







基本理念
支持向量机(SVM,support vector machines)是一种二分类模型。它的基本思想是通过给定的数据找到一条线,这条线尽可能的将数据的正例和负例分开,并且每类数据点到这条线的距离最远。如图1所示,直线
w
⋅
x
+
b
=
0
w\cdot x + b=0
w⋅x+b=0 将正样本点(用"o"表示)和负样本点(用"x"表示)分开。其中
w
w
w可以把它理解为直线的斜率,代表了直线的方向,
b
b
b表示了直线与
y
y
y轴的截距,确定了直线的位置。由高中数学可知将直线两侧的点带入直线方程所得到的结果的符号是不同的,因此我们只需要根据已有样本点确定直线的方程,那么对于新来的样本点,只需要将该点带入直线方程并判断正负,就可以达到分类的效果。

那么我们怎么根据已有的样本点来确定直线方程呢?这还是要用到我们一开始的分类思想:
- 将样本点分开。
- 使每类样本点到直线的距离尽可能远。
其中第一个条件很好理解,那么我们为什么要使每类样本点到直线的距离最远呢?其实这很好理解,如图2所示,点A,B,C均为正例样本点,A距离直线的距离较远,那么我们就有足够的把握认为它属于正例,B距离直线近一点,那么我们认为它属于正例的概率就相应小一点,C距离直线最近,我们认为它属于正例的把握也最小。因此,选取直线时,我们应该使所有的正(负)样本点距离直线的距离最远,这样我们认为我们模型的准确度是最大的。
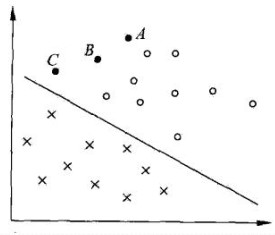
距离的度量
有了上面的理念之后,接下来自然想到如何度量这种间隔的大小。这里我们首先引入函数间隔的概念。
给定一个训练数据集
T
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
n
,
y
n
)
}
T =\{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\}
T={(x1,y1),(x2,y2),...,(xn,yn)}其中,
x
i
x_i
xi为n维向量,是输入的特征向量,
y
i
y_i
yi为输出,为正例
y
i
=
1
y_i=1
yi=1,为负例时
y
i
=
−
1
y_i=-1
yi=−1。定义超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0关于样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)的函数间隔为
γ
^
i
=
y
i
(
w
⋅
x
i
+
b
)
\hat{\gamma}_i=y_i(w\cdot x_i+b)
γ^i=yi(w⋅xi+b)这个公式很好理解,点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)在超平面上则有
w
⋅
x
i
+
b
=
0
w\cdot x_i+b=0
w⋅xi+b=0,点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)距离超平面越远,则
w
⋅
x
i
+
b
w\cdot x_i+b
w⋅xi+b的绝对值越大。若直线刚好可以将正负样本点分开,则
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)为正例时
w
⋅
x
i
+
b
>
0
w\cdot x_i+b>0
w⋅xi+b>0,为负例时
w
⋅
x
i
+
b
<
0
w\cdot x_i+b<0
w⋅xi+b<0。因此
w
⋅
x
i
+
b
w\cdot x_i+b
w⋅xi+b前面乘以
y
i
y_i
yi,就可以保证
γ
^
i
\hat{\gamma}_i
γ^i总是为非负数,这样我们只需要让
γ
^
i
\hat{\gamma}_i
γ^i尽可能大即可。
定义超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0关于整个数据集
T
T
T的函数间隔
γ
^
\hat{\gamma}
γ^为各个点函数间隔的最小值,即
γ
^
=
m
i
n
i
=
1
,
.
.
.
,
n
γ
i
^
\hat{\gamma}=min_{i=1,...,n}\hat{\gamma_i}
γ^=mini=1,...,nγi^函数间隔虽然理解起来比较简单,但是它存在着一个缺陷:如果我们成比例的改变
w
w
w和
b
b
b,例如将
w
w
w改成
2
w
2w
2w,将
b
b
b改成
2
b
2b
2b,则超平面的方程不变,而
γ
^
i
\hat{\gamma}_i
γ^i的值会变大,这就导致了较大的
γ
^
i
\hat{\gamma}_i
γ^i不一定代表较好的分离超平面(一些不好的分离超平面,只要
w
w
w和
b
b
b的值够大,
γ
^
i
\hat{\gamma}_i
γ^i同样可以很大)。因此我们想到对分离超平面的法向量
w
w
w增加某些约束,使得相同的超平面对应的间隔也是确定的。
我们采用规范化的方式来达到这一目的。将函数间隔中的
w
w
w和
b
b
b同时除以
∣
∣
w
∣
∣
||w||
∣∣w∣∣,即
γ
i
=
y
i
(
w
/
∣
∣
w
i
∣
∣
⋅
x
i
+
b
/
∣
∣
w
i
∣
∣
)
\gamma_i=y_i(w/||w_i||\cdot x_i+b/||w_i||)
γi=yi(w/∣∣wi∣∣⋅xi+b/∣∣wi∣∣),则当
w
w
w和
b
b
b同比例增加时,
γ
i
\gamma_i
γi保持不变。
上诉公式
γ
i
=
y
i
(
w
∣
∣
w
i
∣
∣
⋅
x
i
+
b
∣
∣
w
i
∣
∣
)
\gamma_i=y_i(\frac{w}{||w_i||}\cdot x_i+\frac{b}{||w_i||})
γi=yi(∣∣wi∣∣w⋅xi+∣∣wi∣∣b)即为几何间隔的定义。其中
∣
∣
w
∣
∣
||w||
∣∣w∣∣为
w
w
w的
L
2
L_2
L2范数。
同样的,我们定义
γ
=
m
i
n
i
=
1
,
.
.
.
n
γ
i
\gamma=min_{i=1,...n}\gamma_i
γ=mini=1,...nγi为超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0关于整个数据集
T
T
T的几何间隔。
几何间隔
γ
i
\gamma_i
γi表示样本点
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)与超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0的带符号的距离。若某一样本点未被正确分类,则
γ
i
\gamma_i
γi为负值,否则,
γ
i
\gamma_i
γi为正值。
从函数间隔与几何间隔的定义可以看出,函数间隔与几何间隔有如下关系:
γ
i
=
γ
^
i
∣
∣
w
∣
∣
\gamma_i=\frac{\hat{\gamma}_i}{||w||}
γi=∣∣w∣∣γ^i
γ
=
γ
^
∣
∣
w
∣
∣
\gamma=\frac{\hat{\gamma}}{||w||}
γ=∣∣w∣∣γ^如果
∣
∣
w
∣
∣
=
1
||w||=1
∣∣w∣∣=1,则函数间隔和几何间隔相等。
间隔最大化
有了距离的度量标准,下一步要做的就是使样本点到超平面的距离最大。由上面的讨论可知,我们要做的是使几何间隔最大。假定我们的样本是线性可分的,即存在超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0将样本的正例和负例正确分开。那么我们的直观想法就是最大化各样本点关于超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0的几何间隔的最小值,这一想法可以表达成一个约束最优化问题:
m
a
x
w
,
b
γ
max_{w,b}\ \ \gamma
maxw,b γ
s
.
t
.
y
i
(
w
∣
∣
w
i
∣
∣
⋅
x
i
+
b
∣
∣
w
i
∣
∣
)
≥
γ
,
i
=
1
,
2
,
.
.
.
,
n
s.t.\ \ y_i(\frac{w}{||w_i||}\cdot x_i+\frac{b}{||w_i||})\geq\gamma,\ \ i=1,2,...,n
s.t. yi(∣∣wi∣∣w⋅xi+∣∣wi∣∣b)≥γ, i=1,2,...,n约束条件保证了
γ
\gamma
γ为数据集
T
T
T中所有样本点关于超平面
w
⋅
x
+
b
=
0
w\cdot x+b=0
w⋅x+b=0的最小值,而我们要改变参数
w
w
w和
b
b
b的值,使得该值最大。这里注意,由于样本是线性可分的,因此最大的
γ
\gamma
γ一定是正值,这就保证了所有的
γ
i
\gamma_i
γi也是正值,因此所找到的超平面一定可以将样本点正确分开。
考虑到
γ
=
γ
^
/
∣
∣
w
∣
∣
\gamma=\hat{\gamma}/||w||
γ=γ^/∣∣w∣∣,可以将上式改写成
m
a
x
w
,
b
γ
^
∣
∣
w
∣
∣
max_{w,b}\ \ \frac{\hat{\gamma}}{||w||}
maxw,b ∣∣w∣∣γ^
s
.
t
.
y
i
(
w
⋅
x
i
+
b
)
≥
γ
^
,
i
=
1
,
2
,
.
.
.
,
n
s.t.\ \ y_i(w\cdot x_i+b)\geq\hat{\gamma},\ \ i=1,2,...,n
s.t. yi(w⋅xi+b)≥γ^, i=1,2,...,n
γ
^
\hat{\gamma}
γ^的取值不会影响上述最优化问题的求解。假设将
γ
^
\hat{\gamma}
γ^变成
λ
γ
^
\lambda\hat{\gamma}
λγ^,鉴于
w
w
w和
b
b
b都是变量,改变他们的值对优化问题没有影响,我们可以将变量
w
w
w和
b
b
b分别变成
λ
w
\lambda w
λw和
λ
b
\lambda b
λb,这样,目标函数没有变化,约束条件也没有变化,因此改变后的约束问题和原约束问题是等价的。
为了方便,我们取
γ
^
=
1
\hat{\gamma}=1
γ^=1,带入上面的最优化问题,并注意到最大化
1
∣
∣
w
∣
∣
\frac{1}{||w||}
∣∣w∣∣1和最小化
1
2
∣
∣
w
∣
∣
\frac{1}{2}||w||
21∣∣w∣∣是等价的,于是得到下面的线性可分支持向量机学习的最优化问题:
m
i
n
w
,
b
1
2
∣
∣
w
∣
∣
2
min_{w,b}\ \ \frac{1}{2}||w||^2
minw,b 21∣∣w∣∣2
s
.
t
.
y
i
(
w
⋅
x
i
+
b
)
−
1
≥
0
,
i
=
1
,
2
,
.
.
.
,
n
s.t.\ \ y_i(w\cdot x_i+b)-1\geq0,\ \ i=1,2,...,n
s.t. yi(w⋅xi+b)−1≥0, i=1,2,...,n该优化问题的目标函数是在
R
n
R^n
Rn上连续可微的凸函数,且约束函数是线性的,因此上述最优化问题为一个凸二次规划问题。求出该最优化问题的解
w
∗
w^*
w∗、
b
∗
b^*
b∗,就可以得到最大间隔分离超平面
w
∗
⋅
x
+
b
∗
=
0
w^*\cdot x+b^*=0
w∗⋅x+b∗=0和分类决策函数
f
(
x
)
=
s
i
g
n
(
w
∗
⋅
x
+
b
∗
)
f(x)=sign(w^*\cdot x+b^*)
f(x)=sign(w∗⋅x+b∗)
支持向量和间隔边界
接下来解释一下支持向量和间隔边界的概念。在线性可分的情况下,训练数据集中的样本点中与分离超平面最近的样本点的实例称为支持向量。由支持向量的定义可知支持向量
(
x
i
,
y
i
)
(x_i,y_i)
(xi,yi)满足
y
i
(
w
⋅
x
i
+
b
)
=
1
y_i(w\cdot x_i+b)=1
yi(w⋅xi+b)=1对于
y
i
=
+
1
y_i=+1
yi=+1的实例点,支持向量在超平面
H
1
:
w
⋅
x
+
b
=
1
H_1:w\cdot x+b=1
H1:w⋅x+b=1上,对于
y
i
=
−
1
y_i=-1
yi=−1的样本点,支持向量在超平面
H
2
:
w
⋅
x
+
b
=
−
1
H_2:w\cdot x+b=-1
H2:w⋅x+b=−1上。注意到
H
1
H_1
H1和
H
2
H_2
H2是平行的,并且没有样本点落在它们中间,分离超平面与它们平行且位于它们中央。不难算出,
H
1
H_1
H1和
H
2
H_2
H2之间的距离为
2
∣
∣
w
∣
∣
\frac{2}{||w||}
∣∣w∣∣2,此即为间隔。
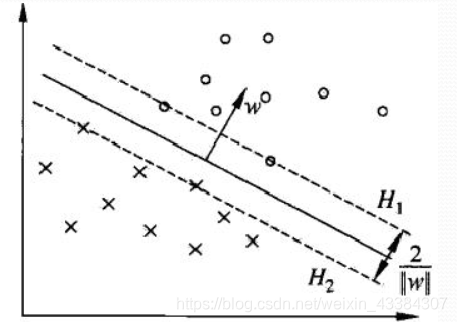
由以上的分析可知,分离超平面只与少数的支持向量有关,改变除支持向量以外的其他点并不会对分离超平面产生影响。由于支持向量在确定分离超平面中起决定性作用,因此将这种分类模型称为支持向量机。
以上介绍的是最简单的支持向量机方法,采用的是硬间隔最大化,可用于线性可分数据集。对于线性不可分的数据集,要采用软间隔最大化的方法。
参考文献1
李航. 统计学习方法. 北京:清华大学出版社,2019. ↩︎

















 6417
6417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









