






 本文提出了一种名为ConvCRFs的新结构,通过在全连通条件随机场(CRFs)框架中引入条件独立假设,解决了CRFs训练和推理速度慢及参数学习难的问题。该方法特别适用于图像分割任务,能有效利用全局上下文信息,增强预测间的相互作用。代码已开源。
本文提出了一种名为ConvCRFs的新结构,通过在全连通条件随机场(CRFs)框架中引入条件独立假设,解决了CRFs训练和推理速度慢及参数学习难的问题。该方法特别适用于图像分割任务,能有效利用全局上下文信息,增强预测间的相互作用。代码已开源。
ConvolutionalCRFsforSemanticSegmentation
Abstract: 在图像分割领域,现在好多有效的模型都结合了CRFs。但是近期CRFs后处理方式逐渐被抛弃。主要原因是由于CRF的训练和推理速度较慢,以及内部CRF参数的学习困难所致。为了克服这两个问题,我们建议在全连通CRFs的框架中加入条件独立的假设。代码地址:https://github.com/MarvinTeichmann/ConvCRF
1 Introduction
虽然深度神经网络在提取局部特征和对小视场进行良好预测方面非常强大,但它缺乏利用全局上下文信息的能力,不能直接对预测之间的交互进行建模。但是CRFs存在一些问题,为此,本文提出了ConvCRFs结构。
2 Related Work
金字塔池(Pyramid pooling)是CRFs的一种替代方案,它结合了一些上下文知识。金字塔汇聚增加了CNN的有效视场,但并不能提供真正的结构化推理。
ParameterLearninginCRFs
FullCRFs依赖于成对(高斯)内核的手工特性。结合期望最大化和网格搜索对其余参数进行优化。他们建议使用gradient decent。
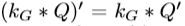
二次优化(Quadratic optimization )被用来学习FullCRFs的高斯特征。然而,这些方法并不适合许多深度学习管道。学习成对特征的另一种方法是分段训练(piecewise training)。
Inference speed of CRFs
为了规避的问题很长时间训练和推断,一些基于CRF管道生成一个输出down-sampled的8×8。
3、Fully Connected CRFs


3.1 Mean Field Inference
 4 Convolutional CRFs
4 Convolutional CRFs
ConvCRFs在FullCRFs的基础上加入了条件独立假设。若两个像素Manhattan distance大于k,则认为这两个像素条件独立。这里把超参数k称为filter-size。 It implies that the pairwise potential is zero, for all pixels whose distance exceed k。
4.1 Efficient Message Passing in ConvCRFs
略

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









