分析:
这样的方式,从结果看起来可行,但是如果要解包很多层,代码就只剩下复制粘贴了,只是,这样的世界何时是个尽头?
(3)思考:
能否先知道这个字典的深度,再通过生成函数的方式,以eval()或exec()实现整段代码的运行?这样做相当麻烦,但貌似是个可行的思路。
4、采用递归方式,同时递归字典或列表:版本4
min_def = '''
def get_value_path(data):
data = data
if isinstance(data, list):
for index,data in enumerate(data):
if isinstance(data, list):
get_value_path(data)
elif isinstance(data, dict):
get_value_path(data)
else:
yield data
elif isinstance(data, dict):
for key,data in data.items():
if isinstance(data, list):
get_value_path(data)
elif isinstance(data, dict):
get_value_path(data)
else:
yield data
else:
yield data
test_data = {
"a": {"b": 1},
"c": [2, {"d": 3}],
"e": "success",
"f": "fail",
}
for value in get_value_path(test_data):
print(value)
'''
if __name__ == "__main__":
exec(min_def)(1)实践结果:
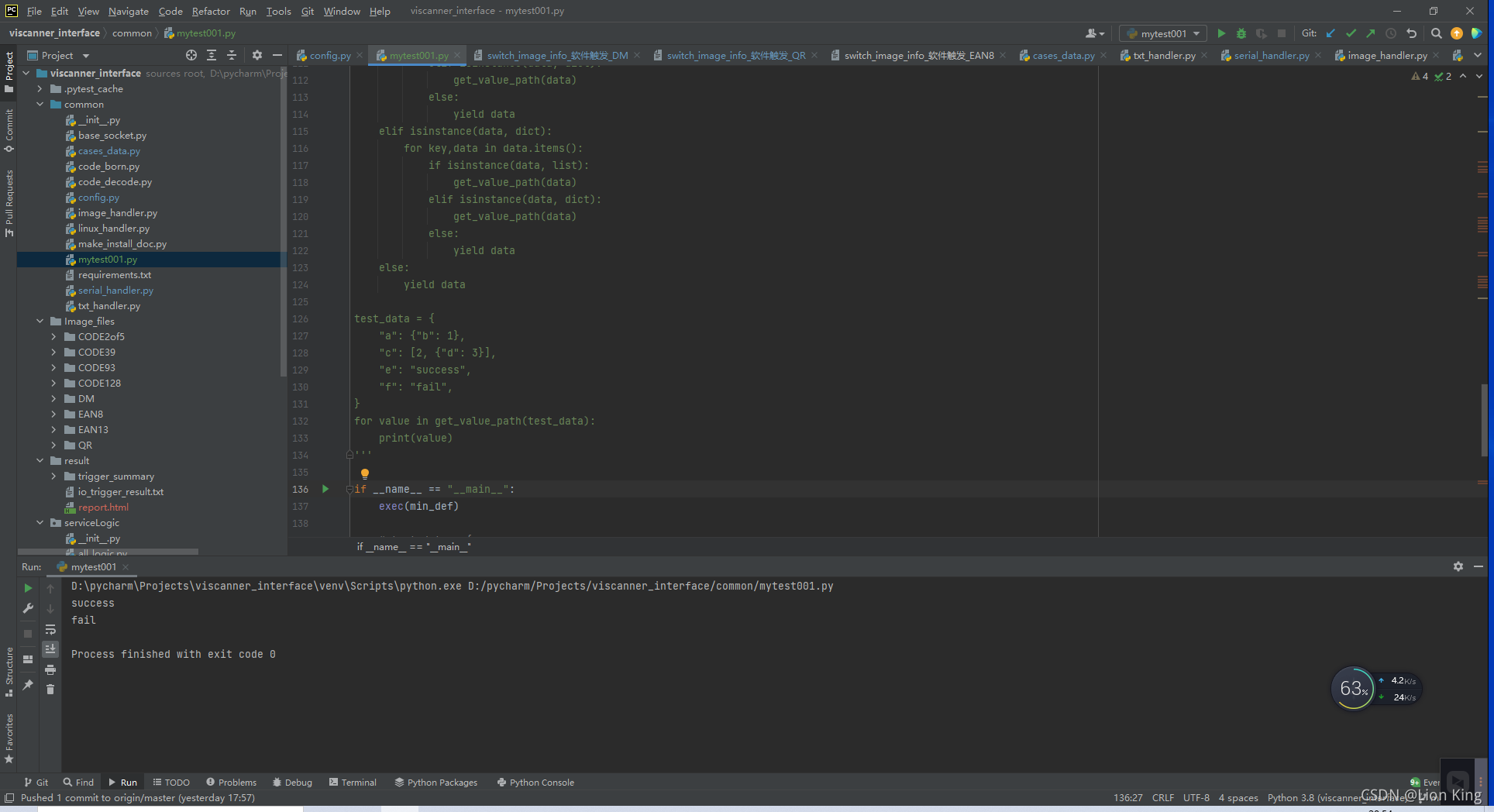
(2)案例分析:
通过这种方式是可以运行的,接下来就是对min_def参数化,以达到想要的结果。
(3)思考:
可能需要解决的问题有:python代码格式化问题(空格)、参数化问题、插入代码片段问题等等。
5、采用递归方式,同时递归字典或列表:版本5
# 数据格式:
# 替换单元1
replace_list='''
for index, data in enumerate(data):
if isinstance(data, list):
{list}
elif isinstance(data, dict):
{dict}
else:
yield data
'''
# 替换单元2:
replace_dict='''
for key,data in data.items():
if isinstance(data, list):
{list}
elif isinstance(data, dict):
{dict}
else:
yield data
'''
# 替换单元3:
replace_end = '''
get_value_path(data)
'''
# 最小单元:
min_def = '''
def get_value_path(data):
data = data
if isinstance(data, list):
for index,data in enumerate(data):
if isinstance(data, list):
{list}
elif isinstance(data, dict):
{dict}
else:
yield data
elif isinstance(data, dict):
for key,data in data.items():
if isinstance(data, list):
{list}
elif isinstance(data, dict):
{dict}
else:
yield data
else:
yield data
for value in get_value_path(test_data):
print(value)
'''
def add_spaces(str_src, n=0):
line = str_src.splitlines()
for index, l in enumerate(line):
line[index] = " "*n + line[index]
str_add = "\n".join(line)
return str_add
def base_point(str_src):
line = str_src.splitlines()
point = ""
for index, l in enumerate(line):
if "{list}" in l:
point = l.find("{list}")
break
return point
# n为dict的层数
def main(data,n=10):
# 变量test_data固定不变,因为min_def中会使用
test_data = data
# min_def的最终函数字符串
min_def_get = min_def
for i in range(n):
if i == n-1:
p = base_point(min_def_get)
str_a = str_b = add_spaces(replace_end, n=p)
def_add = min_def_get.format(list=str_a, dict=str_b)
min_def_get = def_add
else:
p = base_point(min_def_get)
str_a = add_spaces(replace_list, n=p)
str_b = add_spaces(replace_dict, n=p)
def_add = min_def_get.format(list=str_a, dict=str_b)
min_def_get = def_add
# print(min_def_get)
exec(min_def_get)
if __name__ == "__main__":
test_data01 = {
"a": {"b": 1},
"c": [2, {"d": 3},[4,5,6,7,8,9]],
"e": "success",
"f": "fail",
}
main(test_data01)(1)实践结果:
已经能够获取最终值!
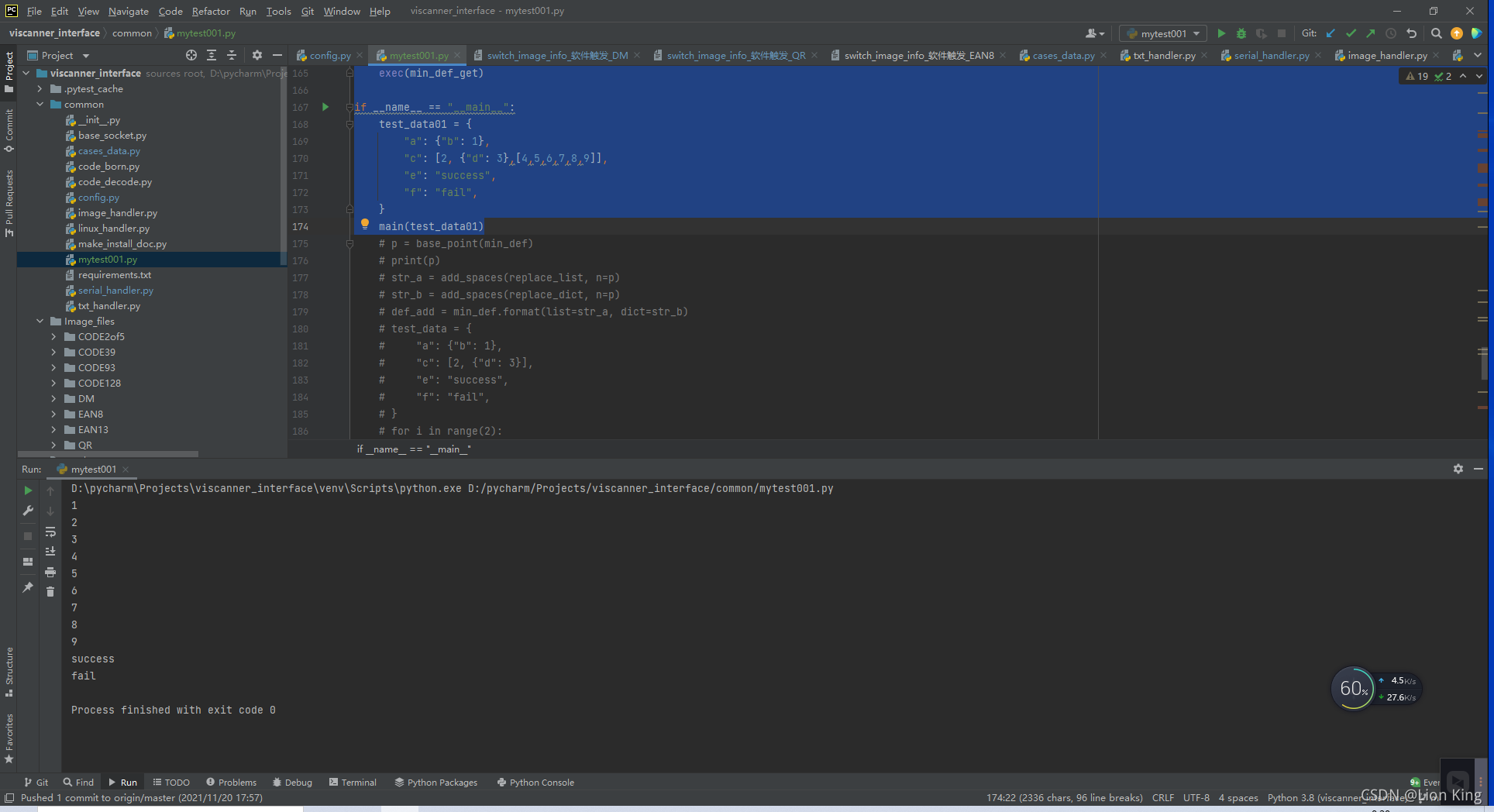
(2)案例分析:
能够通过该方式获取到指定值,说明也能够通过其获取其路径。
(3)思考:
如何获取路径呢?每一次递归都可以获得其路径的一部分,那么就可以通过拼接的方式获取其路径。
6、采用递归方式,同时递归字典或列表:版本6(20210516修改)
def print_value_paths(data, path=""):
if isinstance(data, dict):
for key, value in data.items():
print_value_paths(value, path + f'["{key}"]')
elif isinstance(data, list):
for index, item in enumerate(data):
print_value_paths(item, path + f"[{index}]")
else:
print(f"{path} = {data}")
test_data = {
"a":{"b":1},
"c":[2,{"d":3}],
"e":"success",
}
# 调用函数输出每个元素的取值路径
print_value_paths(test_data, "test_data")
# 示例字典数据
data = {
"a": 1,
"b": [
0,
1,
2,
{
"a": [1, 2, 4]
},
[5, 6]
]
}
print_value_paths(data, "data")
7、将所有路径输出到列表中:版本7(20210516修改)
def get_value_paths(data, path=""):
value_paths = []
if isinstance(data, dict):
for key, value in data.items():
value_paths.extend(get_value_paths(value, path + f'["{key}"]'))
elif isinstance(data, list):
for index, item in enumerate(data):
value_paths.extend(get_value_paths(item, path + f"[{index}]"))
else:
value_paths.append(f"{path} = {data}")
return value_paths
# 示例字典数据
data = {
"a": 1,
"b": [
0,
1,
2,
{
"a": [1, 2, 4]
},
[5, 6]
]
}
# 获取所有元素的取值路径列表
value_paths = get_value_paths(data, "data")
print(value_paths)
# # 输出所有元素的取值路径
# for value_path in value_paths:
# print(value_path)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











