







去噪效果
训练集效果,未添加防止过拟合的措施
1 号井
| data | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|
| origin | 98.10 | 100.00 | 91.26 | 95.43 |
| denoised | 99.79 | 100.00 | 98.77 | 99.38 |
原始数据
AccuracyF 98.10 posLabel 19.87
precisionF 100.00 recallF 91.26 f1score 95.43
去噪后
AccuracyF 99.79 posLabel 16.91
precisionF 100.00 recallF 98.77 f1score 99.38
2 号井
| data | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|
| origin | 99.32 | 100.00 | 95.54 | 97.72 |
| denoised | 100.00 | 100.00 | 100.00 | 100.00 |
原始数据
AccuracyF 99.32 posLabel 14.56
precisionF 100.00 recallF 95.54 f1score 97.72
去噪后
AccuracyF 100.00 posLabel 10.07
precisionF 100.00 recallF 100.00 f1score 100.00
去噪确实能提高在训练集的拟合效果,但是不排除人为再次出错的情况。
去噪的方法待和甲方再讨论。
信息提取
去噪后 2 号井
讨论提取信息:连续未选用次数
从决策树结果发现,决策树的学习依赖于该提取信息。每一折分开训练,该提取信息也是极为重要。
(见大图)
是否有该信息模型的影响很大
提取:
k-fold f1 score:[0.81818182 0.64102564 0.7 ]
不提取:
k-fold f1 score:[0.47826087 0.28888889 0.37837838]
若去掉该提取信息,神经网络的效果会急剧下降。
| fold | train loss | valid loss | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|---|---|
| fold 1 | 0.000644 | 0.093264 | 94.29 | 85.71 | 31.58 | 46.15 |
| fold 2 | 0.001234 | 0.015579 | 97.96 | 100.00 | 85.71 | 92.31 |
| fold 3 | 0.000555 | 0.014028 | 96.73 | 75.00 | 90.00 | 81.82 |
********** fold 1 **********
train_loss:0.000644 train_acc:100.0000
valid loss:0.093264 valid_acc:94.2857
AccuracyF 94.29 posLabel 2.86
precisionF 85.71 recallF 31.58 f1score 46.15
********** fold 2 **********
train_loss:0.001234 train_acc:99.7959
valid loss:0.015579 valid_acc:97.9592
AccuracyF 97.96 posLabel 12.24
precisionF 100.00 recallF 85.71 f1score 92.31
********** fold 3 **********
train_loss:0.000555 train_acc:100.0000
valid loss:0.014028 valid_acc:96.7347
AccuracyF 96.73 posLabel 9.80
precisionF 75.00 recallF 90.00 f1score 81.82
删除提取信息:
| fold | train loss | valid loss | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|---|---|
| fold 1 | 0.013744 | 0.082324 | 91.43 | 0.00 | 0.00 | 0.00 |
| fold 2 | 0.007752 | 0.055746 | 86.53 | 57.14 | 22.86 | 32.65 |
| fold 3 | 0.012697 | 0.049911 | 90.61 | 38.46 | 25.00 | 30.30 |
********** fold 1 **********
train_loss:0.013744 train_acc:96.3265
valid loss:0.082324 valid_acc:91.4286
AccuracyF 91.43 posLabel 0.82
precisionF 0.00 recallF 0.00 f1score 0.00
********** fold 2 **********
train_loss:0.007752 train_acc:97.7551
valid loss:0.055746 valid_acc:86.5306
AccuracyF 86.53 posLabel 5.71
precisionF 57.14 recallF 22.86 f1score 32.65
********** fold 3 **********
train_loss:0.012697 train_acc:96.3265
valid loss:0.049911 valid_acc:90.6122
AccuracyF 90.61 posLabel 5.31
precisionF 38.46 recallF 25.00 f1score 30.30
数据分块实验
5 口井合并
未进行去噪处理。
计量数: 2532
k折交叉验证:
| fold | train loss | valid loss | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|---|---|
| fold 1 | 0.001003 | 0.015976 | 95.85 | 97.80 | 82.41 | 89.45 |
| fold 2 | 0.001422 | 0.009618 | 99.01 | 97.22 | 95.89 | 96.55 |
| fold 3 | 0.001092 | 0.001818 | 99.60 | 98.33 | 98.33 | 98.33 |
| fold 4 | 0.001101 | 0.006863 | 97.63 | 98.40 | 92.48 | 95.35 |
| fold 5 | 0.001015 | 0.021875 | 97.04 | 93.94 | 91.18 | 92.54 |
********** fold 1 **********
train_loss:0.001003 train_acc:99.9012
valid loss:0.015976 valid_acc:95.8498
AccuracyF 95.85 posLabel 17.98
precisionF 97.80 recallF 82.41 f1score 89.45
********** fold 2 **********
train_loss:0.001422 train_acc:99.8518
valid loss:0.009618 valid_acc:99.0119
AccuracyF 99.01 posLabel 14.23
precisionF 97.22 recallF 95.89 f1score 96.55
********** fold 3 **********
train_loss:0.001092 train_acc:99.9506
valid loss:0.001818 valid_acc:99.6047
AccuracyF 99.60 posLabel 11.86
precisionF 98.33 recallF 98.33 f1score 98.33
********** fold 4 **********
train_loss:0.001101 train_acc:99.8518
valid loss:0.006863 valid_acc:97.6285
AccuracyF 97.63 posLabel 24.70
precisionF 98.40 recallF 92.48 f1score 95.35
********** fold 5 **********
train_loss:0.001015 train_acc:99.9506
valid loss:0.021875 valid_acc:97.0356
AccuracyF 97.04 posLabel 19.57
precisionF 93.94 recallF 91.18 f1score 92.54
去噪后 2 号井
计量数: 735
问题:单井的计量数量少,导致分块时容易出现
在上次 实验 的基础上,去掉结果中差异最大的第一块数据,再作k折交叉验证:
| fold | train loss | valid loss | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|---|---|
| fold 1 | 0.000664 | 0.027481 | 93.25 | 100.00 | 42.11 | 59.26 |
| fold 2 | 0.000113 | 0.072901 | 92.02 | 100.00 | 58.06 | 73.47 |
| fold 3 | 0.001403 | 0.007569 | 97.55 | 57.14 | 80.00 | 66.67 |
********** fold 1 **********
train_loss:0.000664 train_acc:100.0000
valid loss:0.027481 valid_acc:93.2515
AccuracyF 93.25 posLabel 4.91
precisionF 100.00 recallF 42.11 f1score 59.26
********** fold 2 **********
train_loss:0.000113 train_acc:100.0000
valid loss:0.072901 valid_acc:92.0245
AccuracyF 92.02 posLabel 11.04
precisionF 100.00 recallF 58.06 f1score 73.47
********** fold 3 **********
train_loss:0.001403 train_acc:100.0000
valid loss:0.007569 valid_acc:97.5460
AccuracyF 97.55 posLabel 4.29
precisionF 57.14 recallF 80.00 f1score 66.67
2折交叉验证(相当于相互验证,效果劣于整体作k折验证,因为数据又减少了)
| fold | train loss | valid loss | AccuracyF | precisionFn | recallFn | f1-score |
|---|---|---|---|---|---|---|
| fold 1 | 0.001571 | 0.038718 | 91.84 | 94.12 | 45.71 | 61.54 |
| fold 2 | 0.002663 | 0.021147 | 95.10 | 70.00 | 70.00 | 70.00 |
********** fold 1 **********
train_loss:0.001571 train_acc:100.0000
valid loss:0.038718 valid_acc:91.8367
AccuracyF 91.84 posLabel 6.94
precisionF 94.12 recallF 45.71 f1score 61.54
********** fold 2 **********
train_loss:0.002663 train_acc:100.0000
valid loss:0.021147 valid_acc:95.1020
AccuracyF 95.10 posLabel 8.16
precisionF 70.00 recallF 70.00 f1score 70.00
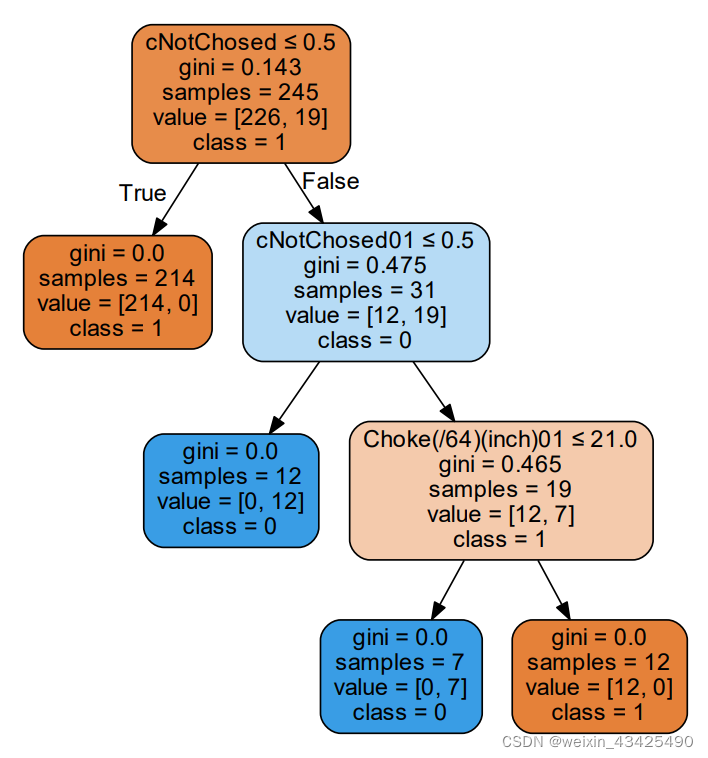
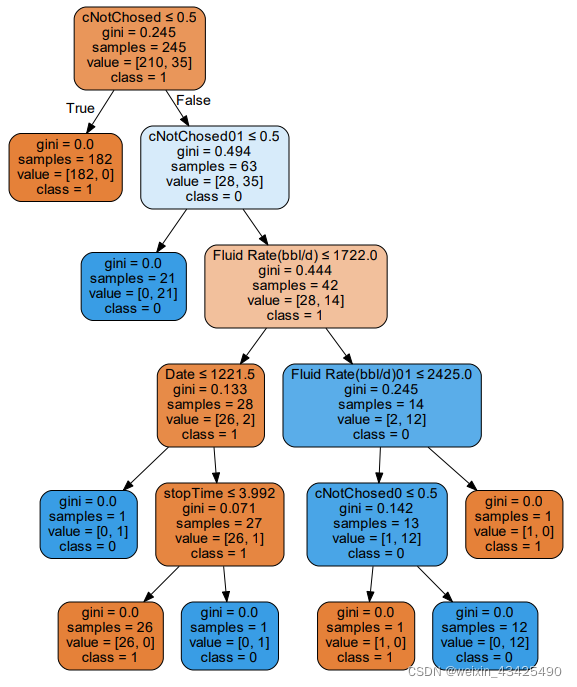
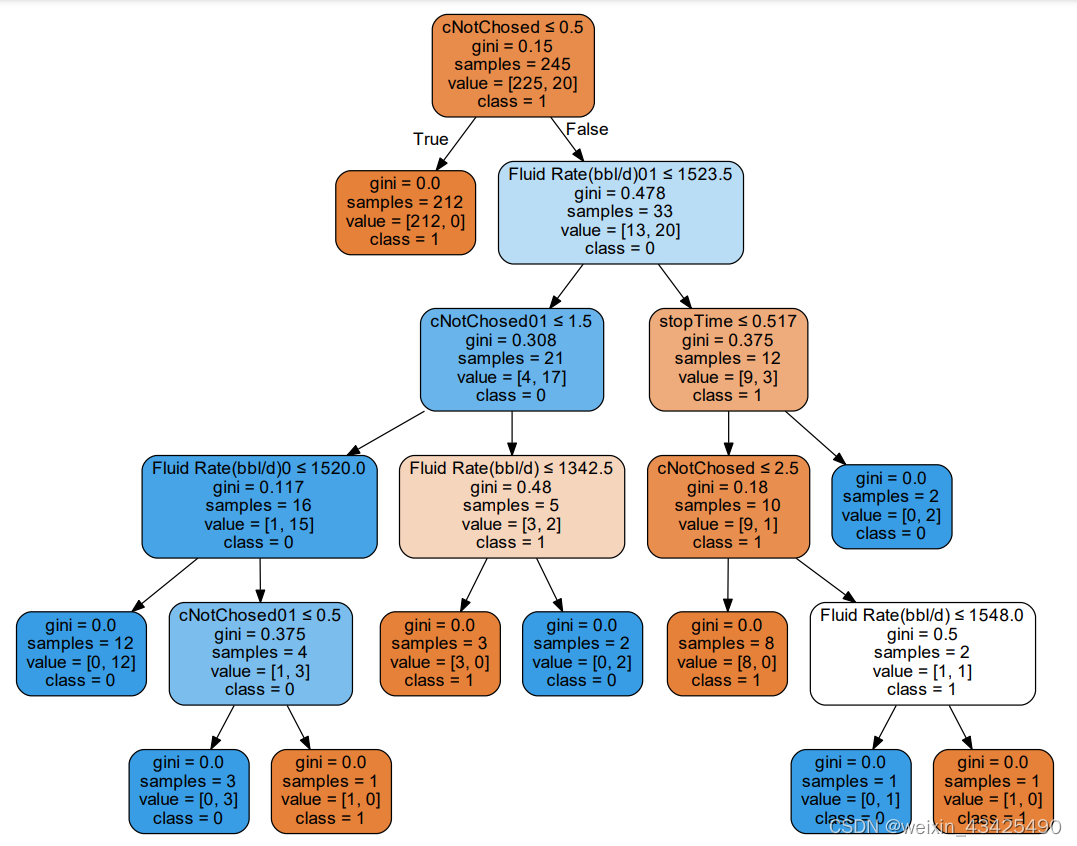
对每一块数据生成的决策树:
下一步工作
1.机器去噪是否可行?
2.迁移学习
3.
老板的笔记
实验观察的三个层次:
- 顶层,如测试精度。可以通过最终结果来观察。相当于系统测试。
- 中层,如:把数据分成几块,分别计算:
a) 训练集中的精度、召回率等,知道模型的拟合能力,这是一个基本保障。如果这个效果不好,就表示数据质量不好,无法保证内部的一致性;
b) 用一块训练,另一块测试,获取精度、召回率等。如果这个不好,就表示分布不同;
c) 用 k - 1 块训练,另一块测试,获取精度、召回率等。如果这个不好,就表示这一块与其它的分布不同;
d) 生成决策树等具有可读性的模型,比较不同数据块获得的模型;
相当于集成测试。 - 底层,对单个的样例分类。可以通过跟踪调拭来观察。相当于单元测试。
总之,要进行具体问题的定位。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









