






使用Python来对有道翻译的结果进行获取,首先进入有道在线翻译首页,F12进入开发者模式。随便翻译一个词语,找到Form Data的部分,这便是我们翻译时提交的数据。
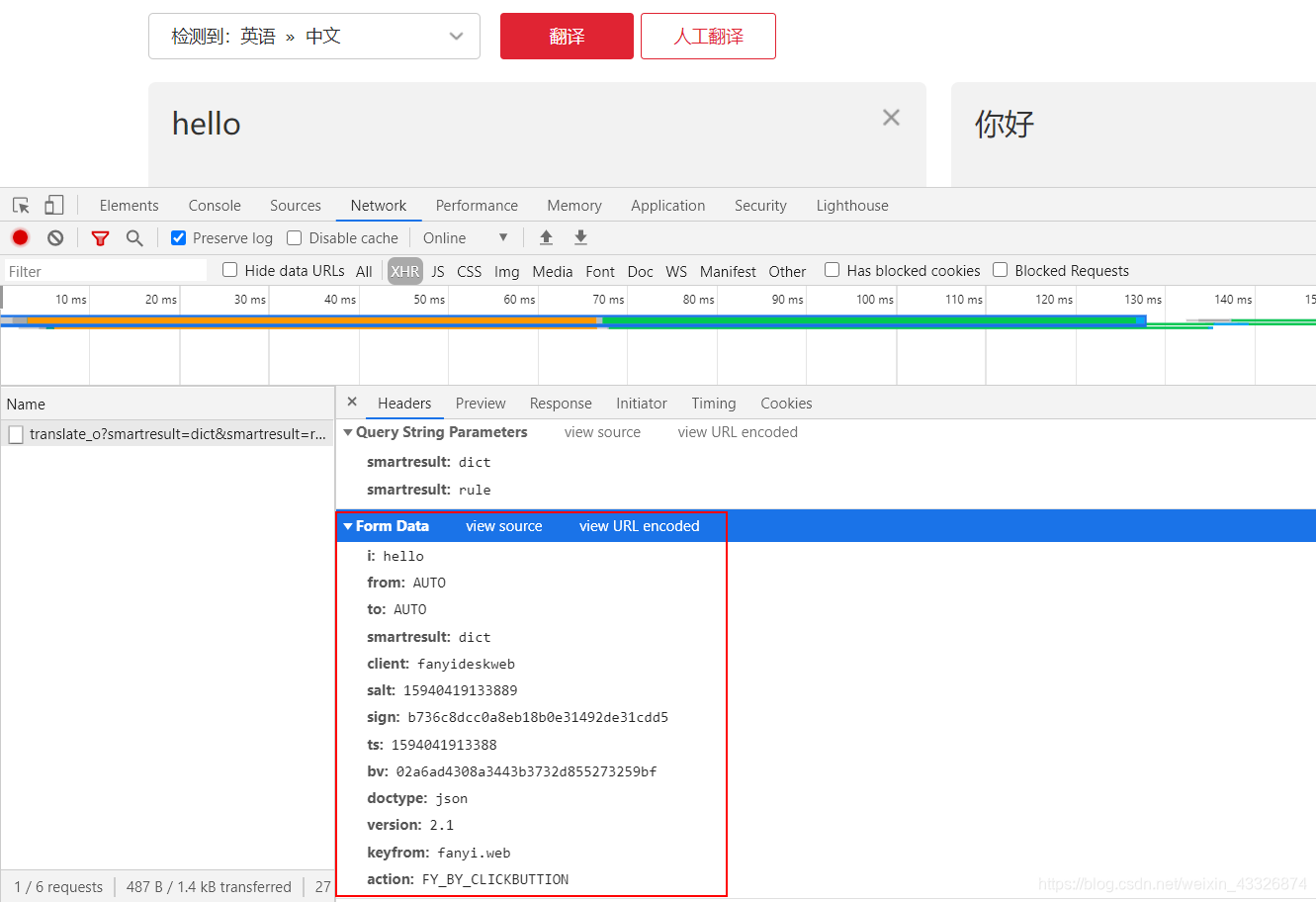
将内容复制后,并且封装为字典(其中key为想要翻译的关键词):
formdata = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "15940419133889",
"sign": "b736c8dcc0a8eb18b0e31492de31cdd5",
"ts": "1594041913388",
"bv": "02a6ad4308a3443b3732d855273259bf",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION"
}
然后封装成数据包:
data = urllib.parse.urlencode(formdata).encode(encoding='utf-8')
发起POST请求:
#自定义请求,需要把data也传进去
req = request.Request(url, data=data, headers=headers)
#返回请求结果
resp = request.urlopen(req).read().decode()
输出resp,观察结果发现"tgt"的值为翻译的结果:
Please enter waht you want to translate:你好
{"type":"ZH_CN2EN","errorCode":0,"elapsedTime":1,
"translateResult":[[{"src":"你好","tgt":"hello"}]]}
通过正则表达式获取"tgt"的值:
pat = r'"tgt":"(.*?)"}]]'
使用re.findall()来筛选返回结果resp中符合pat的内容,即为翻译的结果:
Please enter waht you want to translate:hello
你好
完整代码如下:
# -*- coding:utf-8 -*-
import urllib
from urllib import request
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36"}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
key = input("Please enter waht you want to translate:")
#POST需要提交的数据
formdata = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "15940419133889",
"sign": "b736c8dcc0a8eb18b0e31492de31cdd5",
"ts": "1594041913388",
"bv": "02a6ad4308a3443b3732d855273259bf",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_CLICKBUTTION"
}
data = urllib.parse.urlencode(formdata).encode(encoding='utf-8')
#自定义请求,需要把data也传进去
req = request.Request(url, data=data, headers=headers)
#返回请求结果
resp = request.urlopen(req).read().decode()
#正则表达式,提取'"tgt":"和"}]]'中间的任意内容
pat = r'"tgt":"(.*?)"}]]'
#使用re,查找返回的resp中符合pat的内容,即翻译的结果
result = re.findall(pat, resp)
print(result[0])


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









