







 本文解析了DETR如何将Transformer应用于对象检测,介绍了其基本思想、核心组件(编码器、位置初始化query、并行预测头)和优势。核心是Transformer-Decoder的并行结构,能同时预测多个物体位置和类别。不同于传统NLP,DETR无需mask机制,使用100个对象查询实现端到端检测。
本文解析了DETR如何将Transformer应用于对象检测,介绍了其基本思想、核心组件(编码器、位置初始化query、并行预测头)和优势。核心是Transformer-Decoder的并行结构,能同时预测多个物体位置和类别。不同于传统NLP,DETR无需mask机制,使用100个对象查询实现端到端检测。
目录
End to End Object Detection with Transformers
End to End Object Detection with Transformers
第一次把transformer用在object detection上面

Because of DETR,Transformer is getting hot again.
people think transformer is just a backbone,backbone is not directly suitable for Downstream tasks.
基本思想
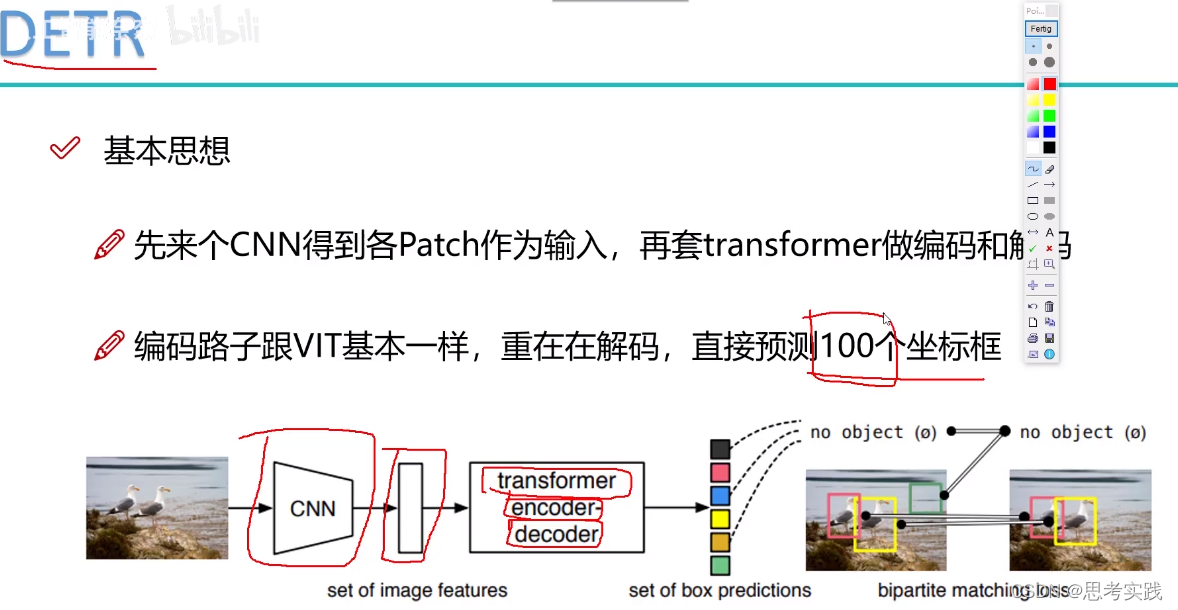
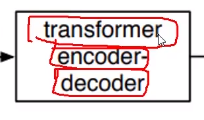
Vit like Bert ,just have the encoder part of the transformer,but Detr have both of encoder module and decoder module.
DETR没有套用Swin窗口分层的形式,它就是一个直接的transformer
First step,get patch work and positional embedding work ready(then every patch is a time vector),just like vit work(vit just use the encoder of the transformer)
那么问题来了,我们得到编码输出之后,怎么样能输出一个预测结果呢?
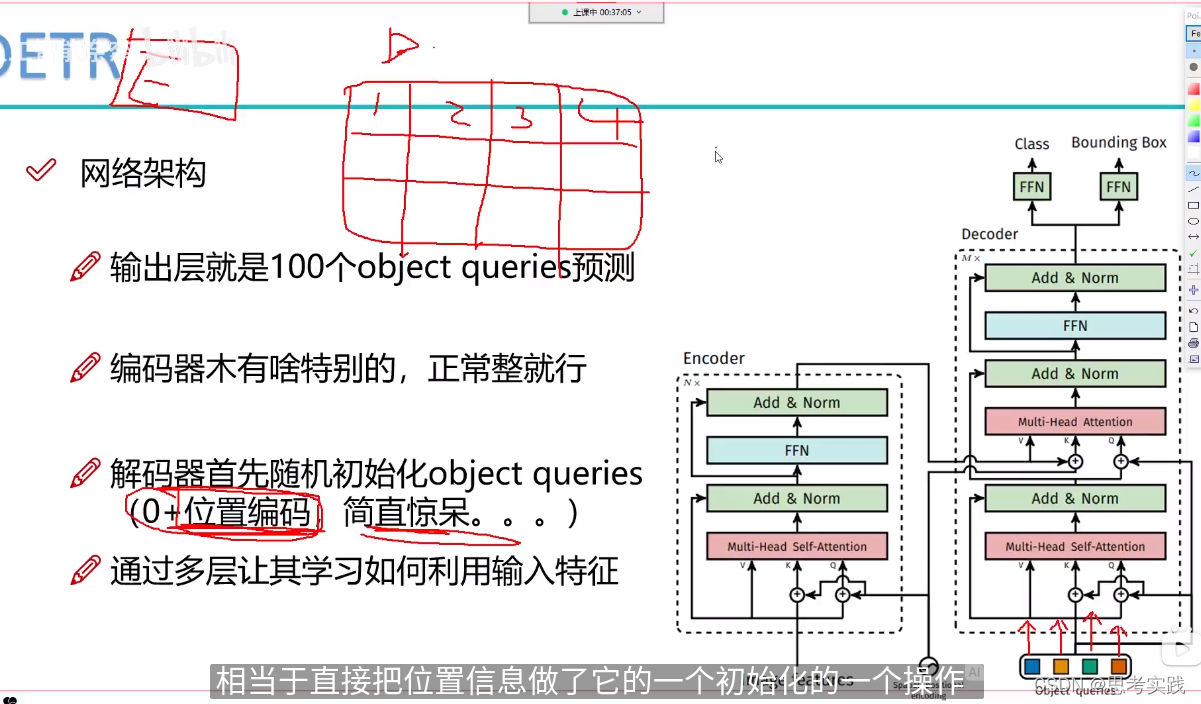
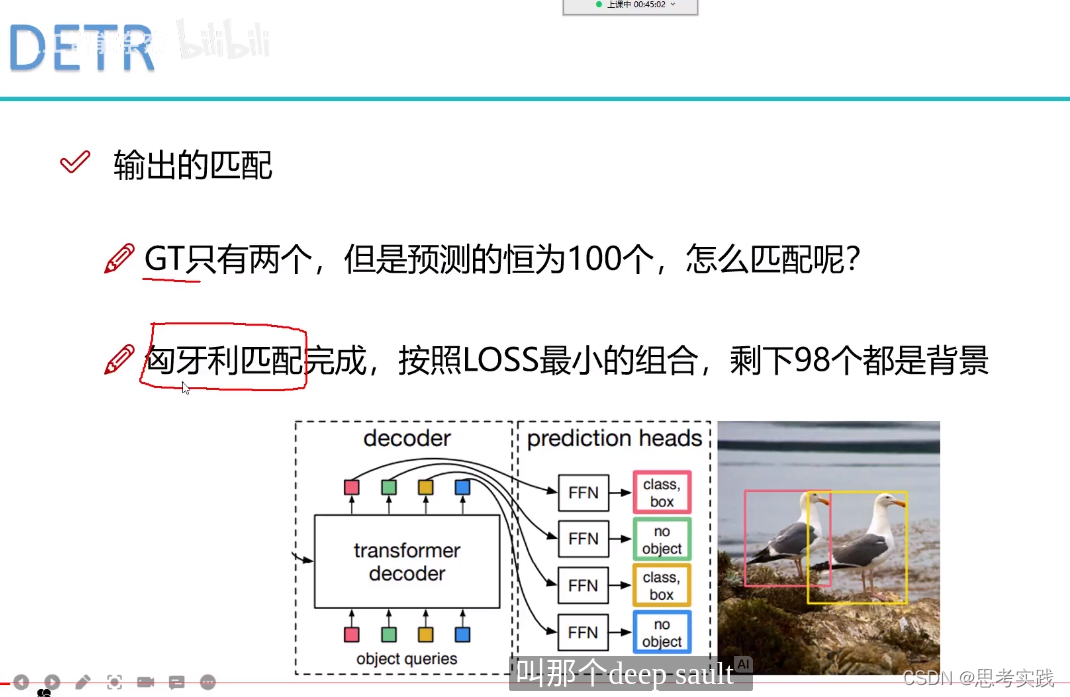
是这样的,一张图像当中大家想象一下最多能有多少个物体呢?一般来说是几个或者十几个(常规来说),再多也不能100多个吧,所以说在这个DETR当中它设了一个限值(这个值可以根据自己任务需求来更改),如果没有特别需求按人家的限制就行。
encoder出来编排好的特征,我就预测100个坐标框。(什么意思呢)

这里两只鸭子就是我们的正样本,剩下的98个预测框都是非物体。
之前的transformer咱们说过可以做机器翻译,因为transformer是(seq2seq+attention)
encoder把特征做好,decoder一个词一个词的翻译,decoder先预测第一个词是什么,基于第一个词去预测第二个词是什么,再基于第二个词预测第三个词,是一种串行结构,今天这个decoder的预测的100个坐标框是并行的不是串行的,同一时间一口气全部预测出来就完事儿了。
今天咱们这个预测与之类似但又不完全相同,
假设我们拿到100个向量 ,每一个向量都可以预测一个坐标框和分类的一个概率值,这不就是我们的检测吗,一个bounding-box回归和一个cls的分类。
预测的时候把非物体再过滤掉,只框出找到的目标物体。
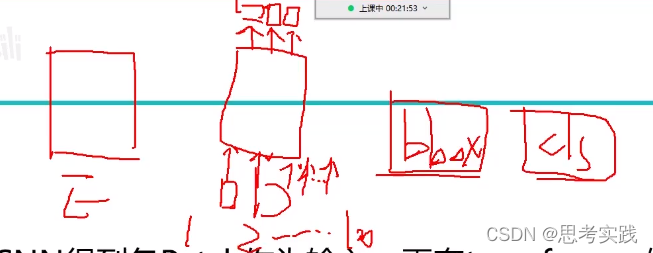
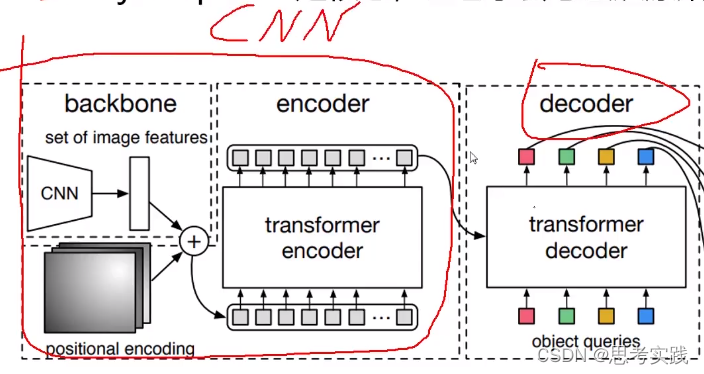
核心图
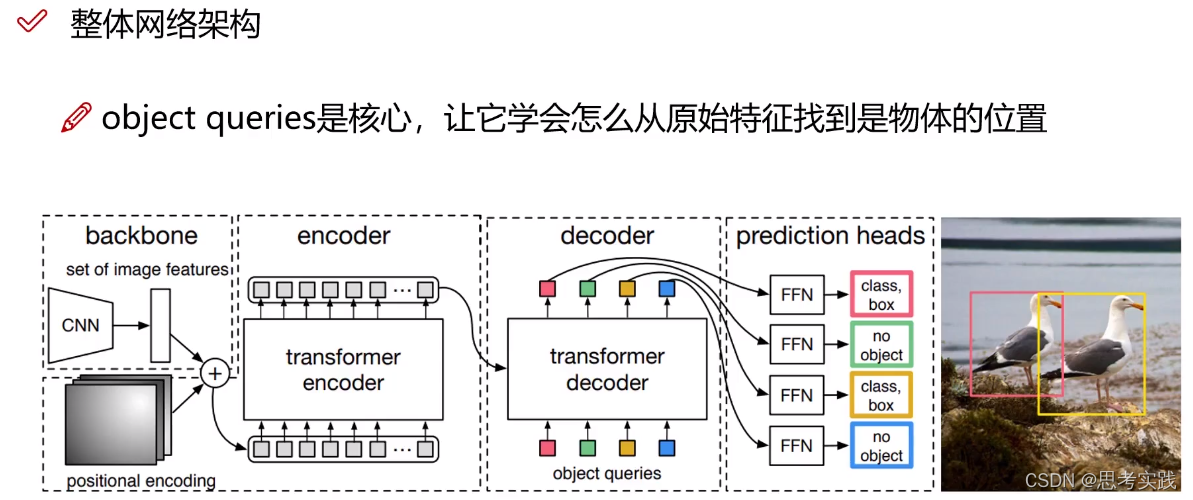
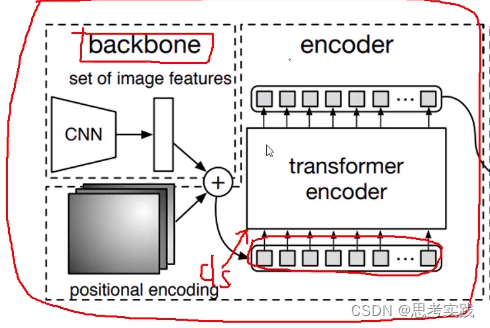
Backbone+p-e+encoder:Vit就多了一个token【cls】分类用的向量(vit也是模仿的bert),DETR就用不到cls了,只是用transformer的encoder做一个特征提取.//这部分除了没有cls几乎和vit一模一样
Decoder: Decoder初始化会initialize 100 个向量,这100个向量要使用encoder生成出来的特征决定每个向量该怎么进行重构,所以transformer-decoder作用是学习这100个向量,这些向量学好了后,每一个向量对应的坐标框所对应的cls结果可以出来。
位置信息初始化query向量
所以DETR最核心的是什么?Object queries,让它学会怎么从原始特征找到物体的位置。
通俗的解释:
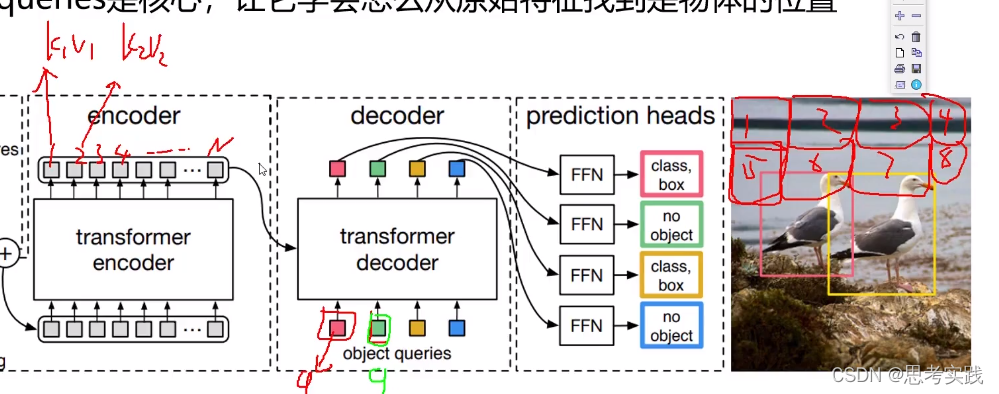
相当于q1,q2,...qm都去问问k1v1,k2v2,...kn,vn这样下去
q1,q2是并行的还是串行的?
这个与一般的机器翻译不一样的,一般nlp里面decoder一般用来生成对话,客服机器人,mt
一般是先有第一个预测结果,然后其会被当成第二次的输入,依次类推···//传统nlp当中的处理方式
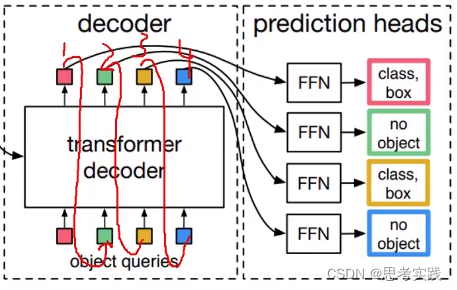
DETR就不需要这个架构了,把传统的decoder改了,把原来串联的结构改为了并联。
并联的意思——(图中4个query都一起去问encoder那个是我的目标),这100个框不是说先有第一个第二个第三个,而是100个框一次全部出来,这是在Decoder当中做的比较有特点的地方。
decoder输出的向量连上FFN(就是全连接层),bbox就是预测4个值,Cls预测80个值就完事了(针对coco数据集)。所以核心是把decoder输出的向量(1,2,3,4)给做好,再用全连接层输出来最终我想要的实际位置以及其对应的类别。
annotation:Feed Forward Network(FFN,前馈神经网络)
提个问题,咱们前面不用transformer作为encoder行不行,直接连个cnn行不行?
拿一个cnn做一个特征提取不也行吗前面为什么非要用transformer作为encoder?
看看论文怎么评价的,

比如告诉解码器,物体在那个地方,红色是物体,蓝色就是背景,凑合看看就行了。
论文当中反复强调一件事情,transformer比cnn好的一个地方在于能让我们的模型更知道我们关注的物体它所在的一个趋势在哪,并且呢遮挡现象也没问题。
这里decoder框出四头牛,剩下97个框重在参与。
论文模型细节架构图
网友(李teacher)自己的分析:未证明,比较通俗的理解(也算一种观点了)
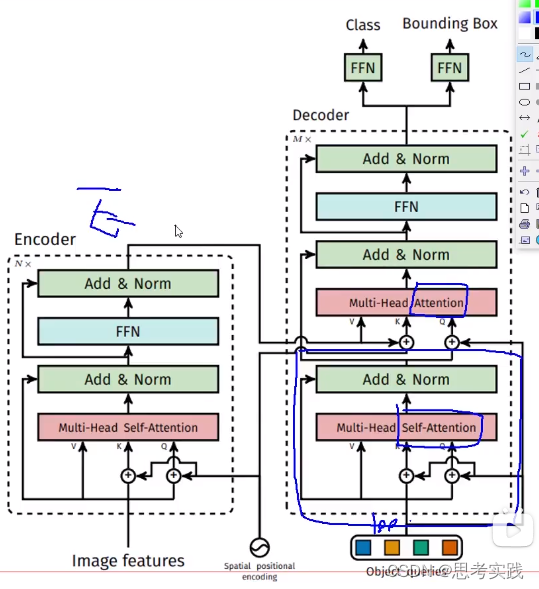
首先蓝色方框框出来的这块没有用到Encoder的信息,自己在玩儿(Multi-Head Self-attention),(以下李teacher的观点,非严密证明)
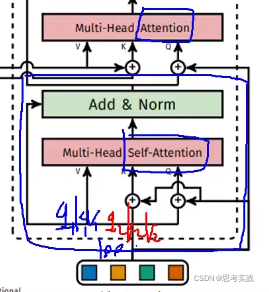
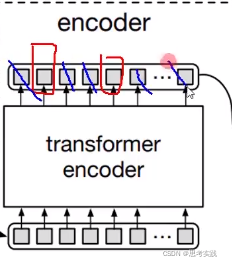
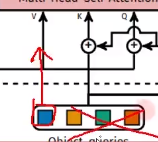
(q1,k1,v1),(q2,k2,v2),...,(q100,k100,v100)第一步他们自己先做一个多头自注意力机制,先分好初始化向量的底盘, 咱一会儿别重了,其工作意义是把100个初始向量query分一分(这里query,value,key都一样),分别把100个query整合一下,把初始向量准备好。
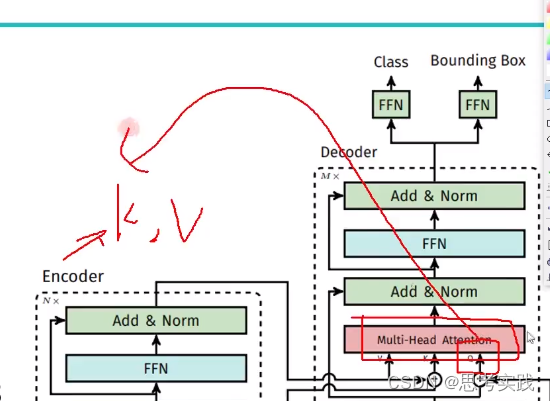
第二步, 多头注意力(不是自注意力),没有Self什么意思呢,由encoder提供(k,v)pair特征,由第一步做完multi-head self-attention 整合的输出作为q,通过这个q去做运算,基于算出的关系(相似度)来重构query,使咱们q做的更好一些,所以整个生命周期都在为这个Query向量服务(一开始 是100个随机初始向量),最后把重构的100个query通过两个FFN去输出Class与Bounding Box
传统的transformer-decoder里面是有mask机制的,17年的《Attention is all you need》,也就是第一个向量要去做attention的时候,后面的向量都要被mask掉,因为机器翻译预测部分你是不知道后面的东西的(虽然attention是能获得全局的,但这样有作弊嫌疑,这样学习到的东西可能适合训练集的预测,在测试集上面表现就可能不好了),而DETR里面就是不需要MASK的,直接往前跑(以前transformer做文本比较多,所以需要Mask机制)
然后就是预测头head部分了
在17年deepsort论文里面做目标跟踪,这里面需要做匹配,因为你要看下一帧目标和上一帧目标是不是一个目标,所以有匹配这个东西。
14-4: 匈牙利算法 Hungarian Algorithm_哔哩哔哩_bilibili
![]()
100个里面选那两个作为最后的预测框呢? 选两个能让Ground-Truth与其之间的损失最小,这个损失可以是iou损失,bounding box,cls损失,可以是多个损失融合在一起,让我们的loss最小就完事儿了。目标追踪算法基本都会匈牙利匹配算法
这里有一个值得关注的地方

Reference//视频看第一个和第二个就可以了,第一个感性认识,第二个实打实的理性认识
干货!2022讲得最清晰的【Transformer核心项目DETR目标检测训练】整体网络架构与注意力机制的作用方法分析解读!transformer模型/深度学习_哔哩哔哩_bilibili
[论文简析]DETR: End-to-End Object Detection with Transfromers[2005.12872]_哔哩哔哩_bilibili
【CODE】Facebook 最新DETR(基于Transformer)目标检测算法实战_哔哩哔哩_bilibili
网络前置任务(Pretext task)和下游任务(downstream tasks) - Learner- - 博客园
vision transformer(detr,vit,deit,swin_哔哩哔哩_bilibili //This dude have a good summary of those models
目标检测之DETR_球场书生的博客-优快云博客 //More points of view

















 3401
3401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









