




 本文详细介绍了HTTP请求的基本结构、常用方法及GET与POST的区别。解析了关键HTTP头部信息,如User-Agent和Content-Type的作用,以及常见状态码的含义,如301、302和401等。同时对比了强缓存与协商缓存的不同,阐述了Cookie属性及跨域问题的解决方案。
本文详细介绍了HTTP请求的基本结构、常用方法及GET与POST的区别。解析了关键HTTP头部信息,如User-Agent和Content-Type的作用,以及常见状态码的含义,如301、302和401等。同时对比了强缓存与协商缓存的不同,阐述了Cookie属性及跨域问题的解决方案。
目录:
- 1、请描述一下http的请求的报文结构
- 2、http的请求行由哪几部分构成
- 3、写出常用的http method
- 4、GET请求和POST请求的区别
- 5、请解释下面的http header的含义
- 6、请写出常见的POST提交数据的方式(即content-type)
- 7、状态码301和302有什么区别
- 8、状态码304什么意思
- 9、状态码307/308与302/301的主要区别是什么
- 10、状态码401和403分别表示什么意思
- 11、Response中用于标注字符编码的header是下面哪个?
- 12、哪两个header用于定义强缓存
- 13、哪两组header用户定义协商缓存
- 14、强缓存和协商缓存有什么区别
- 15、cookie有哪些属性
- 16、什么时候会发options请求
- 17、跨域问题是怎么产生的,如何解决跨域问题
- 18、如果header中的外部css尚未加载完毕,它后面的js先请求回来了,会执行吗?
- 19、CSS是否会阻塞DOM渲染
- 20、Script中的async和defer属性有什么区别
1、请描述一下http的请求的报文结构
请求行、请求头、空行、请求体

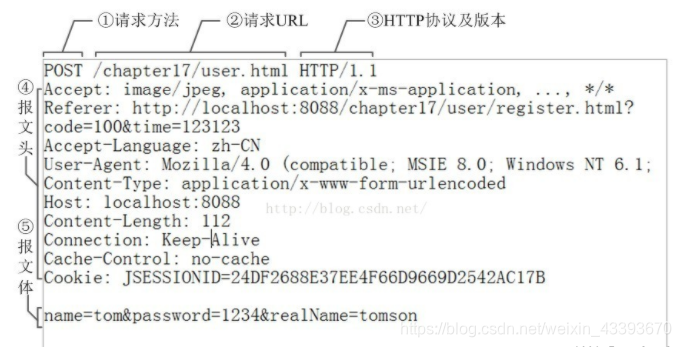
同样的,HTTP响应报文也由三部分组成:响应行、响应头、响应体

2、http的请求行由哪几部分构成
请求方法 URL 协议版本 回车符 换行符(\r\n)
3、写出常用的http method
get post head put delete trance connect
GET:请求一个指定资源的表示形式,使用get的请求应该是被用于获取数据
POST:用于将实体提交到指定的资源,通常导致在服务器上的状态的变化或者副作用
HEAD:请求一个与get请求相同的响应,但是没有响应体;
PUT:用于请求有效载荷替换目标资源的所有当前表示
DELETE:删除指定的资源
TRACE:沿着到目标资源的路径执行一个消息环回测试
CONNECT:建立一个到由目标资源标识的服务器的隧道
PATCH:用于对资源应用部分修改
4、GET请求和POST请求的区别
get请求指定的页面信息,并返回请求体;post向指定资源提交数据进行请求,数据被包含在请求体中,post请求可能会导致新的资源的建立/或已有资源的修改
5、请解释下面的http header的含义
-User-Agent:是http协议中的一部分,属于头域的组成部分,简称UA。用较为普通的一点来说,是一种向访问网站提供你所使用的浏览器的类型、操作系统版本、CPU类型、浏览器渲染引擎、浏览器语言、浏览器插件等信息的标识。UA字符串每次在浏览器HTTP请求的时候发送到服务器
-Content-Type:内容类型,一般是指网页中存在的Content-type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式,什么编码读取这个文件,这就是经常看到一些PHP网页点击的结果却是下载一个文件或者一张图片的原因。Content-type的标头告诉客户端实际返回的内容的内容类型。
-User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36
Content-type:
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
为什么浏览器User-agent总是有Mozilla字样:
你是否好奇标识浏览器身份的User-Agent,为什么每个浏bai览器都有Mozilla字样?
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36
Mozilla/5.0 (Linux; U; Android 4.1.2; zh-tw; GT-I9300 Build/JZO54K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
Mozilla/5.0 (Windows NT 6.1; WOW64; rv:20.0) Gecko/20100101 Firefox/20.0
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0; Trident/5.0)
故事还得从头说起,最初的主角叫NCSA Mosaic,简称Mosaic(马赛克),是1992年末位于伊利诺伊大学厄巴纳-香槟分校的国家超级计算机应用中心(National Center for Supercomputing Applications,简称NCSA)开发,并于1993年发布的一款浏览器。它自称“NCSA_Mosaic/2.0(Windows 3.1)”,Mosaic可以同时展示文字和图片,从此浏览器变得有趣多了。
然而很快就出现了另一个浏览器,这就是著名的Mozilla,中文名称摩斯拉。一说 Mozilla = Mosaic + Killer,意为Mosaic杀手,也有说法是 Mozilla = Mosaic & Godzilla,意为马赛克和哥斯拉,而Mozilla最初的吉祥物是只绿色大蜥蜴,后来更改为红色暴龙,跟哥斯拉长得一样。
但Mosaic对此非常不高兴,于是后来Mozilla更名为Netscape,也就是网景。Netscape自称“Mozilla/1.0(Win3.1)”,事情开始变得更加有趣。网景支持框架(frame),由于大家的喜欢框架变得流行起来,但是Mosaic不支持框架,于是网站管理员探测user agent,对Mozilla浏览器发送含有框架的页面,对非Mozilla浏览器发送没有框架的页面。
后来网景拿微软寻开心,称微软的Windows是“没有调试过的硬件驱动程序”。微软很生气,后果很严重。此后微软开发了自己的浏览器,这就是Internet Explorer,并希望它可以成为Netscape Killer。IE同样支持框架,但它不是Mozilla,所以它总是收不到含有框架的页面。微软很郁闷很快就沉不住气了,它不想等到所有的网站管理员都了解IE并且给IE发送含有框架的页面,它选择宣布IE是兼容Mozilla,并且模仿Netscape称IE为“Mozilla/1.22(compatible; MSIE 2.0; Windows 95)”,于是IE可以收到含有框架的页面了,所有微软的人都嗨皮了,但是网站管理员开始晕了。
因为微软将IE和Windows捆绑销售,并且把IE做得比Netscape更好,于是第一次浏览器血腥大战爆发了,结果是Netscape以失败退出历史舞台,微软更加嗨皮。但没想到Netscape居然以Mozilla的名义重生了,并且开发了Gecko,这次它自称为“Mozilla/5.0(Windows; U; Windows NT 5.0; en-US; rv:1.1) Gecko/20020826”。
Gecko是一款渲染引擎并且很出色。Mozilla后来变成了Firefox,并自称“Mozilla/5.0 (Windows; U; Windows NT 5.1; sv-SE; rv:1.7.5) Gecko/20041108 Firefox/1.0”。Firefox性能很出色,Gecko也开始攻城略地,其他新的浏览器使用了它的代码,并且将它们自己称为“Mozilla/5.0 (Macintosh; U; PPC Mac OS X Mach-O; en-US; rv:1.7.2) Gecko/20040825 Camino/0.8.1”,以及“Mozilla/5.0 (Windows; U; Windows NT 5.1; de; rv:1.8.1.8) Gecko/20071008 SeaMonkey/1.0”,每一个都将自己装作Mozilla,而它们全都使用Gecko。
Gecko很出色,而IE完全跟不上它,因此user agent探测规则变了,使用Gecko的浏览器被发送了更好的代码,而其他浏览器则没有这种待遇。Linux的追随者对此很难过,因为他们编写了Konqueror,它的引擎是KHTML,他们认为KHTML和Gecko一样出色,但却因为不是Gecko而得不到好的页面,于是Konqueror为得到更好的页面开始将自己伪装成“like Gecko”,并自称为“Mozilla/5.0 (compatible; Konqueror/3.2; FreeBSD) (KHTML, like Gecko)”。自此user agent变得更加混乱。
这时更有Opera跳出来说“毫无疑问,我们应该让用户来决定他们想让我们伪装成哪个浏览器。”于是Opera干脆创建了菜单项让用户自主选择让Opera浏览器变成“Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.51”,或者“Mozilla/5.0 (Windows NT 6.0; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.51”, 或者“Opera/9.51 (Windows NT 5.1; U; en)”。
后来苹果开发了Safari浏览器,并使用KHTML作为渲染引擎,但苹果加入了许多新的特性,于是苹果从KHTML另辟分支称之为WebKit,但它又不想抛弃那些为KHTML编写的页面,于是Safari自称为“Mozilla/5.0 (Macintosh; U; PPC Mac OS X; de-de) AppleWebKit/85.7 (KHTML, like Gecko) Safari/85.5”,这进一步加剧了user agent的混乱局面。
因为微软十分忌惮Firefox,于是IE重装上阵,这次它自称为“Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0) ”,并且渲染效果同样出色,但是需要网站管理员的指令它这么做才行。
再后来,谷歌开发了Chrome浏览器,Chrome使用Webkit作为渲染引擎,和Safari之前一样,它想要那些为Safari编写的页面,于是它伪装成了Safari。于是Chrome使用WebKit,并将自己伪装成Safari,WebKit伪装成KHTML,KHTML伪装成Gecko,最后所有的浏览器都伪装成了Mozilla,这就是为什么所有的浏览器User-Agent里都有Mozilla。Chrome自称为“Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13”。
因为以上这段历史,现在的User-Agent字符串变得一团糟,几乎根本无法彰显它最初的意义。追根溯源,微软可以说是这一切的始作俑者,但后来每一个人都在试图假扮别人,最终把User-Agent搞得混乱不堪。
一句话结论:因为网站开发者可能会因为你是某浏览器(这里是 Mozilla),所以输出一些特殊功能的程序代码(这里指好的特殊功能),所以当其它浏览器也支持这种好功能时,就试图去模仿 Mozilla 浏览器让网站输出跟 Mozilla 一样的内容,而不是输出被阉割功能的程序代码。大家都为了让网站输出最好的内容,都试图假装自己是 Mozilla 一个已经不存在的浏览器……
附各大浏览器诞生年表:
1993年1月23日:Mosaic
1994年12月:Netscape
1994年:Opera
1995年8月16日:Internet Explorer
1996年10月14日:Kongqueror
2003年1月7日:Safari
2008年9月2日:Chrome
注:本文转自简明现代魔法。
6、请写出常见的POST提交数据的方式(即content-type)
1:application/x-www-form-urlencoded
2:multipart/form-data
3:application/json
4:text/xml
7、状态码301和302有什么区别
301:资源永久的被转移到别的URL
302:请求的资源现在临时的从不同的URL中响应请求
区别:301表示搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;302表示旧地址A资源还在(仍可以访问),这个重定向只是临时的旧地址A调转到地址B,搜索引擎会抓取新的内容而保存旧的网址
8、状态码304什么意思
客户端已经执行了get,但是资源未发生改变(3xx中唯一一个跟重定向没有关系的)
9、状态码307/308与302/301的主要区别是什么
301: 永久移动
302:要求客户端临时重定向
307:要求客户端临时重定向
308:永久移动
区别:301、302是http1.0的行为,303、307、308是http1.1行为;
301和302是允许重定向时改变请求方法的(将post改为get),307/308是不允许重定向时改变请求方法的。
10、状态码401和403分别表示什么意思
401:请求要求用户进行身份认证,没有token
403:服务器理解客户端的请求,但是拒绝执行,没有权限
11、Response中用于标注字符编码的header是下面哪个?
答案:A
A: Content-TypeB: Content-Encoding(压缩编码)
C: Content-Langurage
D: Content-Length
12、哪两个header用于定义强缓存
Exprie
Catch-control: 优先级高于 expires。
Exprie:一个未来时间,代表请求有效日期,没有过期之前都使用当前请求
Catch-control:
value 是一个时间段,请求有效的最大时间段,限制:1.需要记住请求时间还需要计算是否在这个时间段内 2. 服务器与客户端时间必须一致。
因为它是一个时间段,所以意味着,可以设置一些默认值,常见的默认值设置:
no-cache:不使用本地缓存。向浏览器发送新鲜度校验请求
pubilc:任何情况下都缓存(即使是HTTP认证的资源)
private:只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存
no-store:禁止浏览器缓存数据,也禁止保存至临时文件中,每次都重新请求,多次设置 cache-control,优先级最高
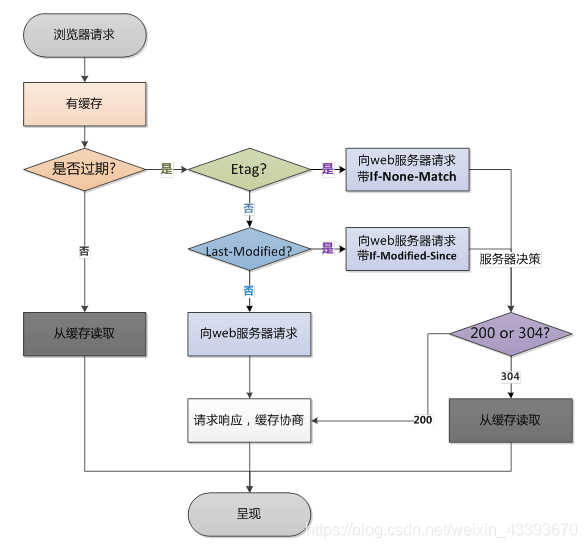
13、哪两组header用户定义协商缓存
Etag/If-None-Match:优先级高于 Last-Modified。
Last-Modified/If-Modified-Since
Last-Modified/If-Modified-Since(两个都是时间格式字符串):
过程:
- 浏览器第一次发送请求,服务器在返回的respone的header加上Last-Modified,表示资源的最后修改时间
- 再次请求资源,在request的header 加上If-Modified-Since,值就是上一次请求返回的Last-Modified值
- 服务器根据请求传过来的值判断资源是否有变化,没有则返回304,有变化就正常返回资源内容,更新Last-modified的值
- 304从缓存加载资源,否则直接从服务器加载资源
Etag/If-None-Match(标识符字符串)
与 Last-Modified/If-Modified-Since 不同的是,返回 304 时,ETag 还是会重新生成返回至浏览器。
优点:
-
有些文件可能会周期性更改,但内容并没有修改时,用 Etag 就不用重新拉取;
-
1S 内修改的文件也会检测到;
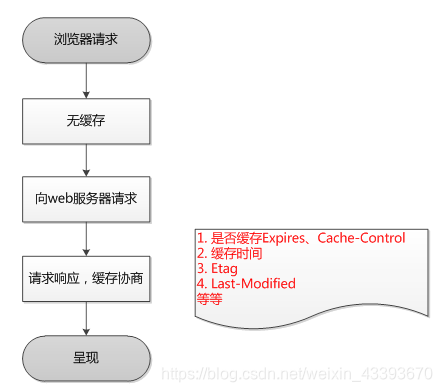
14、强缓存和协商缓存有什么区别
强缓存:直接使用本地缓存,不用跟服务器进行通信
协商缓存:将资源一些信息返回服务器,让服务器判断浏览器能否能直接使用本地缓存,整个过程至少与服务器通信一次
浏览器第一次请求时:
浏览器后续进行请求时:
15、cookie有哪些属性

16、什么时候会发options请求
OPTIONS请求即预检请求,可用于检测浏览器允许的http方法,当发起跨域请求时,由于安全问题,触发一定条件时,浏览器会在正式发起请求之前会自动发OPTIONS请求,即CORS预检请求;简单请求(GET、POST)不发,否则就发
17、跨域问题是怎么产生的,如何解决跨域问题
产生:跨域指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制(所谓同源是指域名,协议,端口均相同)。
解决:
1、JSONP(注:JSONP只支持GET不支持POST);
2、代理:例如www.123.com/index.html需要调用www.456.com/server.php,可以写一个接口www.123.com/server.php,由这个接口在后端去调用www.456.com/server.php并拿到返回值,然后再返回给index.html,这就是一个代理的模式。相当于绕过了浏览器端,自然就不存在跨域问题。
3、PHP修改header:
在php接口脚本中加入以下两句即可:
header(‘Access-Control-Allow-Origin:*’);//允许所有来源访问
header(‘Access-Control-Allow-Method:POST,GET’);//允许访问的方式
举个例子:
-
http://www.123.com/index.html 调用 http://www.123.com/server.php (非跨域)
-
http://www.123.com/index.html 调用 http://www.456.com/server.php (主域名不同:123/456,跨域)
-
http://abc.123.com/index.html 调用 http://def.123.com/server.php (子域名不同:abc/def,跨域)
-
http://www.123.com:8080/index.html 调用 http://www.123.com:8081/server.php (端口不同:8080/8081,跨域)
-
http://www.123.com/index.html 调用 https://www.123.com/server.php (协议不同:http/https,跨域)
注意:localhost和127.0.0.1虽然都指向本机,但也属于跨域
浏览器执行js脚本时,会检查这个脚本属于哪个页面,如果不是同源页面,就不会被执行。
18、如果header中的外部css尚未加载完毕,它后面的js先请求回来了,会执行吗?
不会
19、CSS是否会阻塞DOM渲染
会阻塞
20、Script中的async和defer属性有什么区别
1.defer和async在网络加载过程是一致的,都是异步执行的;
2.两者的区别在于脚本加载完成之后何时执行,可以看出defer更符合大多数场景对应用脚本加载和执行的要求;
3.如果存在多个有defer属性的脚本,那么它们是按照加载顺序执行脚本的;而对于async,它的加载和执行是紧紧挨着的,无论声明顺序如何,只要加载完成就立刻执行,它对于应用脚本用处不大,因为它完全不考虑依赖。
script标签存在两个属性,defer和async,因此script标签的使用分为三种情况:
1、
<script src="example.js"></script>
没有defer或async属性,浏览器会立即加载并执行相应的脚本。也就是说在渲染script标签之后的文档之前,不等待后续加载的文档元素,读到就开始加载和执行,此举会阻塞后续文档的加载;
2、
<script async src="example.js"></script>
有了async属性,表示后续文档的加载和渲染与js脚本的加载和执行是并行进行的,即异步执行;
3、
<script defer src="example.js"></script>
有了defer属性,加载后续文档的过程和js脚本的加载(此时仅加载不执行)是并行进行的(异步),js脚本的执行需要等到文档所有元素解析完成之后,DOMContentLoaded事件触发执行之前。
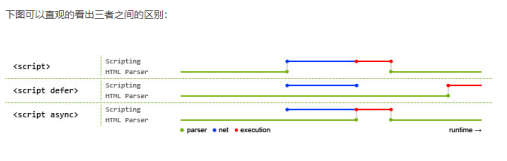
其中蓝色代表js脚本网络加载时间,红色代表js脚本执行时间,绿色代表html解析。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









