







一、理论基础
Inception v3由谷歌研究员Christian Szegedy等人在2015年的论文《Rethinking the Inception Architecture for Computer Vision》中提出。Inception v3是Inception网络系列的第三个版本,它在ImageNet图像识别竞赛中取得了优异成绩,尤其是在大规模图像识别任务中表现出色。
对比Inception v1
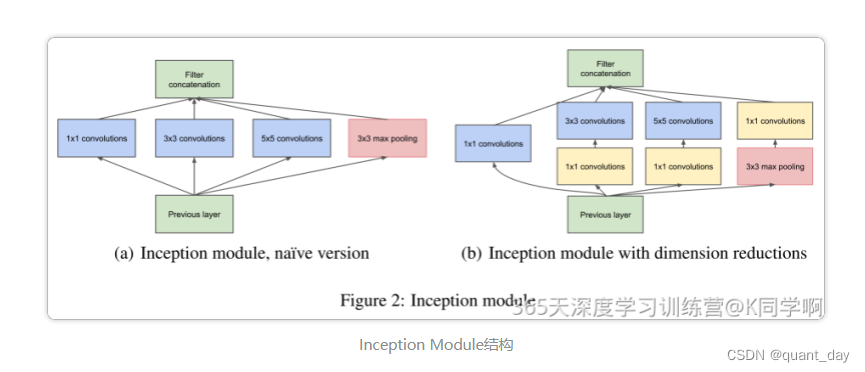
先看Inception v3做了以下改动:
①
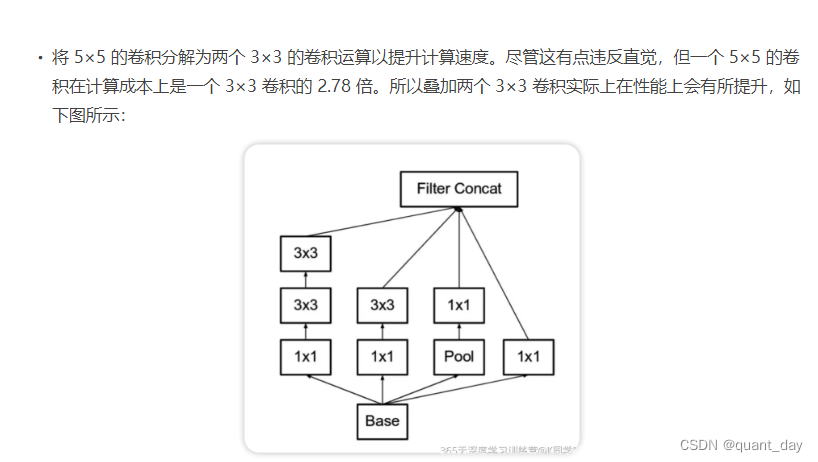
②

③
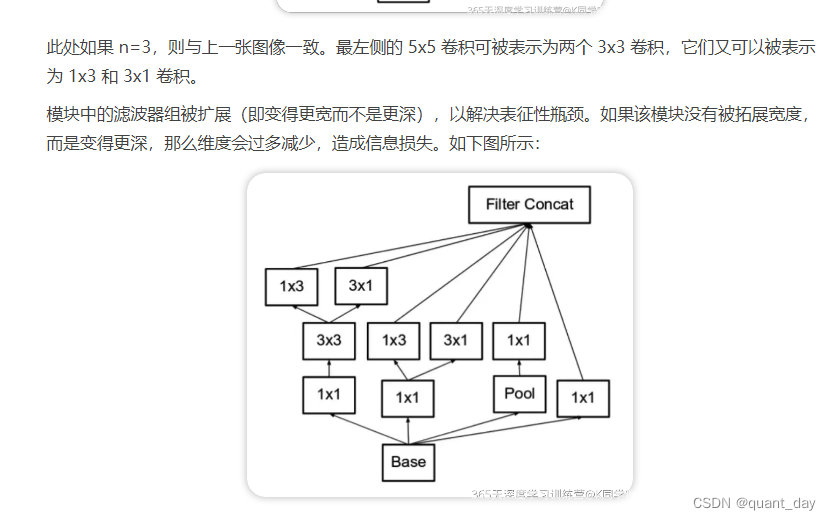
完整的框架为
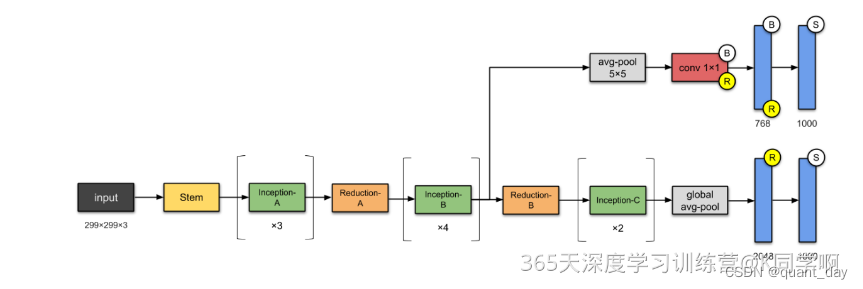
二、改动的实现
我们把① 称为InceptionA
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1) # 1
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)结构以下称为InceptionB
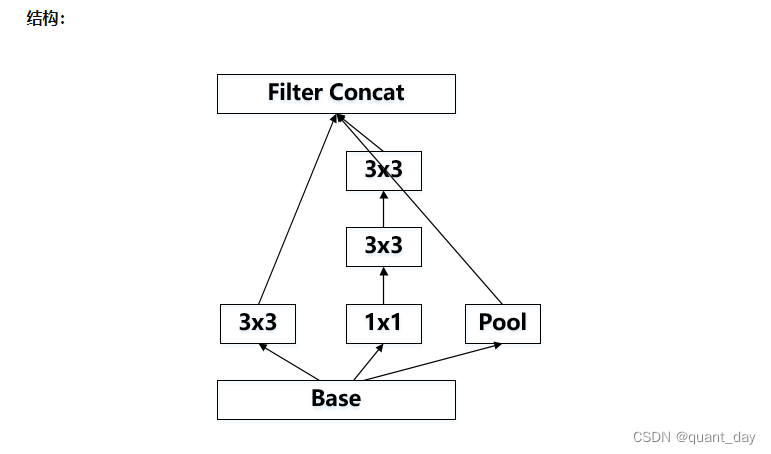
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)②称为InceptionC
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)结构以下称为InceptionD
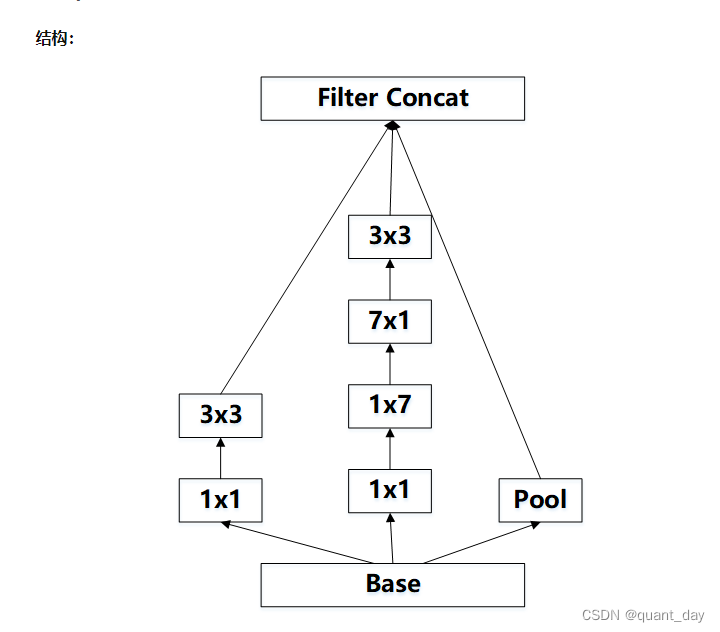
class InceptionD(nn.Module):
def __init__(self, in_channels):
super(InceptionD, self).__init__()
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return torch.cat(outputs, 1)③称为InceptionE
class InceptionE(nn.Module):
def __init__(self, in_channels):
super(InceptionE, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)三、完整的Inception v3
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class GoogleNet_v3_Model(nn.Module):
def __init__(self, num_classes=1000, init_weights=True):
super(GoogleNet_v3_Model, self).__init__()
self.Conv2d_1a_3x3 = BasicConv2d(3, 32, kernel_size=3, stride=2)
self.Conv2d_2a_3x3 = BasicConv2d(32, 32, kernel_size=3)
self.Conv2d_2b_3x3 = BasicConv2d(32, 64, kernel_size=3, padding=1)
self.Conv2d_3b_1x1 = BasicConv2d(64, 80, kernel_size=1)
self.Conv2d_4a_3x3 = BasicConv2d(80, 192, kernel_size=3)
self.Mixed_5b = InceptionA(192, pool_features=32)
self.Mixed_5c = InceptionA(256, pool_features=64)
self.Mixed_5d = InceptionA(288, pool_features=64)
self.Mixed_6a = InceptionB(288)
self.Mixed_6b = InceptionC(768, channels_7x7=128)
self.Mixed_6c = InceptionC(768, channels_7x7=160)
self.Mixed_6d = InceptionC(768, channels_7x7=160)
self.Mixed_6e = InceptionC(768, channels_7x7=192)
self.Mixed_7a = InceptionD(768)
self.Mixed_7b = InceptionE(1280)
self.Mixed_7c = InceptionE(2048)
self.fc = nn.Sequential(nn.Linear(2048, num_classes),
nn.Softmax(dim=1))#nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
# 299 x 299 x 3
x = self.Conv2d_1a_3x3(x)
# 149 x 149 x 32
x = self.Conv2d_2a_3x3(x)
# 147 x 147 x 32
x = self.Conv2d_2b_3x3(x)
# 147 x 147 x 64
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 73 x 73 x 64
x = self.Conv2d_3b_1x1(x)
# 73 x 73 x 80
x = self.Conv2d_4a_3x3(x)
# 71 x 71 x 192
x = F.max_pool2d(x, kernel_size=3, stride=2)
# 35 x 35 x 192
x = self.Mixed_5b(x)
# 35 x 35 x 256
x = self.Mixed_5c(x)
# 35 x 35 x 288
x = self.Mixed_5d(x)
# 35 x 35 x 288
x = self.Mixed_6a(x)
# 17 x 17 x 768
x = self.Mixed_6b(x)
# 17 x 17 x 768
x = self.Mixed_6c(x)
# 17 x 17 x 768
x = self.Mixed_6d(x)
# 17 x 17 x 768
x = self.Mixed_6e(x)
# 17 x 17 x 768
x = self.Mixed_7a(x)
# 8 x 8 x 1280
x = self.Mixed_7b(x)
# 8 x 8 x 2048
x = self.Mixed_7c(x)
# 8 x 8 x 2048
x = F.avg_pool2d(x, kernel_size=8)
# 1 x 1 x 2048
x = F.dropout(x, training=self.training)
# 1 x 1 x 2048
x = x.view(x.size(0), -1)
# 2048
x = self.fc(x)
# 1000 (num_classes)
return x
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features):
super(InceptionA, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1) # 1
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionB(nn.Module):
def __init__(self, in_channels):
super(InceptionB, self).__init__()
self.branch3x3 = BasicConv2d(in_channels, 384, kernel_size=3, stride=2)
self.branch3x3dbl_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = BasicConv2d(96, 96, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3(x)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionC(nn.Module):
def __init__(self, in_channels, channels_7x7):
super(InceptionC, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 192, kernel_size=1)
c7 = channels_7x7
self.branch7x7_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7_2 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7_3 = BasicConv2d(c7, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_1 = BasicConv2d(in_channels, c7, kernel_size=1)
self.branch7x7dbl_2 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_3 = BasicConv2d(c7, c7, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7dbl_4 = BasicConv2d(c7, c7, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7dbl_5 = BasicConv2d(c7, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch7x7 = self.branch7x7_1(x)
branch7x7 = self.branch7x7_2(branch7x7)
branch7x7 = self.branch7x7_3(branch7x7)
branch7x7dbl = self.branch7x7dbl_1(x)
branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
return torch.cat(outputs, 1)
class InceptionD(nn.Module):
def __init__(self, in_channels):
super(InceptionD, self).__init__()
self.branch3x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch3x3_2 = BasicConv2d(192, 320, kernel_size=3, stride=2)
self.branch7x7x3_1 = BasicConv2d(in_channels, 192, kernel_size=1)
self.branch7x7x3_2 = BasicConv2d(192, 192, kernel_size=(1, 7), padding=(0, 3))
self.branch7x7x3_3 = BasicConv2d(192, 192, kernel_size=(7, 1), padding=(3, 0))
self.branch7x7x3_4 = BasicConv2d(192, 192, kernel_size=3, stride=2)
def forward(self, x):
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch7x7x3 = self.branch7x7x3_1(x)
branch7x7x3 = self.branch7x7x3_2(branch7x7x3)
branch7x7x3 = self.branch7x7x3_3(branch7x7x3)
branch7x7x3 = self.branch7x7x3_4(branch7x7x3)
branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)
outputs = [branch3x3, branch7x7x3, branch_pool]
return torch.cat(outputs, 1)
class InceptionE(nn.Module):
def __init__(self, in_channels):
super(InceptionE, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 320, kernel_size=1)
self.branch3x3_1 = BasicConv2d(in_channels, 384, kernel_size=1)
self.branch3x3_2a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3_2b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch3x3dbl_1 = BasicConv2d(in_channels, 448, kernel_size=1)
self.branch3x3dbl_2 = BasicConv2d(448, 384, kernel_size=3, padding=1)
self.branch3x3dbl_3a = BasicConv2d(384, 384, kernel_size=(1, 3), padding=(0, 1))
self.branch3x3dbl_3b = BasicConv2d(384, 384, kernel_size=(3, 1), padding=(1, 0))
self.branch_pool = BasicConv2d(in_channels, 192, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3_1(x)
branch3x3 = [
self.branch3x3_2a(branch3x3),
self.branch3x3_2b(branch3x3),
]
branch3x3 = torch.cat(branch3x3, 1)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = [
self.branch3x3dbl_3a(branch3x3dbl),
self.branch3x3dbl_3b(branch3x3dbl),
]
branch3x3dbl = torch.cat(branch3x3dbl, 1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)四、运行代码
运行代码参考
深度学习-第J8周:Inception v1算法实战与解析_quant_day的博客-优快云博客
if __name__=='__main__':
early_stop=10
epochs = 100
model = GoogleNet_v3_Model(num_classes=N_classes, init_weights=True)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.0001)
model, record = train_and_test(model, loss_func, optimizer, epochs, early_stop)
torch.save(model.state_dict(), './Best_GoogleNet_V3.pth')
record = np.array(record)
plt.plot(record[:, 0:2])
plt.legend(['Train Loss', 'Valid Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1.5)
plt.savefig('Loss_V3_J3_1.png')
plt.show()
plt.plot(record[:, 2:4])
plt.legend(['Train Accuracy', 'Valid Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig('Accuracy_V3_J3_1.png')
plt.show()运行结果如下:
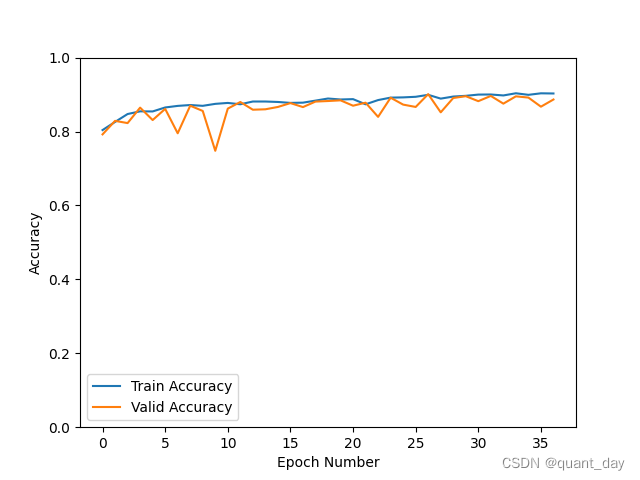
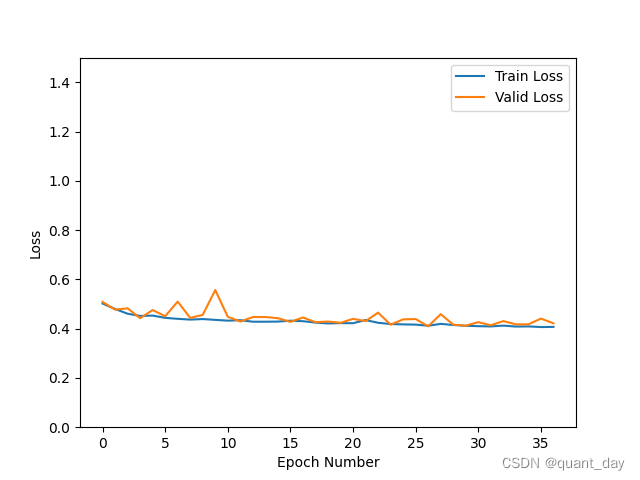


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









