




 本文通过具体实例介绍了Numpy的基础使用方法,包括数据的读取、处理与统计分析,并利用Matplotlib进行了数据的可视化展示。
本文通过具体实例介绍了Numpy的基础使用方法,包括数据的读取、处理与统计分析,并利用Matplotlib进行了数据的可视化展示。
从小例子起步-——Numpy的初步使用
程序3-1:
import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],
[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])
row = 0
for line in data:
row += 1
print( row )
print( data.size )
结果:
5
25
程序3-2:
import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],
[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])
print( print( data[0,3]))
print( print( data[0,4]))
结果:
3.0
None
0.0
None
程序3-3:
import numpy as np
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],
[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])
col1 = []#空数据
for row in data:
col1.append(row[0,1])
print( np.sum(col1))#和
print( np.mean(col1))#均值
print( np.std(col1))#标准差
print( np.var(col1))#方差
结果:
935.5
187.1
50.17808286493218
2517.84
图形化数据处理——Matplotlib包的使用
程序3-4:
import numpy as np
import pylab
import scipy.stats as stats
data = np.mat([[1,200,105,3,False],[2,165,80,2,False],
[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])
col1 = []
for row in data:
col1.append(row[0,1])
stats.probplot(col1,plot=pylab)
pylab.show()
结果:
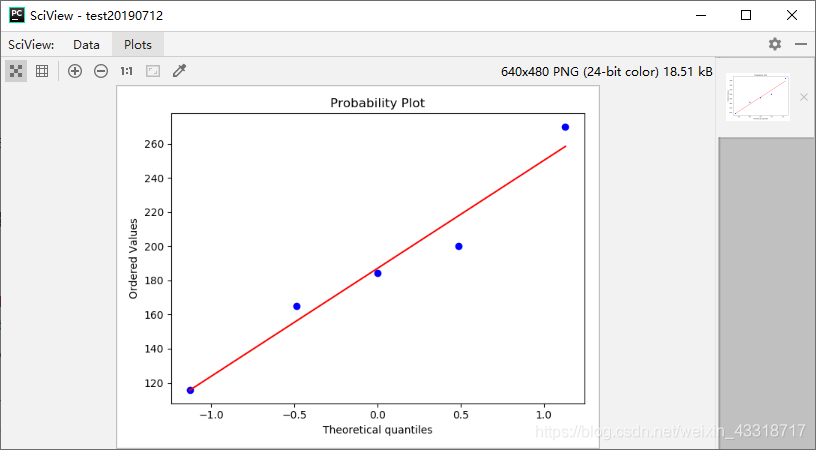
程序3-5:
import pandas as pd
import matplotlib.pyplot as plot
rocksVMines = pd.DataFrame([[1,200,105,3,False],[2,165,80,2,False],
[3,184.5,120,2,False],[4,116,70.8,1,False],[5,270,150,4,True]])
dataRow1 = rocksVMines.iloc[1,0:3]
dataRow2 = rocksVMines.iloc[2,0:3]
plot.scatter(dataRow1, dataRow2)
plot.xlabel("Attribute1")
plot.ylabel(("Attribute2"))
plot.show()
dataRow3 = rocksVMines.iloc[3,0:3]
plot.scatter(dataRow2, dataRow3)
plot.xlabel("Attribute2")
plot.ylabel("Attribute3")
plot.show()
结果:
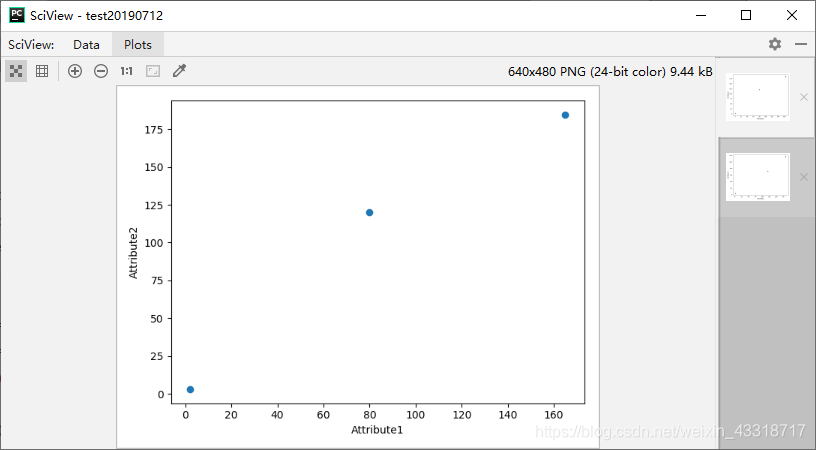
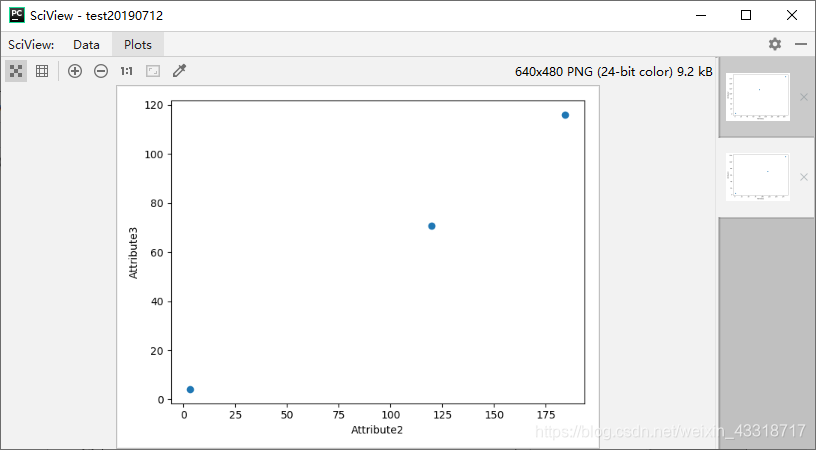
程序3-6:
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
dataRow1 = dataFile.iloc[100, 1:300]
dataRow2 = dataFile.iloc[101, 1:300]
plot.scatter(dataRow1, dataRow2)
plot.xlabel("Attribute1")
plot.ylabel("Attribute2")
plot.show()
结果:
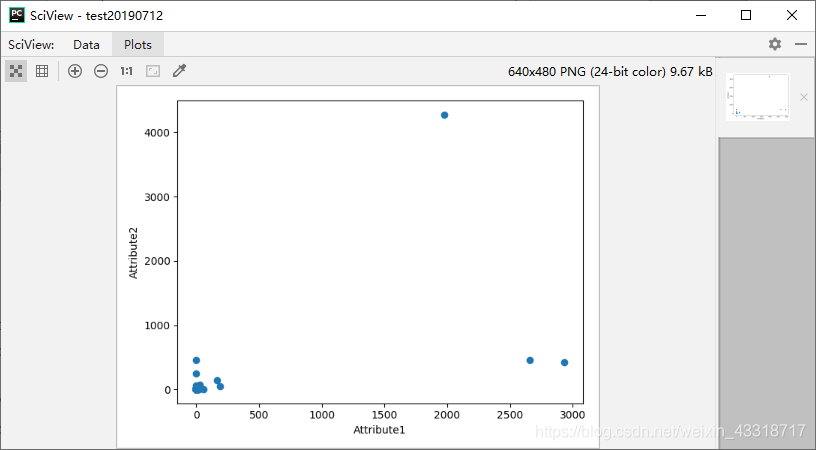
程序3-7:
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
target = []
for i in range(200):
if dataFile.iat[i, 10] >= 7:
target.append(1.0)
else:
target.append(0.0)
dataRow = dataFile.iloc[0:200, 10]
plot.scatter(dataRow, target)
plot.xlabel("Attribute")
plot.ylabel("Target")
plot.show()
结果:
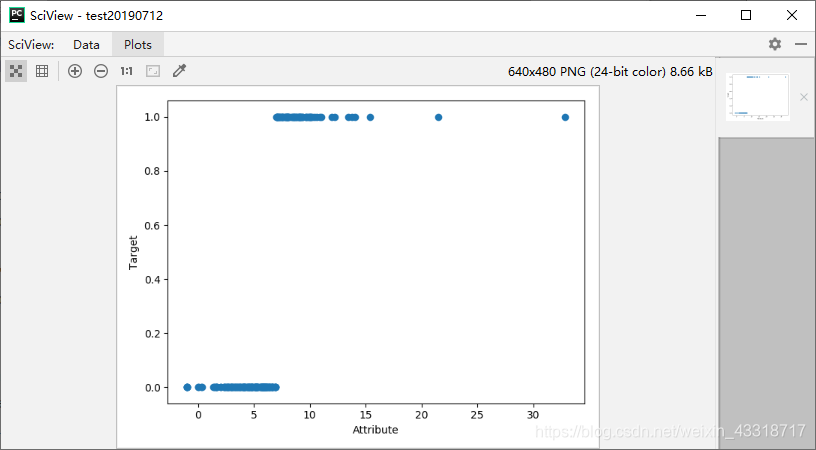
程序3-8:
import pandas as pd
import matplotlib.pyplot as plot
import numpy.random as np
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
target = []
for i in range(200):
if dataFile.iat[i, 10] >= 7:
target.append(1.0 + np.uniform(-0.3, 0.3))
else:
target.append(0.0 + np.uniform(-0.3, 0.3))
dataRow = dataFile.iloc[0:200, 10]
plot.scatter(dataRow, target, alpha=0.5, s=100)
plot.xlabel("Attribute")
plot.ylabel("Target")
plot.show()
结果:
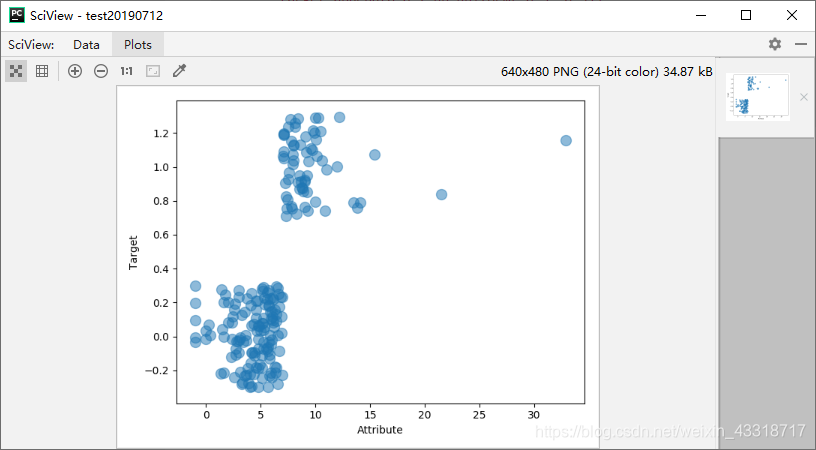
数据的统计学可视化展示
程序3-9:
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
print(dataFile.head())
print((dataFile.tail()))
summary = dataFile.describe()#对数据进行统计学估计
print(summary)
array = dataFile.iloc[:, 10:16].values
boxplot(array)
plot.xlabel("Attribute")
plot.ylabel(("Score"))
show()
结果:
V0 V1 V2 V3 V4 ... V1134 V1135 V1136 V1137 V1138
0 20001 6.15 7.06 5.24 2.61 ... 7 3 6 8 12
1 20002 6.53 6.15 9.85 4.03 ... 7 1 8 1 24
2 20003 8.22 3.23 1.69 0.41 ... 8 8 1 7 6
3 20004 6.79 4.99 1.50 2.85 ... 8 1 6 5 12
4 20005 -1.00 -1.00 -1.00 -1.00 ... 8 1 8 8 1
[5 rows x 1139 columns]
V0 V1 V2 V3 V4 ... V1134 V1135 V1136 V1137 V1138
196 20197 3.59 5.63 6.21 5.24 ... 8 9 8 4 28
197 20198 7.27 5.31 9.35 2.77 ... 8 24 7 8 14
198 20199 6.18 5.05 6.43 6.05 ... 7 3 3 7 4
199 20200 6.12 7.45 1.05 1.03 ... 7 6 8 7 12
200 20201 5.60 6.29 6.11 2.64 ... 8 1 2 7 23
[5 rows x 1139 columns]
V0 V1 V2 ... V1136 V1137 V1138
count 201.000000 201.000000 201.000000 ... 201.000000 201.000000 201.000000
mean 20101.000000 5.266219 6.447015 ... 5.631841 5.572139 16.776119
std 58.167861 2.273933 2.443789 ... 2.510733 2.517145 8.507916
min 20001.000000 -1.000000 -1.000000 ... 1.000000 1.000000 1.000000
25% 20051.000000 4.130000 5.190000 ... 3.000000 4.000000 11.000000
50% 20101.000000 5.240000 6.410000 ... 7.000000 7.000000 17.000000
75% 20151.000000 6.590000 7.790000 ... 8.000000 7.000000 23.000000
max 20201.000000 13.150000 13.960000 ... 8.000000 8.000000 33.000000
[8 rows x 1139 columns]
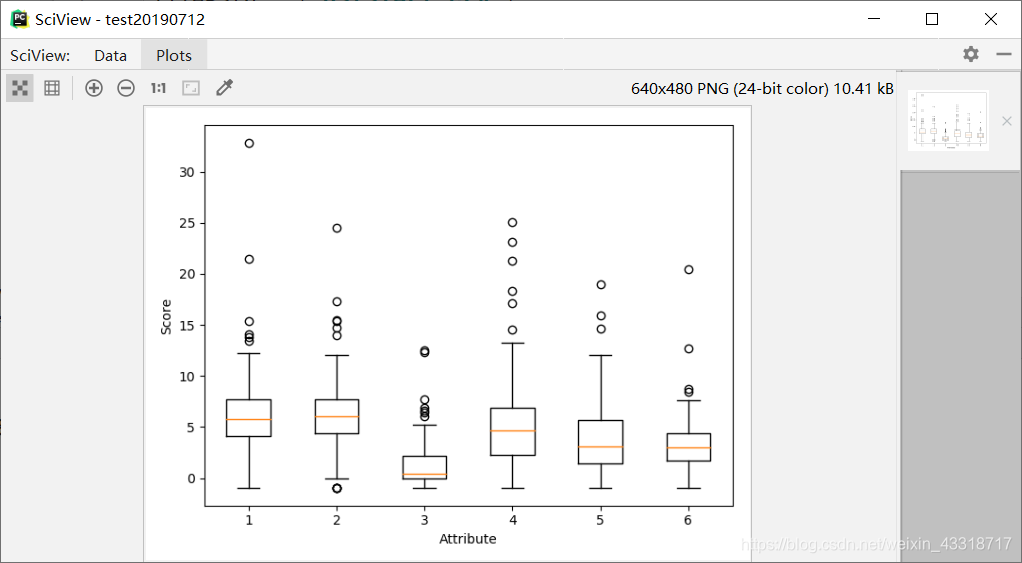
程序3-10:
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
summary = dataFile.describe()
dataFileNormalized = dataFile.iloc[:, 1:6]
for i in range(5):
mean = summary.iloc[1, i]
sd = summary.iloc[2, i]
dataFileNormalized.iloc[:, i:(i + 1)] = (dataFileNormalized.iloc[:, i:(i + 1)] - mean) / sd#标准差标准化
array = dataFileNormalized.values
boxplot(array)
plot.xlabel("Attribute")
plot.ylabel(("Score"))
show()
结果:
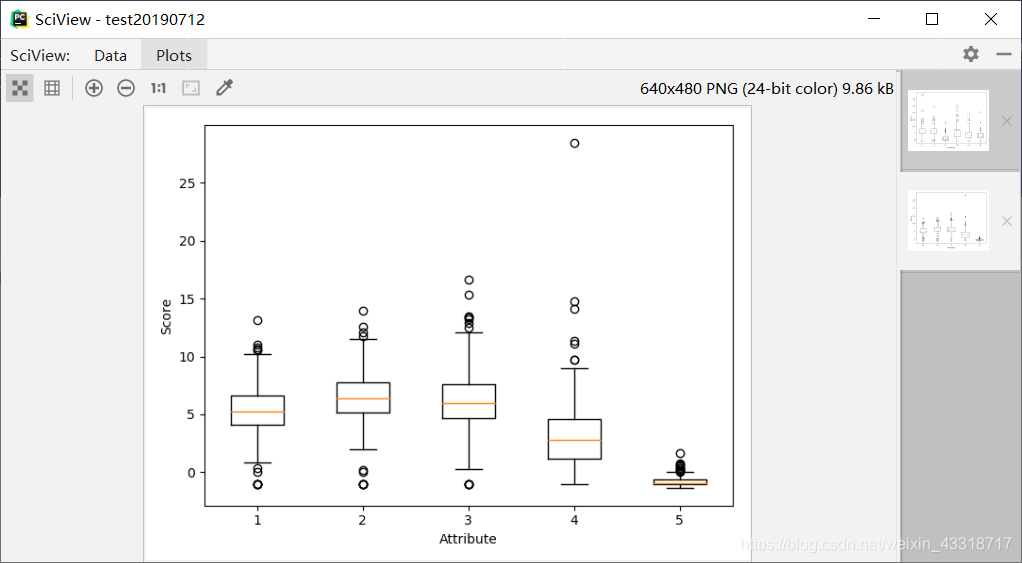
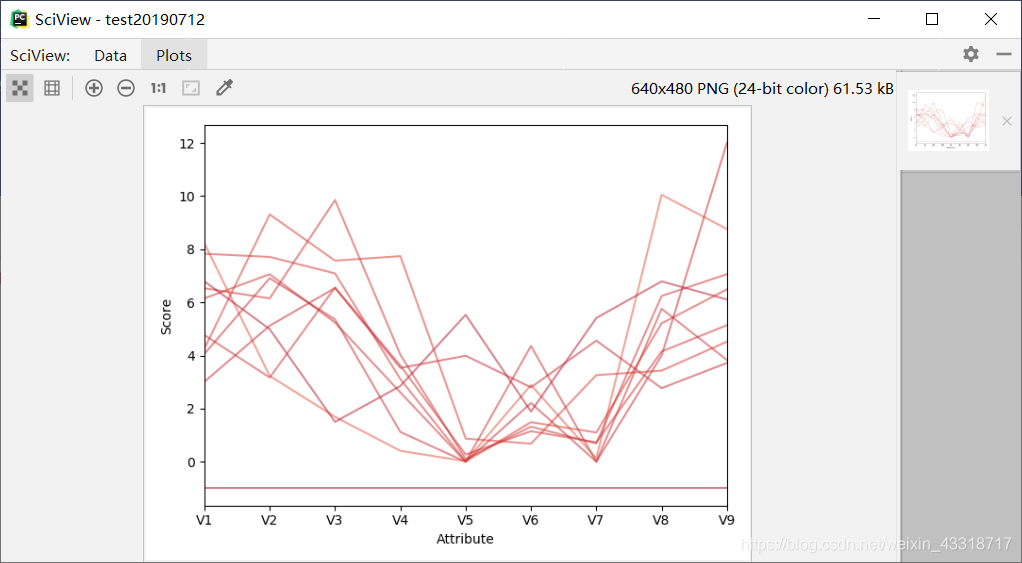
程序3-11:
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
summary = dataFile.describe()
minRings = -1#计算的最小值
maxRings = 99#计算的最大值
nrows = 10#目标行数,前10行
for i in range(nrows):
dataRow = dataFile.iloc[i, 1:10]
labelColor = (dataFile.iloc[i, 10] - minRings) / (maxRings - minRings)
dataRow.plot(color=plot.cm.RdYlBu(labelColor), alpha=0.5)
plot.xlabel("Attribute")
plot.ylabel("Score")
show()
结果:
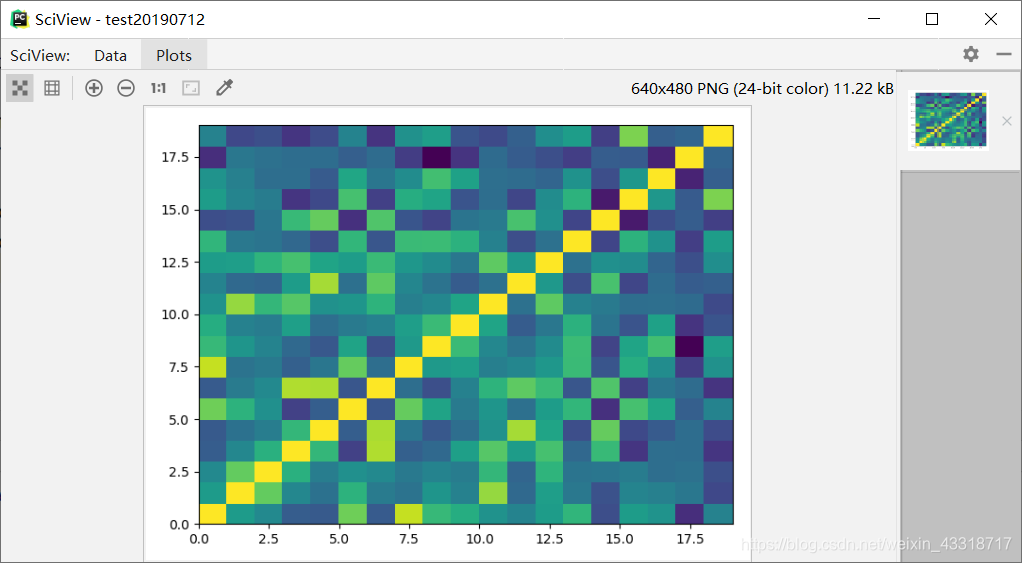
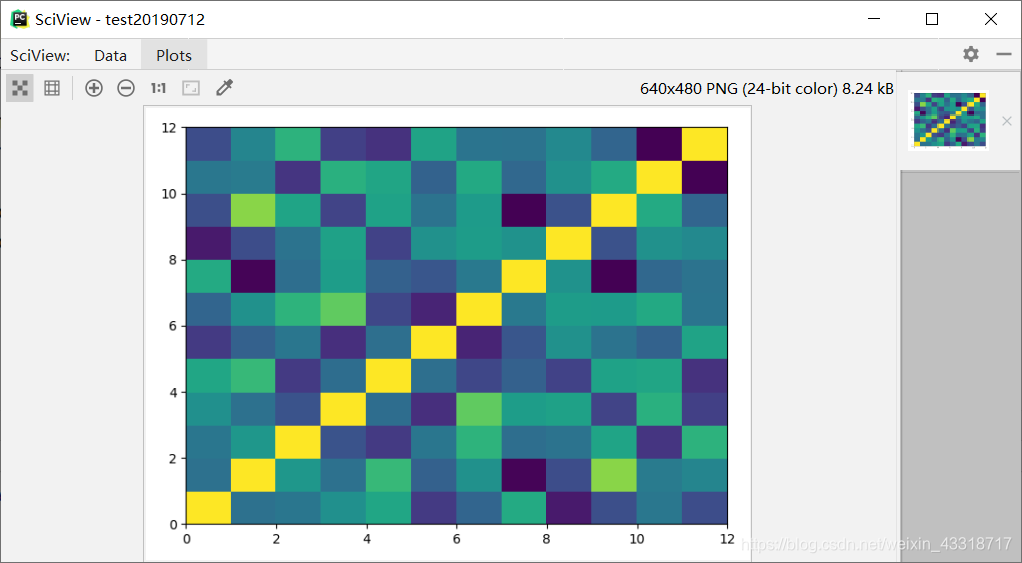
程序3-12:
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath, header=None, prefix="V")
summary = dataFile.describe()
corMat = pd.DataFrame(dataFile.iloc[1:20, 1:20].corr())
plot.pcolor(corMat)
plot.show()
结果:
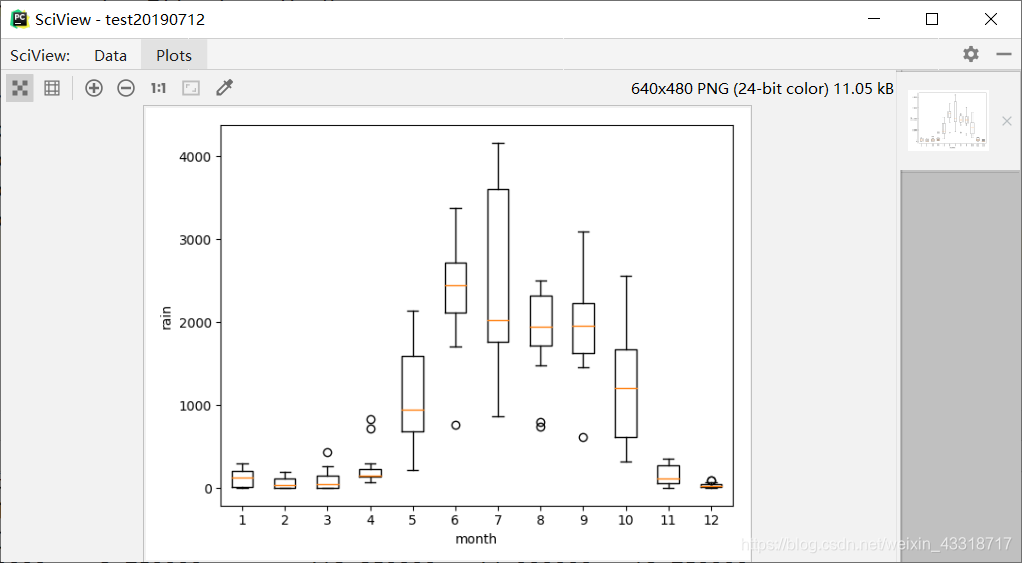
Python数据分析与可视化实战——某地降水的关系处理
程序3-13:
#不同年份的相同月份统计
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("rain.csv")
dataFile = pd.read_csv(filePath)
summary = dataFile.describe()
print(summary)
array = dataFile.iloc[:, 1:13].values
boxplot(array)
plot.xlabel("month")
plot.ylabel(("rain"))
show()
结果:
Unnamed: 0 1 2 ... 10 11 12
count 12.000000 12.000000 12.000000 ... 12.000000 12.000000 12.000000
mean 2005.500000 121.083333 67.833333 ... 1219.250000 159.333333 38.333333
std 3.605551 103.021144 72.148626 ... 743.534938 124.611639 34.494620
min 2000.000000 0.000000 0.000000 ... 328.000000 0.000000 0.000000
25% 2002.750000 17.750000 9.750000 ... 612.250000 64.000000 18.750000
50% 2005.500000 125.000000 39.500000 ... 1208.500000 123.000000 25.500000
75% 2008.250000 204.500000 123.250000 ... 1672.250000 278.250000 46.250000
max 2011.000000 295.000000 192.000000 ... 2561.000000 357.000000 100.000000
[8 rows x 13 columns]
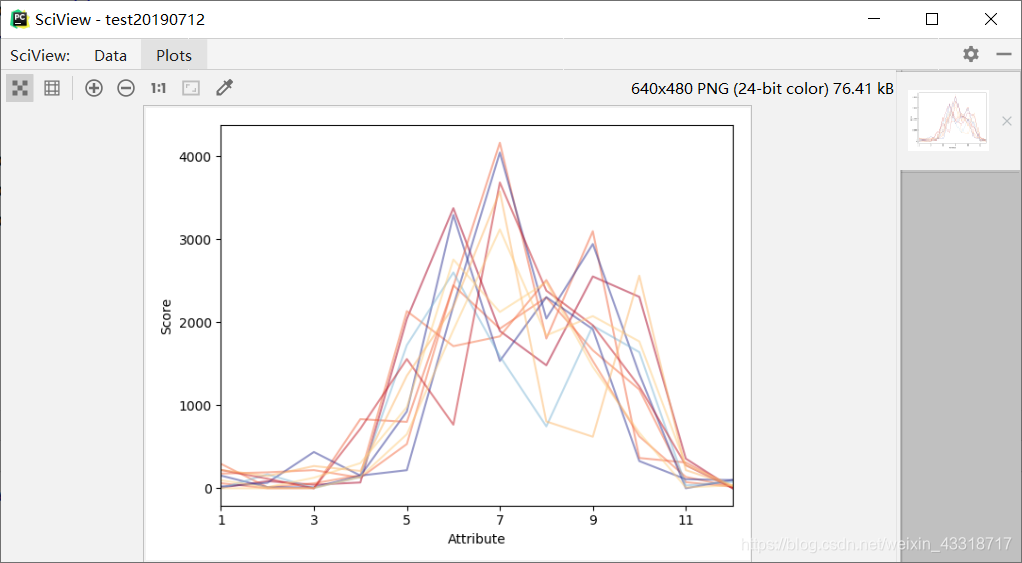
程序3-14:
#不同月份之间的增减程度比较
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("rain.csv")
dataFile = pd.read_csv(filePath)
summary = dataFile.describe()
minRings = -1
maxRings = 99
nrows = 11
for i in range(nrows):
dataRow = dataFile.iloc[i, 1:13]
labelColor = (dataFile.iloc[i, 12] - minRings) / (maxRings - minRings)
dataRow.plot(color=plot.cm.RdYlBu(labelColor), alpha=0.5)
plot.xlabel("Attribute")
plot.ylabel(("Score"))
show()
结果:
程序3-15:
#每月降水是否相关
from pylab import *
import pandas as pd
import matplotlib.pyplot as plot
filePath = ("dataTest.csv")
dataFile = pd.read_csv(filePath)
summary = dataFile.describe()
corMat = pd.DataFrame(dataFile.iloc[1:20, 1:20].corr())
plot.pcolor(corMat)
plot.show()
结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









