



author_na_shi_
一:PELT是做什么的
linux里面可以做任务调度的一个是各种调度器,比如DL限期调度器、RT调度器、CFS调度器,他们完成的是在同一个CPU上任务的调度。还有一种调度是负载均衡,在不同的CPU直接做任务迁移,迁移的依据是每个CPU的整体负载情况,而每个CPU上任务的负载就是通过PELT(per entity load tracking)算法计算出来的,是计算负载的基础。
二:PELT原理
任务负载,是一个任务给系统造成的压力,掌握任务的历史数据和负载情况,可以更好的决策未来如何在各个CPU上分配任务,这是负载的意义。而PELT是计算负载的算法,因为影响到任务的调度,负载的计算不能那么随意,如果短时间内负载变化特别大,那就不能作为调度任务的依据,调度也会太频繁。因此PELT算法不仅计算当前时刻的负载,也计算之前时间的负载,这样把历史数据考虑进来就可以平衡当前时刻负载的较大波动,就像人一样,要看他的长期表现。当前时刻的趋势最接近后面的变化,因此当前时刻负载最重要,时间越久远,对未来影响越小,PELT算法就是按照这个原理计算的。
统计历史数据,PELT使用1024us(约等于1ms)作为一个时间单位,时间每向后推一个1024us,就会多乘一个衰减系数,专家们提供了一个衰减系数y, y^32 = 0.5 y = 0.97857206,衰减规律如下图:
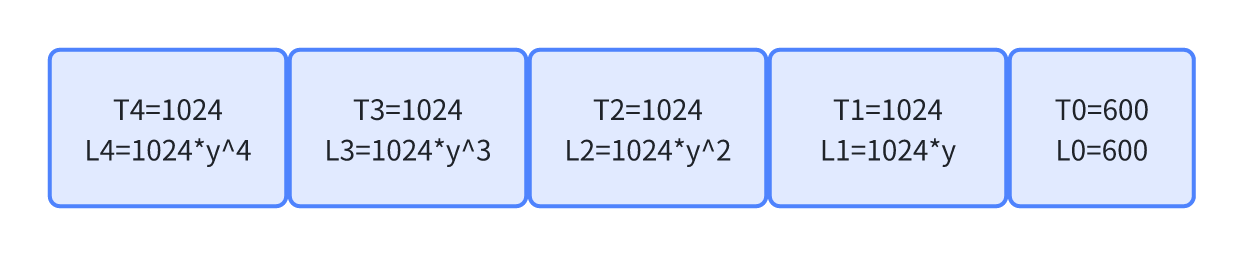
当前时刻T0是不需要衰减的,600us不需要乘y这个衰减系数,T1时刻乘1个y,T4乘4个y,越往后,衰减的越多。那么
L0+L1+L2+L3+L4 就是T0到T4时刻的累计衰减时间,但是任务当前的负载,不仅仅只有L0到L4,还包括L4之前的,实际上就是对时间进行衰减,转换成负载的话,还需要任务权重这个参数。
当前时刻任务负载L=L0+L1+L2+L3+…Ln=T0+T1y+T2y2+T3*y3+…Tny^n
代码中有一句话:
if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
//LOAD_AVG_PERIOD = 32, LOAD_AVG_PERIOD * 63= 2016, 意思是某个时刻的负载经过2017个周期的衰减之后,会变成0,因为时间太长了,所以认定这个时刻的负载为0. 因此Tny^n n>2016就不需要统计了,都是0没有意义
Tny^n 计算:
Tn 的范围就是0 —1024直接的整数,表示时间
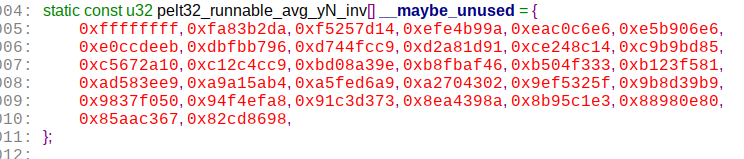
y=0.97857206 n就是经历的周期数,如果运行过程中计算yn,进行大量的浮点数运算会很耗时间,因此yn2^32 提前计算好,存储到一个表里面,最后计算结果的时候在右移动32位,也能获取y^n。 这样把浮点计算转换成了查表,速度提高很多。那n 的值很大,是不是这个表也很大呢?不是的,原因就是y^32=0.5 ,比如n=33,可以拆解为y33=y*y32=0.5y , n=65, y65=y32y^32y=0.50.5*y, 所以表里面的n数值31就可以.如下图,数组值为yn*232,下标范围0–31
decay_load 是计算负载的一个核心函数,参数val可以是时间,某个时刻的累计衰减时间,n是周期个数,表示val这个时间经过n个周期衰减(一个周期是1024us)之后,剩下的值,返回的也是时间。val的值也可以是负载,返回值就是负载经过n个周期衰减之后剩下的值。
/*
* Approximate:
* val * y^n, where y^32 ~= 0.5 (~1 scheduling period)
*/
static u64 decay_load(u64 val, u64 n)
{
unsigned int local_n;
if (unlikely(n > LOAD_AVG_PERIOD * 63))
return 0;
/* after bounds checking we can collapse to 32-bit */
local_n = n;
/*
* As y^PERIOD = 1/2, we can combine
* y^n = 1/2^(n/PERIOD) * y^(n%PERIOD)
* With a look-up table which covers y^n (n<PERIOD)
*
* To achieve constant time decay_load.
*/
if (unlikely(local_n >= LOAD_AVG_PERIOD)) {
val >>= local_n / LOAD_AVG_PERIOD;
local_n %= LOAD_AVG_PERIOD;
}
val = mul_u64_u32_shr(val, pelt_runnable_avg_yN_inv[local_n], 32);
return val;
}
三:任务负载如何更新
首先要计算出上一次负载更新到这一次负载更新时间差,比如上次T0=600是更新负载时间,根据当前更新负载时间,获取时间差为4072us.
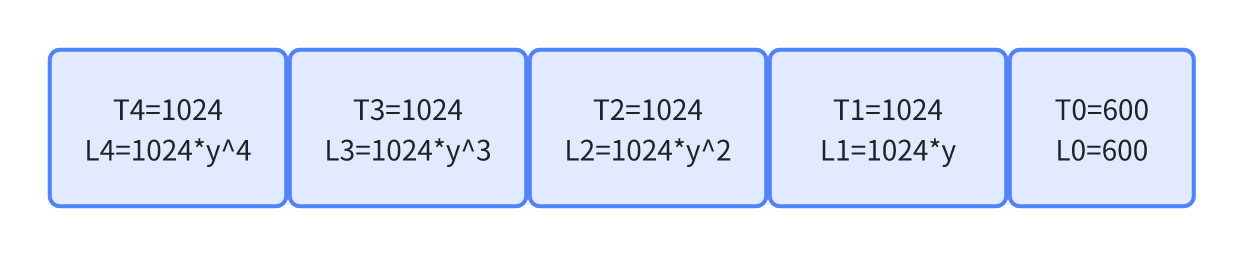

从图可以看出,上次更新负载时候,最后一个周期并不是1024us,而是600,而且这个600在上次更新负载时候并没有进行衰减,因为在当时他就是当前时刻。现在从上次更新又经历了4072us,该如何更新负载呢?
- 从时间差4072里面提取424,和上一次不够一个周期的600组成一个周期1024

- 时间差还剩余 4072-424=3648us ,3648/1024=3 ,也就是说时间差还剩余3个完整的周期

- 时间差通过上面2个步骤,还剩余4072-424-1024*3=576

算法在计算的时候,576就变成了T0时刻

- 计算方法
4.1 补全上个周期计算,假设为Lx(424时间)
假设上次更新T0=600时候的负载为L600(其实这个L600有可能是累计衰减时间,也有可能是累计衰减时间和调度实体权重的乘积,有人称他为工作负载),这个L600还要经历几个周期的衰减呢?答案是 3648/1024=3,3+1=4个周期(从自己周期开始计算)的衰减。用于补全上次更新不足一个周期的L424,也需要经历4个周期的衰减。L600 L424衰减直接调用decay_load函数就可以获取衰减之后的值,注意这里的L600已经说过了,可能是时间,也可能是负载,而L424这里只对时间进行衰减,假设L424衰减之后的值为Lx。
4.2 完整周期负载计算,假设为Ly(完整周期累计时间衰减)
后面还有3个完整的1024周期,也需要衰减并进行累加,采用上面调用decay_load函数方法也能达到目的,但是如果周期特别多,肯定不行了,那要怎么搞?
这3个完整周期的累计衰减时间Le3=1024(y+y2+y3) ,所以问题转换成了等比数列求和,也就是y+y2+…+yn是多少 ? n就是完整的周期数量。
在推演完整周期负载计算方法之前,先交代一个宏 LOAD_AVG_MAX = 1024(1 + y + y^2+ … + y^n)=47742,就是当n趋向无穷大时候的累计衰减时间最大值。
假设完整的周期数量为 p,那么这p个完整周期的累计衰减时间就是 1024(y + y^2+ … + y^p),用数学表达式表示如下图,数学符号不好插入,画个图:

完整周期累计衰减 = LOAD_AVG_MAX -decay_load(LOAD_AVG_MAX,p+1) -1
注意这里的p+1是指从p+1到1,而不是p到0.
4.3 当前时刻不完整周期计算,假设为Lz(当前时刻,<=1024部分)
还有最后一部分的 L0=576 不需要参与衰减,直接累加进去就可以
4.5 从上次更新到现在,累计衰减总时间
最后,当前时刻,当前调度实体的累计衰减时间就是 Lx+Ly+Lz
三:名词解释
PELT负载更新的结果,要有承载的地方,就是一些结构体、变量等,这样其他模块才能使用这个基础设施。

static __always_inline u32
accumulate_sum(u64 delta, struct sched_avg *sa,
unsigned long load, unsigned long runnable, int running)
{
u32 contrib = (u32)delta; /* p == 0 -> delta < 1024 */
u64 periods;
delta += sa->period_contrib;
periods = delta / 1024; /* A period is 1024us (~1ms) */
/*
* Step 1: decay old *_sum if we crossed period boundaries.
*/
if (periods) {
sa->load_sum = decay_load(sa->load_sum, periods);
sa->runnable_sum =
decay_load(sa->runnable_sum, periods);
sa->util_sum = decay_load((u64)(sa->util_sum), periods);
/*
* Step 2
*/
delta %= 1024;
if (load) {
/*
* This relies on the:
*
* if (!load)
* runnable = running = 0;
*
* clause from ___update_load_sum(); this results in
* the below usage of @contrib to dissapear entirely,
* so no point in calculating it.
*/
contrib = __accumulate_pelt_segments(periods,
1024 - sa->period_contrib, delta);
}
}
sa->period_contrib = delta;
if (load)//对于se,load表示是否在队列上0 1,只要在队列就统计时间。对于队列,load是权重
sa->load_sum += load * contrib;
if (runnable)
sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT;
if (running)//只统计正在运行任务的累计衰减时间,util_sum 利用率,有的称为算力
sa->util_sum += contrib << SCHED_CAPACITY_SHIFT;
return periods;
}
void ___update_load_avg(struct sched_avg *sa, unsigned long load)
{
u32 divider = get_pelt_divider(sa);
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider);
sa->runnable_avg = div_u64(sa->runnable_sum, divider);
WRITE_ONCE(sa->util_avg, sa->util_sum / divider);
}
表示负载信息主要是sched_avg结构体,这个结构体可以嵌入在task se,group se,也可以在cfs_rq队列里面,嵌入不同的结构体,sched_avg表示不同的含义,结合accumulate_sum ___update_load_avg这两个函数,解析一下各个成员含义,见下表:
| 负载名称 | task se | group se | cfs 队列 |
|---|---|---|---|
| load_sum | 累计衰减时间,只有时间,没有权重信息。load 传递过来的参数只有0,1,任务在队列上就是1,sa->load_sum += load * contrib,contrib就是上面提到的Lx+Ly+Lz 累计衰减时间 | 同task se,累计衰减时间,只有时间,没有权重信息。load 传递过来的参数只有0,1,只要group中有一个任务在队列上就是1,sa->load_sum += load * contrib,contrib就是上面提到的Lx+Ly+Lz 累计衰减时间 | 队列权重和累计衰减时间乘积,有人称为工作负载。sched_avg 嵌入到cfs_rq中,load参数传递的是队列的权重sa->load_sum += load * contrib |
| runnable_sum | 放大后的累计衰减时间。runnable 传递的只有0 1,看这个任务是否在队列上,sa->runnable_sum += runnable * contrib << SCHED_CAPACITY_SHIFT | 队列中任务数量和累计时间乘积放大。参数runnable=se_runnable(se)=se->runnable_weight=se->my_q->h_nr_running 组实体任务数量,my_q为根的所有层级,这里的任务数量不包括阻塞任务,因此runnable_sum可被看作可运行累计衰减时间和任务数量乘积 | 队列中任务数量和累计时间乘积放大。参数runnable=cfs_rq->h_nr_running 以cfs_rq为根的所有层级任务数量 因此runnable_sum可被看作可运行累计衰减时间和任务数量乘积 |
| util_sum | 正在运行任务累计衰减时间放大。只要这个任务实体正在运行,就会累加他的累计衰减时间 | 正在运行任务累计衰减时间放大。只要这个组实体中有一个任务正在运行,就会累加他的累计衰减时间 | 正在运行任务累计衰减时间放大。只要这个队列中有一个任务正在运行,就会累加他的累计衰减时间 |
| load_avg | 任务实体的平均负载,___update_load_avg传递的load参数这里不是0 1,而是任务的权重,sa->load_sum是累计衰减时间 | 组实体的平均负载,___update_load_avg传递的load参数这里不是0 1,而是任务的权重,sa->load_sum是累计衰减时间 | 队列平均负载。___update_load_avg传递的load参数为1,不是权重,因为在队列里面sa->load_sum 已经包括权重了,权重和累计衰减时间乘积 |
| runnable_avg | 任务可运行平均负载,不包括阻塞任务 | 任务组可运行平均负载,不包括阻塞任务 | cfs队列可运行平均负载,不包括阻塞任务 |
| util_avg | 任务的平均利用率。任务运行期间累计衰减时间之和,除以采样时间 | 任务组的平均利用率。任务运行期间累计衰减时间之和,除以采样时间。只要组内有任务运行,这组实体就是运行的 | 队列的平均利用率。任务运行期间累计衰减时间之和,除以采样时间。只要队列内有任务运行,这个队列就是运行的 |
四:负载更新时间点
- 任务创建
- 任务唤醒
- 任务休眠
- 始终节拍
- 太多了,有时间整理一下吧

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









