




 在使用Hive on Spark时遇到""No LZO codec found, cannot run.""错误。排查过程包括:检查hadoop-lzo.jar的兼容性,确认Hive与Spark版本匹配并重新编译,配置Hive和Spark的环境,重装CentOS上的lzo,最后发现是Spark未找到LZO解析器,将hadoop-lzo-0.4.20.jar上传到HDFS解决问题。"
109326024,1341894,Oracle数据库优化:34个提高SQL执行效率的技巧,"['数据库', 'SQL']
在使用Hive on Spark时遇到""No LZO codec found, cannot run.""错误。排查过程包括:检查hadoop-lzo.jar的兼容性,确认Hive与Spark版本匹配并重新编译,配置Hive和Spark的环境,重装CentOS上的lzo,最后发现是Spark未找到LZO解析器,将hadoop-lzo-0.4.20.jar上传到HDFS解决问题。"
109326024,1341894,Oracle数据库优化:34个提高SQL执行效率的技巧,"['数据库', 'SQL']
问题:使用hive on spark,创建lzo存储格式的表格,查询数据的时候,报错:No LZO codec found, cannot run。
解决和排错过程:
1.百度No LZO codec found, cannot run,搜索结果分为以下三种原因:
1). hadoop-lzo.jar包的兼容性问题
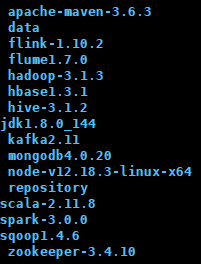
首先确定我的框架版本:
(1).官方下载的lzo-master是一个maven项目,解压之后,修改pom文件中
<hadoop.current.version>2.6.0</hadoop.current.version> #这里修改成对应的hadoop版本号
(2).官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
百度都有
我使用的这些编译好的包会在后面贴出来
我使用的是hadoop-lzo-0.4.20.jar。
2). $HADOOP_HOME/etc/hadoop/core-site.xml的配置问题。
$ vim $HADOOP_HOME/etc/hadoop/core-site
------------添加-----------
<proper 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









