







 本文介绍了一个Python脚本,使用Selenium和BeautifulSoup抓取亚马逊黄金箱的优惠信息,包括自动设置美国邮政编码并遍历多页商品。通过模拟用户行为,脚本能够动态切换地址并处理可能出现的验证码问题。
本文介绍了一个Python脚本,使用Selenium和BeautifulSoup抓取亚马逊黄金箱的优惠信息,包括自动设置美国邮政编码并遍历多页商品。通过模拟用户行为,脚本能够动态切换地址并处理可能出现的验证码问题。
1-爬取目标网站
url=https://www.amazon.com/gp/goldbox/ref=gbps_ftr_s-5_884a_dls_MISD?gb_f_deals1=sortOrder:BY_SCORE,includedAccessTypes:GIVEAWAY_DEAL,dealStates:EXPIRED%252CSOLDOUT&pf_rd_p=5ab3fe28-c461-42eb-a0ee-746265f9884a&pf_rd_s=slot-5&pf_rd_t=701&pf_rd_i=gb_main&pf_rd_m=ATVPDKIKX0DER&pf_rd_r=BP1ABCZWS18B7FYHPJ9C&ie=UTF8
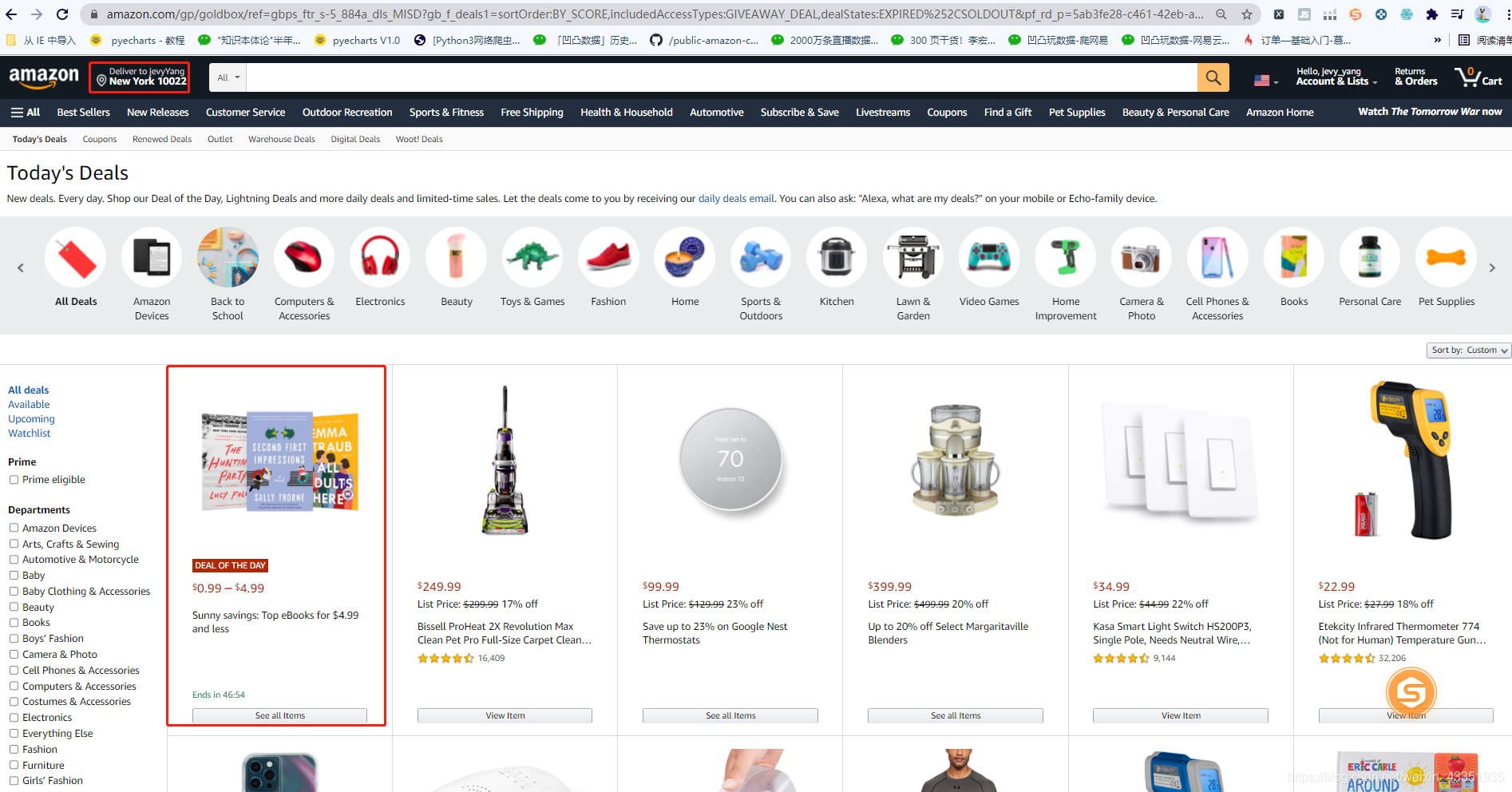
j解析什么的都不说了,,直接贴代码了:
# -*- coding: utf-8 -*-
# @File : Google_selenium.py
# @Author : ${杨杰伟}
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from fake_useragent import UserAgent
import random
import pandas as pd
from selenium.webdriver.common.action_chains import ActionChains # 控制鼠标进行点击的
from selenium.common.exceptions import TimeoutException
from lxml import etree
from datetime import datetime
class Get_link():
def __init__(self):
chrome_options = Options()
ua = UserAgent()
NoImage = {"profile.managed_default_content_settings.images": 2} # 控制 没有图片
chrome_options.add_experimental_option("prefs", NoImage)
chrome_options.add_argument(f'user-agent={ua.chrome}') # 增加浏览器头部
self.browser = webdriver.Chrome(options=chrome_options,executable_path=r"D:\all_env\spider_redis\Scripts\chromedriver.exe")
# self.browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
# 'source': 'Object.defineProperty(navigator,"webdriver",{get:()=>undefined})'
# }) # 执行代码 去掉Chrome 驱动控制
self.wait = WebDriverWait(self.browser, 10)
self.browser.maximize_window() # 最大化窗口
# self.browser.set_window_size(1000, 800)
def click_address(self):
# global wait
try:
url = "https://www.amazon.com/"
self.browser.get(url)
button_change_address = self.wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,
'#nav-global-location-slot > span > a'))) # 点击选择定位的,
button_change_address.click()
time.sleep(random.randint(1, 3))
input = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#GLUXZipUpdateInput'))
)
input.send_keys("90017") # 输入邮编。。
button_set = self.wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#GLUXZipUpdate > span > input')))
# print('点击设置。。')
time.sleep(1.5)
button_set.click()
try:
time.sleep(random.randint(2, 4))
button_done = self.wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#GLUXConfirmClose'))) # 跟美国的不一样。
button_done.click() # fertig 按钮。
print("按钮点击完成。。")
except:
ActionChains(self.browser).move_by_offset(1070, 640).click().perform() # 鼠标左键点击, 200为x坐标, 100为y坐标
print("鼠标点击")
time.sleep(random.randint(1, 3))
total = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#glow-ingress-line2')))
print("出现邮编结果", total.text)
self.browser.refresh() # 刷新
except TimeoutException:
self.click_address()
def return_info(self, html_source):
html = etree.HTML(html_source)
result1 = html.xpath('//*[@id="widgetContent"]/div') # 48个 或者 24 个
data_two=[]
for i in range(len(result1)):
result_f = html.xpath(f'//*[@id="101_dealView_{i}"]//text()')
text2 = [te.strip() for te in result_f if te.strip() != '']
if 'emptyBlock' in text2:
text2.remove('emptyBlock')
href = html.xpath(f'//*[@id="101_dealView_{i}"]//a[@id="dealImage"]/@href')
data_two.append(href + text2)
print(text2)
self.close_window()
return data_two
def getInfo(self, url,n): # 通过输入网址,并获取信息。。
if n ==1 :
js1 = f" window.open('{url}')" # 执行打开新的标签页
self.browser.execute_script(js1) # 打开新的网页标签
self.browser.switch_to.window(self.browser.window_handles[-1]) # 此行代码用来定位当前页面窗口
self.browser.refresh() #刷新
else: #翻页
button_change_page = self.wait.until(
EC.element_to_be_clickable((By.XPATH,
'//*[@id="FilterItemView_page_pagination"]//div[@class="a-text-center"]//li[@class="a-last"]'))) # 点击选择定位的,
button_change_page.click()
time.sleep(1)
self.browser.refresh() # 刷新
self.Manual_Slide() # 滑动浏览器
time.sleep(3)
total_wait = self.wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.a-text-center')))
print('total_wait',total_wait)
html_source = self.browser.execute_script("return document.documentElement.outerHTML") #执行js得到整个HTML
# html_source = self.browser.page_source #获取网页源代码 # 这里不破解验证码,爬取的不多,直接调用解析HTML文件的函数
if 'Robot Check' not in html_source:
data_to_save = self.return_info(html_source)
return data_to_save
else:
return None
def Manual_Slide(self):
for i in range(18):
time.sleep(1)
self.browser.execute_script('window.scrollBy(0,200)', '')
return
def close_window(self):
length = self.browser.window_handles
print('length', length)
if len(length) > 3:
self.browser.switch_to.window(self.browser.window_handles[1])
self.browser.close()
time.sleep(1.5)
self.browser.switch_to.window(self.browser.window_handles[-1])
def quit_win(self):
self.browser.quit()
def save_excel(data_two): #传进来一个二维列表
file_name=str(datetime.now().date())
excel_filepath = f'./{file_name}的deals.xlsx'
write = pd.ExcelWriter(excel_filepath)
sheet_num = {len(i) for i in data_two}
for sheet in sheet_num:
s_one = [i for i in data_two if len(i) == sheet]
df1 = pd.DataFrame(s_one)
df1.to_excel(write, sheet_name=str(sheet))
write.save()
if __name__ == '__main__':
amazon_deals = Get_link() #实例化对象
amazon_deals.click_address() # 1.先更改邮编,
time.sleep(2)
# 链接没有进行破解,需要复制粘贴过来进行抓取
spider_url='https://www.amazon.com/gp/goldbox/ref=gbps_ftr_s-5_884a_dls_MISD?gb_f_deals1=sortOrder:BY_SCORE,includedAccessTypes:GIVEAWAY_DEAL,dealStates:EXPIRED%252CSOLDOUT&pf_rd_p=5ab3fe28-c461-42eb-a0ee-746265f9884a&pf_rd_s=slot-5&pf_rd_t=701&pf_rd_i=gb_main&pf_rd_m=ATVPDKIKX0DER&pf_rd_r=BP1ABCZWS18B7FYHPJ9C&ie=UTF8'
data=[]
for page in range(1,11):
data_re=amazon_deals.getInfo( spider_url,page) #返回的二维列表
data+=data_re
time.sleep(1.5)
amazon_deals.quit_win() #关闭窗口
save_excel(data)
3-结果
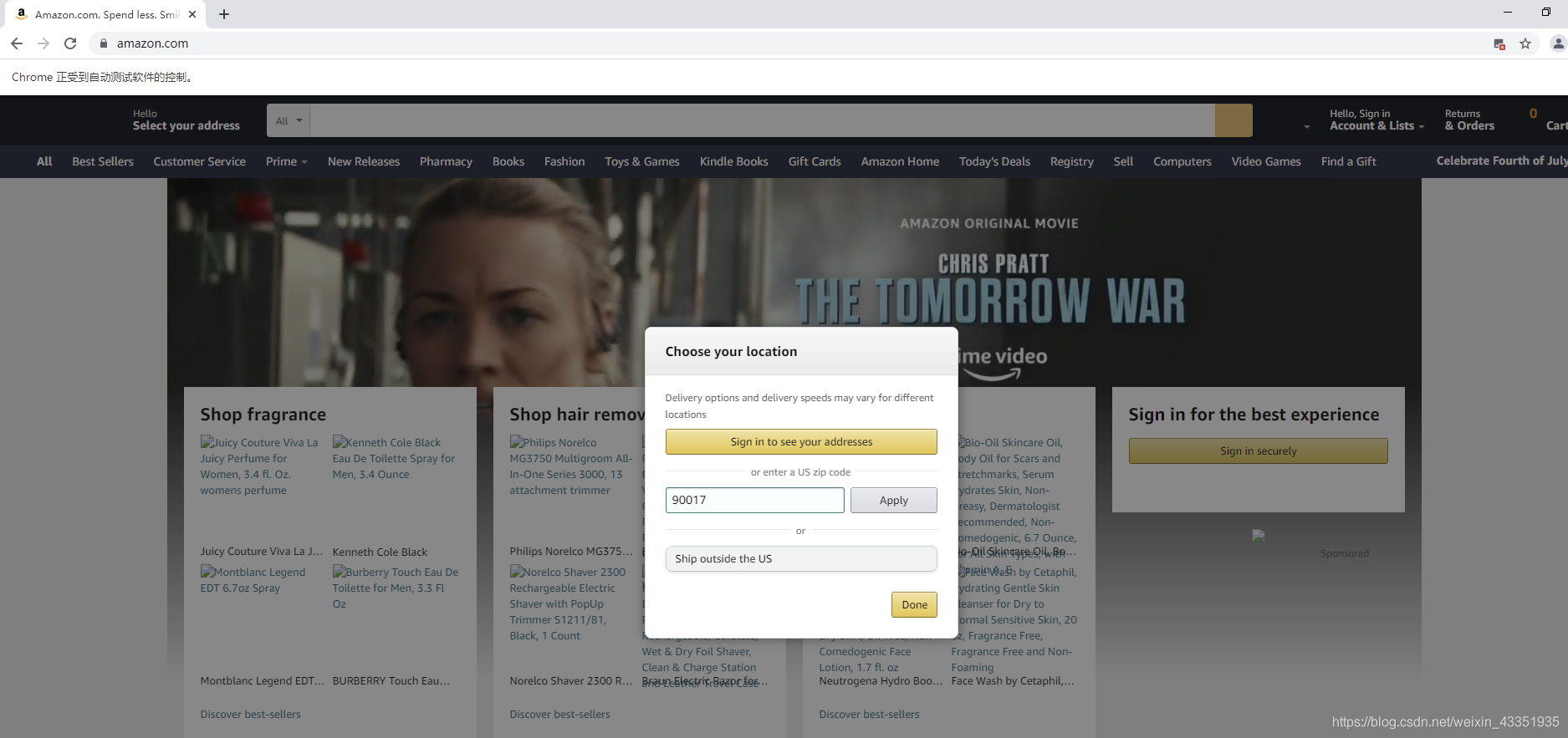
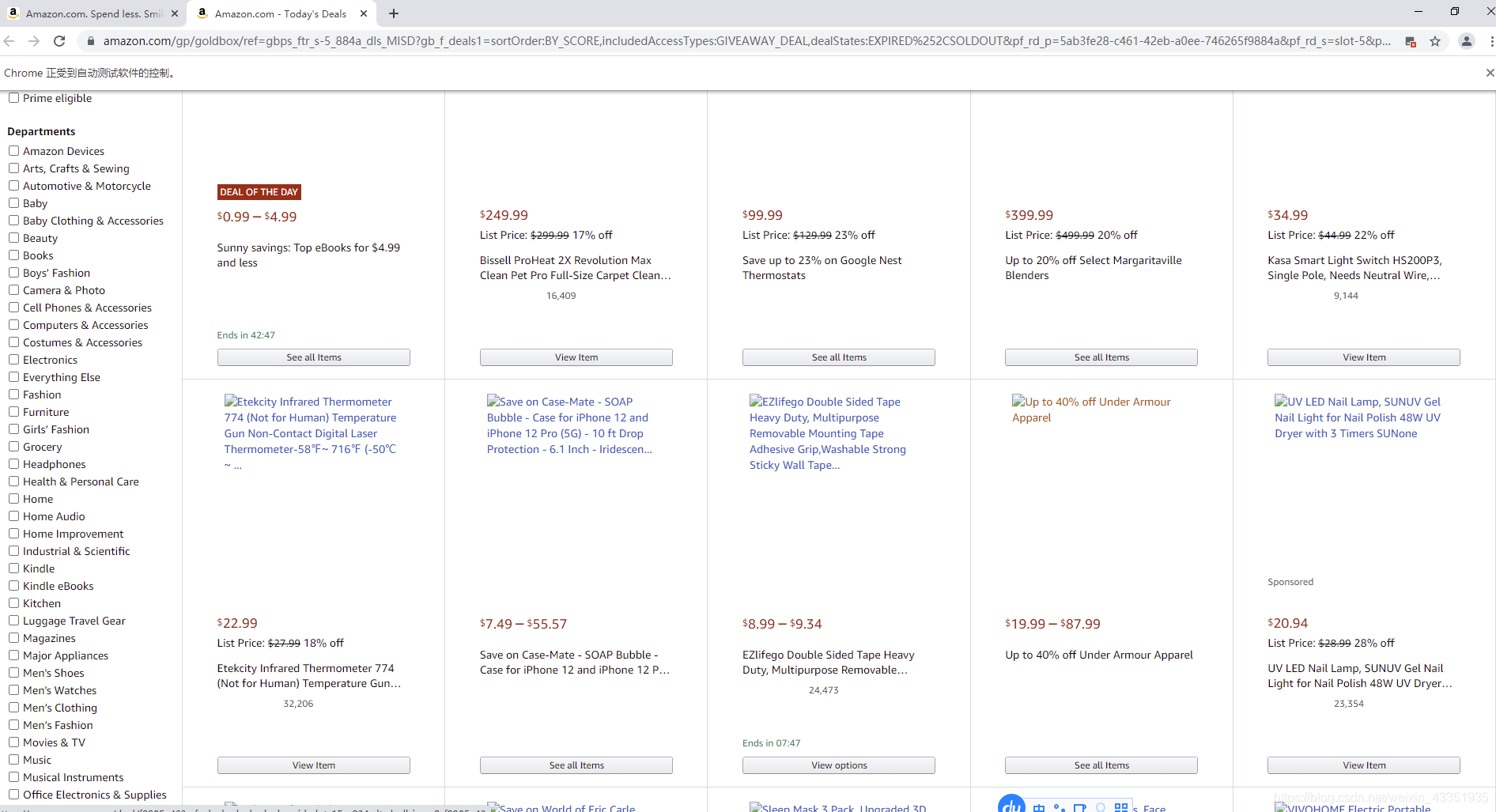
4-最后的保存结果,可以修改一下、、


















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











