







 本文深入探讨Kafka的高级知识点,包括分片和副本机制确保数据分布与安全,详细阐述Producer、Broker和Consumer如何保证数据不丢失,以及Kafka的消息存储、查询机制和数据分发策略。同时,介绍了消费者的负载均衡机制,揭示Kafka如何在确保高可靠性的同时实现高效数据处理。
本文深入探讨Kafka的高级知识点,包括分片和副本机制确保数据分布与安全,详细阐述Producer、Broker和Consumer如何保证数据不丢失,以及Kafka的消息存储、查询机制和数据分发策略。同时,介绍了消费者的负载均衡机制,揭示Kafka如何在确保高可靠性的同时实现高效数据处理。
文章目录
前言
上篇文章主要讲解Kafka Shell命令和相关API,本文介绍Kafka中较为高级的知识,分片、副本机制等,让我们接着往下看。
一、分片和副本机制
(一)分片机制
分片机制主要解决单台服务器存储容量有限的问题,当数据量非常大的时候,一台服务器存储不了,可以通过将数据拆成多份,分别存在Kafka集群中的不同服务器中;一台服务器上的数据叫做一个分片。
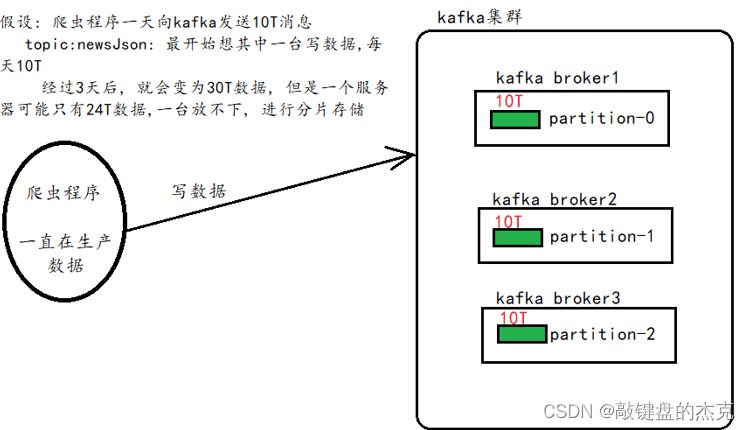
(二)副本
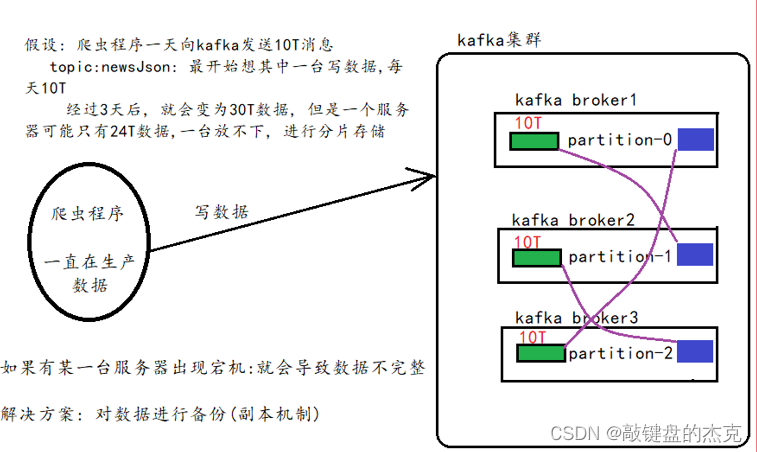
副本备份机制主要是解决数据安全性问题,如果数据只保存一份,那么存在数据丢失的风险,为了更好的容灾和容错,可以将同一份数据存储在不同的服务器上,从而保证数据的安全性。
二、如何保证数据不丢失
保证数据不丢失主要有三个方面,分别是Producer生产者、Broker以及Consumer消费者。
(一)Producer生产者
如果保证生产者数据不丢失,生产数据时需要服务器返回一个响应码Ack,从而保证Kafka集群已经接受到数据,
关于Ack主要有三个状态,根据不同的需求选择不同的Ack状态值:
- 状态值为0:生产者只管生产数据,无需确认Kafka集群是否接收到数据;
- 状态值为1:Kafka集群中的Leader节点接收到数据后返回响应;
- 状态值为-1: Kafka集群中所有节点都接收到数据后返回响应
关于生产者生产数据,存在较为重要的三个问题:
- 如果生产数据时,Kafka集群没有回复Ack响应
- 一条一条发送到Kafka集群中,是否有占用带宽
- 在第2点基础上,如果数据存满后发送给Kafka集群,若此时集群没有及时响应,如何处理缓存池中的数据
针对上方三个问题,肯定有相对应的解决方案,
第一个问题的解决方案就是Producer设置一个TimeOut超时时间,一超时就认定为发送失败;
第二个问题主要的点在于一条一条发送会占用一定的带宽,将数据放进一个缓冲区中,达到一定数据量或者时间,再将缓存区中的数据统一发送给Kafka集群,即可解决问题;
第三个问题需要视具体需求而定,可以对Kafka集群进行设定,若出现该问题,则可以设定是否情况缓冲池中的数据。
(二)Broker端
Broker端保证数据不丢失主要从两个方面入手:
- 一方面是上方说到的副本机制,一份数据在不同的Broker节点上备份,即使一个节点上的数据丢失,也可以从其他Broker节点上找到相对应的数据;
- 另一方面则是Producer生产者设置的Ack响应,Ack状态值设置为-1,则生成数据时保证每个节点上都有存储相同的数据。
(三)Consumer消费者
Consumer消费者保证数据不丢失的方式为Offset Commit,Kafka记录每次消费的Offset数值,根据Offset数值找到对应消费信息的位置,然后接着往下消费;
在Kafka最新版本中,Offset信息存储在一个专用的Topic中,每次消费都会更新该Topic中的Offset数值,即使节点宕机了,重启后仍然可以继续消费,由于不是每次消费都能及时更新Offset信息,例如节点宕机,在该情况下,不会造成数据丢失,但会出现数据重复消费的问题。
三、Kafka消息存储和查询机制
(一)消息存储
在Kafka的数据存储目录中,存在档案后缀为“.index”和“.log”的文件,这两份档案组成一个Segment段,以档案中存储的第一个offset的值命名,,数据实际存储在log文件夹中,index文件起到辅助的作用,通过index文件找到log文件中相对应的数据;
如果存储的数据量太大,则会分多个文件存储,这个现象需要从Kafka的本质说起,Kafka作为一个临时的消息中间件,只存储临时的数据,而不永久存储数据,所以涉及到过期数据的删除,如果只存储在一个文件中,删除过期数据将会十分麻烦,分为多个文件存储,只需要根据文件的日期属性就可以进行删除。
【补截图】
(二)数据查询机制
数据查询主要分为两步:
- 确定对应数据存储的Segment段,由于Segment端中的文件以Offset命名,根据本次消费的Offset值就可以快速找到对应的Segment段 【补截图】
- 依次定位到Segment端中的index元数据物理位置和log物理偏移位置,然后再依次查找log文件中的Offset值,直到目标Offset为止 【补截图】
四、生产者数据分发策略
生产者生产数据后,根据数据分发机制,将数据发送到不同的分区中,从而提高数据的处理效率,主要的数据分发策略有:
- 用户指定Partition,生产的数据直接放置到目标Partition中 【补截图】
- 生产数据时仅指定Key,而没有指定Partition,此时根据Hash算法,将数据分发到对应的Partition 【补截图】
- 粘性划分策略,Kafka 2.4版本及以上使用该数据划分策略,旧版本则是使用轮询策略,生产数据时用户既没有指定Key,也没有指定Partition时,使用该种划分策略,该策略会随机选择一个分区,并且尽可能将数据都放置在该分区中,粘住同一个分区。【补截图】
五、消费者的负载均衡机制
一个Partition只能被一个组中的成员消费,如果消费者的数量大于Partition的数量,那么一定存在消费者是闲置的状态,消费者消费数据存在以下两个问题:
- 生产者生产数据过快,消费者消费的速度跟不上,这种情况会造成数据的堵塞,由于同一个消费组消费同一份数据,此时可以在消费组中适当增加消费者的数量,从而提高数据的消费速度。
- 若增加消费者数量仍无法解决数据堵塞问题,因为消费者数量最多等于Topic的Partition数量,如果此时消费者数量仍小于Partition数量,可以再次增加消费者的数量,若无法再使用此方法,要么通过增加Topic的Partition数量,从而增加消费者的数量,要么提高消费者处理数据的效率。
【补截图】
总结
Kafka是消息队列的中间件,具有高可靠性和极强的性能,保证数据的安全性的同时还能保证高吞吐量数据的处理效率。


















 2164
2164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











