






 本文介绍了一种使用3D卷积神经网络的唇语识别技术,通过视觉识别嘴唇动作并结合音频信息,实现高精度的视听语音识别。文章详细描述了输入数据的预处理过程、模型结构及训练方法。
本文介绍了一种使用3D卷积神经网络的唇语识别技术,通过视觉识别嘴唇动作并结合音频信息,实现高精度的视听语音识别。文章详细描述了输入数据的预处理过程、模型结构及训练方法。
导读
唇语识别有着极长的历史。古代的唇语师通过长期的训练,具备了“观察别人的嘴型,解读其表达语句”的能力。在现代社会里,一些听力障碍者们也会使用这种技巧与他人交谈,补充听力器官的不足。


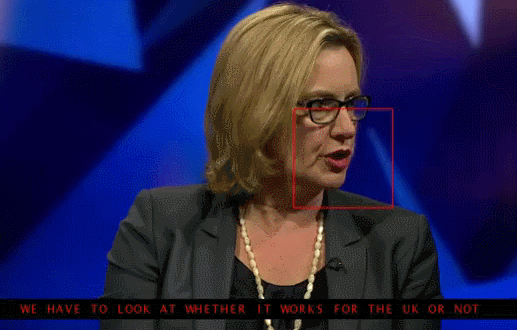
本期将将以Amirsina Torfi 等人实现的使用 3D 卷积神经网络的交叉视听识别技术为引,介绍唇语识别技术。
唇语识别
唇语识别/Lip ReadingGithub:github.com/astorfi/lip-reading-deeplearning
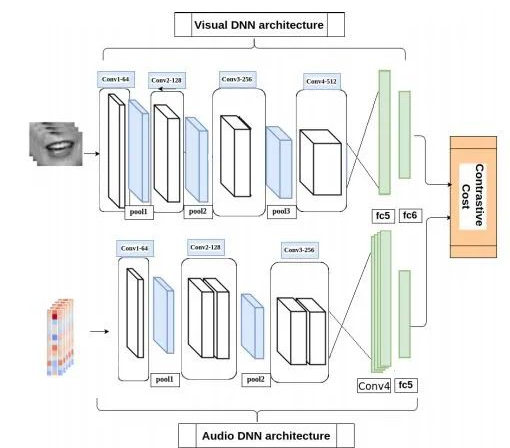
软件地址:暂无项目基于用于交叉视听匹配识别的3D卷积神经网络实现。模型结构如下图。模型具有以下四个特点:
- 输入是音频和视频,输出是他们是否匹配
- 标签是音频视频是否是一样的
- 衡量音频视频3D卷积后的低维映射之间的欧氏距离
- 两个重要的手段去掉多余数据
AVR 系统的方法是利用从某种模态中提取的信息,通过填补缺失的信息来提高另一种模态的识别能力。
这篇文章提出了利用耦合的三维卷积神经网络(CNN)架构,该架构可以将两种模态映射到表示空间,以使用学习到的多模态特征来评估音频 - 视频流的对应关系。
代码实现
输入管道必须由用户提供。其余实现将考虑包含基于话语的提取特征的数据集。 ▌唇语识别对于嘴唇跟踪,必须将所需的视频作为输入。首先,将cd转到相应的目录:cd code/lip_trackingpython VisualizeLip.py --input input_video_file_name.ext --output output_video_file_name.ext所需文件arguments由VisualizeLip.py文件中定义的以下python脚本定义:
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--input", required=True,
help="path to input video file")
ap.add_argument("-o", "--output", required=True,
help="path to output video file")
ap.add_argument("-f", "--fps", type=int, default=30,
help="FPS of output video")
ap.add_argument("-c", "--codec", type=str, default="MJPG",
help="codec of output video")
args = vars(ap.parse_args()一些已定义的参数具有其默认值,并且它们不需要进一步的操作。
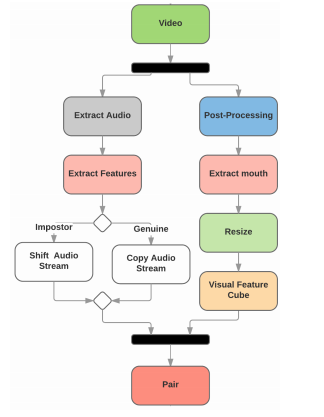
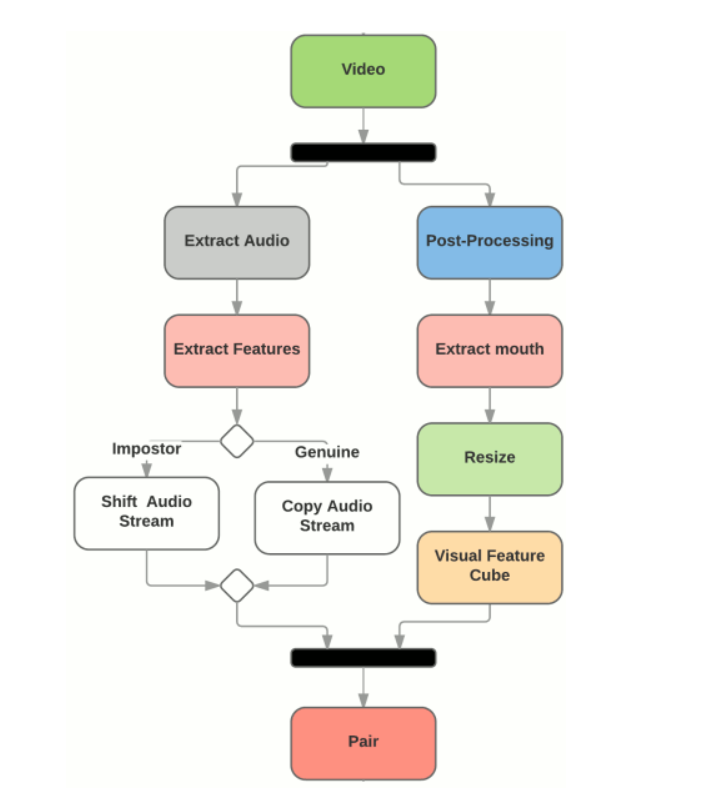
视觉部分,视频通过后期处理使其帧率相等,均为 30。然后,使用 dlib 库跟踪视频中的人脸和提取嘴部区域。最后,所有嘴部区域都调整为相同的大小,并拼接起来形成输入特征数据集。
数据集并不包含任何音频文件。使用 FFmpeg 框架从视频中提取音频文件。数据处理管道如下图所示:
所提出的体系结构利用了两个不同的ConvNet,它们使用一对语音和视频流。网络输入是一对特征,表示从0.3秒的视频剪辑中提取的嘴唇运动和语音特征。主要任务是确定音频流是否在所需的流持续时间内与嘴唇运动剪辑相对应。
语音网与视觉网
▌语音网络在时间轴上,时间特征是20ms的非重叠窗口,用于生成具有局部特征的频谱特征。输入语音特征图(表示为图像立方体)与频谱图以及MFEC特征的一阶和二阶导数相对应。
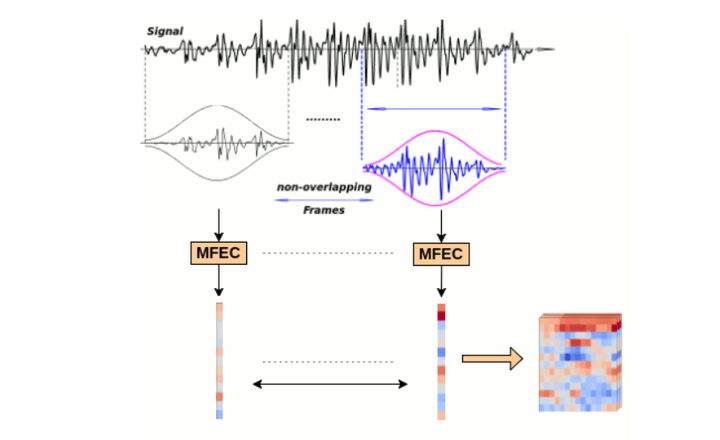
语音特征使用 SpeechPy 包进行提取。要了解输入管道是如何工作的,请参阅:
code/speech_input/input_feature.py在此过程中使用的每个视频剪辑的帧速率均为30。因此,9个连续的图像帧形成0.3秒的视觉流。网络可视流的输入是一个9x60x100大小的多维数据集,其中9是表示时间信息的帧数。每个通道都是嘴巴区域的60x100灰度图像。

训练与结果
▌训练与评估首先克隆存储库。然后cd到专用目录:
cd code/training_evaluationpython train.pypython test.py下面的结果表明了该方法对收敛准确度和收敛速度的影响。
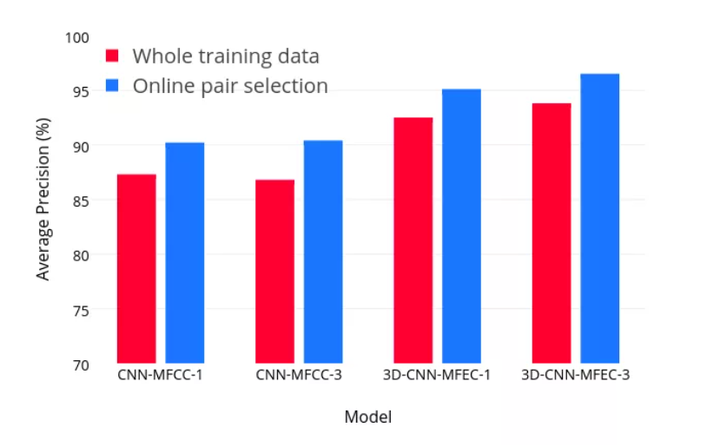
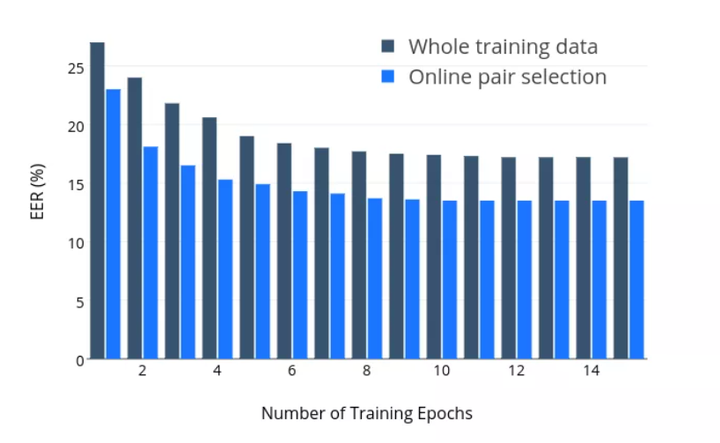

















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









