







 本文详细探讨了Python中的变量与常量。介绍了标识符与对象的关系,包括创建、命名规范和绑定映射。讲解了Python的变量概念,强调其引用传递特性,并对比了与其他语言的不同。此外,文章还讨论了匿名变量和常量的使用,以及相关的方法如id()、type()和del。
本文详细探讨了Python中的变量与常量。介绍了标识符与对象的关系,包括创建、命名规范和绑定映射。讲解了Python的变量概念,强调其引用传递特性,并对比了与其他语言的不同。此外,文章还讨论了匿名变量和常量的使用,以及相关的方法如id()、type()和del。
标识符与对象
在Python中有一个核心的概念,叫做一切皆对象。
我们定义的数据、资源等皆可称之为对象,对象均存放在内存中。
而如果要使用这个对象,则必须通过标识符与对象进行绑定,说的通俗一点就是,为对象取一个名字。
一般来讲,一次绑定分为三部分操作:
- 创建资源对象(值)
- 创建标识符(名字)
- 建立绑定关系(赋值符号)
如下所示:
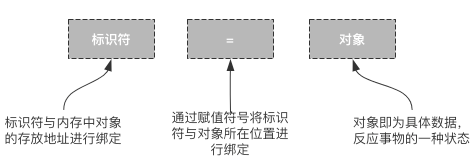
整个绑定的过程,被称为常量\变量赋值或者对象定义,用=号将标识符与对象进行链接。
如下所示,我们用多个对象表示一个人的信息:
name = "yunya"
age = 18
height = 1.92
print("name : %s\nage : %s\nheight : %s\n" % (name, age, height))
# name : yunya
# age : 18
# height : 1.92
先定义后使用
对象必须先定义,后使用,如果未定义就使用则会抛出异常。
print("My name is :", name)
name = "yunya"
# NameError: name 'name' is not defined
命名风格
下面介绍几种常用的标识符命名方式:
-
Camel-Case之小驼峰式:个人比较喜欢的风格,但是Python中并不建议使用小驼峰。
单词开头的字母小写,而后每个单词的分割首字母采用大写形式:
userAge = 18 -
Camel-Case之大驼峰式:大驼峰式在Python中比较常见,一般定义类名时使用,不要滥用大驼峰。
每个单词都首字母都大写
UserInfo = {} -
匈牙利类型标记法:前面的小写字母为变量类型,如,i代表int类型、s代表str类型:
iUserAge = 18 -
蛇形命名法:小写+下划线,是Python中更推荐使用的标识符命名方式:
user_age = 18
命名规范
标识符的命名需要遵从以下规范:
标识符应当见名知意
标识符由数字,字母,下划线组成。并且开头不能为数字
标识符不能使用Python中的关键字
错误的示范:
$name = 'yunya' # 具有特殊字符
1year = 365 # 数字开头
*_size = 1024 # 具有特殊字符
and = 123 # 使用了关键字
年级 = 3 # 强烈不建议使用中文(占用内存大)
(color) = 'red' # 虽然这种命名方式可行但是也极为不推荐
正确的示范:
name = 'yunya'
__age = 18 # Python中双下划线开头的标识符一般有隐私的这种说法,因此一般不建议使用
page_1 = 'home page'
同时,个人十分不推荐在标识符中加上任何的数字,这样的做法显得很莽撞。如item1,item2等…
绑定映射
Python中所有的数据均被称之为对象(object),对象存放至堆(heap)区内存中。
在对象存入堆区内存时,会为对象开辟一块内存空间并保存。
而在栈(stack)区内存中,则存放对象的引用(reference),即对象在堆区内存中的地址。
当一个对象被赋值给一个标识符后,在栈区内存中会创建一种映射(mapping)关系,此时标识符和对象就建立了联系,并且标识符本身也会被存放至栈区内存中。
name = "yunya"
age = 18
height = 1.92
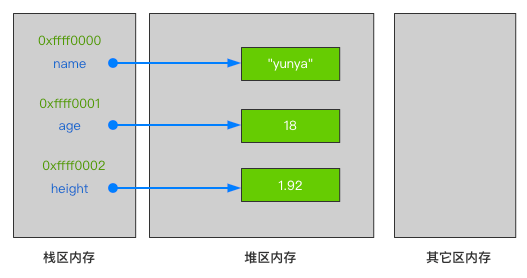
盒子声明
在很多其他的编程语言中,声明一个数据的过程可以被称作盒子声明,当遇到赋值操作时,它会进行如下的流程:
- 创建一个具体的盒子(开辟内存,创建盒子,并且为盒子打上标识)
- 放入具体的数据(将对象放入盒子中)
而在Python中,则没有盒子声明这种说法,我更喜欢将它称作贴纸声明,当遇到赋值操作时,它会进行如下的流程:
- 先创建一个对象(自动的在遇到=符号时,开辟内存并创建对象,如果该对象已存在,则进行引用)
- 将=符号左侧的标识符与对象绑定(像贴纸一样)
两者对比一下:
- 其他编程语言中总是先进行标识符盒子的初始化,再之后将数据对象放入盒子中
- Python中总是先创建对象,并且再将标识符与对象做绑定
如下图所示:
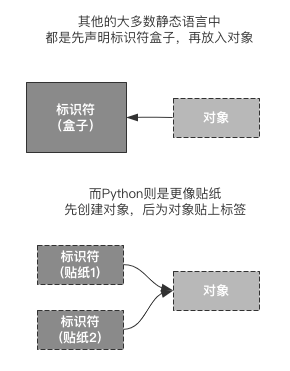
引用传递
Python中所有的标识符与对象的绑定均为引用,不论是函数传参,单纯赋值等,标识符都与对象的内存地址做绑定,而不和对象本身的值做绑定。
Python中一个对象可以被多个标识符所引用,而一个标识符仅能引用一个对象。
你可以理解为Python中所有数据类型均为引用类型,没有值类型。
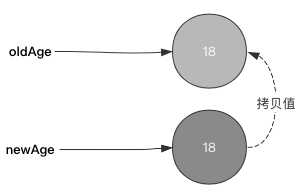
如下所示,我们将声明2个不同的标识符,标识符都指向了同一个int对象:
oldAge = 18
newAge = oldAge
print(id(oldAge))
print(id(newAge))
# 4550527568
# 4550527568
如下图所示:
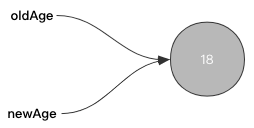
在Golang中,如果进行上面的操作,因为盒子声明的缘故新的标识符newAge会创建出一片新的内存空间,并且将oldAge的值进行一次拷贝后存放至新内存空间中:
package main
import "fmt"
func main() {
var oldAge int = 18
var newAge int = oldAge
fmt.Println(oldAge, &oldAge)
fmt.Println(newAge, &newAge)
}
// 18 0xc42008e168
// 18 0xc42008e190
如下图所示:
变量
变量指的是该标识符所绑定的对象允许在运行时刻发生变化,是用来记录事物变化状态的一种东西。
举个例子:
- 进入游戏:等级为0
- 一天之后:等级为10
- 一月之后:等级为100
标识符(等级)与表示等级的对象所绑定,并且该等级在不断的变化,那么这个标识符可以称为变量标识符,与变量标识符绑定的对象是可以随意改变的:
# 进入游戏
level = 0
# 一天后
level = 10
# 一月后
level = 100
# 现在的等级
print(level)
# 100
变量命名
变量标识符的命名一般以蛇形命名法和小驼峰命名法为准。
不可使用大驼峰式命名法,同时全大写命名法也不要进行使用。
匿名变量
如果一个变量标识符为_,则代表该变量为匿名变量。
匿名变量的作用是当做一个垃圾桶,对于一些不会用到的对象可以命名为_,仅做到一个占位的作用,这在解构赋值中经常会被使用到。
其实官方没有匿名变量的定义,这也是Python社区中一条不成文的规定,因为实在是懒得对一个不用的对象想名字,干脆就用_进行命名。
常量
常量指的是该标识符所绑定的对象不允许在运行时刻发生变化,表示一个恒定的数据。
举个例子:
- 圆周率PI是恒定的,不能因为程序的运行而改变
- 人的性别是恒定的,不能因为程序的运行而改变
很遗憾,在应用领域来说Python并未提供常量的定义,但是在Python社区中有一个不成文的规定。
如果一个标识符所有字母都是大写的话,则认为该标识符是常量标识符:
PI = 3.1415926535897
SEX = "男"
常量池
上面说过,尽管在应用领域中Python并未提供常量的定义,但是在内部实现中处处可见常量的影子。
如小整数常量池就是一个很好的例子。
在其他的编程语言,类似Golang、JavaScript中,常量定义的关键词为const,很快你也会在Python中见到这个单词。
相关方法
id()
使用id()函数可拿到标识符所对应对象在堆区内存中的地址号。
name = "yunya"
print(id(name))
# 2933298725640
type()
使用type()函数可获取到该标识符对应对象的数据类型,返回类本身。
name = "yunya"
print(type(name))
# <class 'str'>
del
使用del跟上标识符名字,将对该标识符所关联的对象进行解绑操作,同时也会取消该标识符的定义,将其从栈区内存中抹去。
name = "yunya"
del name
print(name)
# NameError: name 'name' is not defined


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









