






1.block大小限制
CUDA中对能够定义的网格大小和线程块大小做了限制。对任何从开普勒到图灵架构
的GPU来说,网格大小在x、y和z这3个方向的最大允许值分别为2^31-1、65535和65535;
线程块大小在x、y和z这3个方向的最大允许值分别为1024、1024和64。另外还要求线
程块总的大小,即blockDim.x、blockDim.y和blockDim.z的乘积不能大于1024。也就
是说,不管如何定义,一个线程块最多只能有1024个线程。这些限制是必须牢记的。
2 减少数据传输CPU-GPU
GPU计算核心和设备内存之间数据传输的峰值理论带宽要远高于GPU和CPU之间数据传输的带宽。大概相差几十倍。
要获得可观的GPU加速,就必须尽量缩减数据传输所花时间的比例。有时候,即使有些计算在GPU中的速度并不高,也要尽量在GPU中实现,避免过多的数据经由PCIe传递。
这是CUDA编程中较重要的原则之一
3 计算时间
可以通过 事件 计时 或 nvprof 统计时间。
一般,单精度float版本的核函数都比双精度double版本核函数快。
一个CUDA程序能够获得高性能的必要(但不充分)条件有如下几点:
• 数据传输比例较小。
• 核函数的算术强度较高。一个计算问题的算术强度指的是其中算术操作的工作量与必要的内存操作的工作量之比。
• 核函数中定义的线程数目较多。
4 检查内存错误
用cuda-memcheck 检查内存错误。
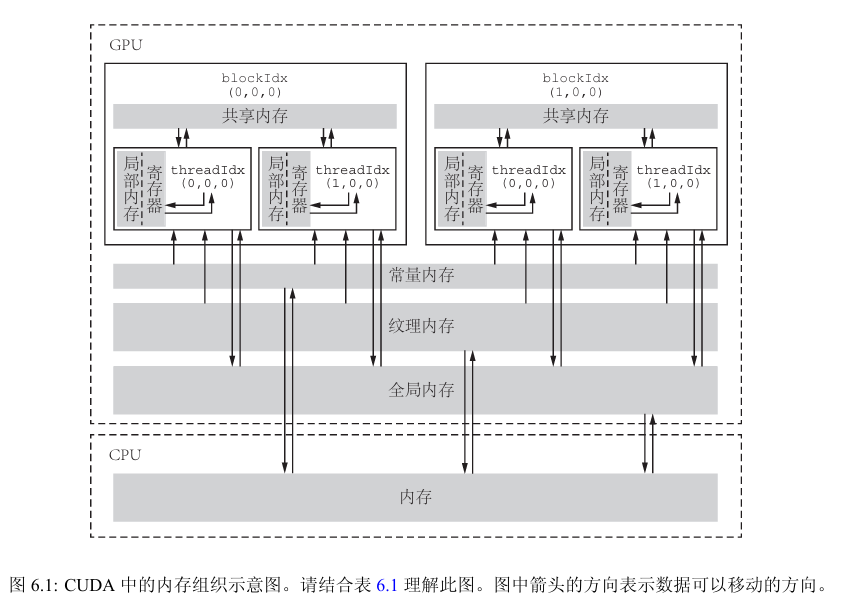
5 cuda内存分级
表6.1: CUDA中设备内存的分类与特征
内存类型 物理位置 访问权限 可见范围 生命周期
全局内存 在芯片外 可读可写 所有线程和主机端 由主机分配与释放
常量内存 在芯片外 仅可读 所有线程和主机端 由主机分配与释放
纹理和表面内存 在芯片外 一般仅可读 所有线程和主机端 由主机分配与释放
共享内存 在芯片内 可读可写 单个线程块 所在线程块
寄存器内存 在芯片内 可读可写 单个线程 所在线程
局部内存 在芯片外 可读可写 单个线程 所在线程

6 线程分配
线程束的大小是32,所以一个线程块的大小最好是32的整数倍

















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









