







 本文介绍了如何在Windows上的Eclipse环境中开发MapReduce程序,以wordcount为例,详细讲解了新建MapReduce项目、编写Java类、配置Hadoop相关文件、在Eclipse中运行MapReduce程序的步骤,以及遇到的错误和解决方案,如ClassNotFoundException和任务提交失败的问题。
本文介绍了如何在Windows上的Eclipse环境中开发MapReduce程序,以wordcount为例,详细讲解了新建MapReduce项目、编写Java类、配置Hadoop相关文件、在Eclipse中运行MapReduce程序的步骤,以及遇到的错误和解决方案,如ClassNotFoundException和任务提交失败的问题。
本人是在Linux虚拟机上安装的 hadoop 集群,版本3.2.1,在本地 Windows 用 Eclipse 开发 Map/Reduce 程序,并提交到集群运行,我们以经典的 wordcount 为例,演示用 Eclipse 开发 MapReduce 程序,Eclipse 要先配置好 Hadoop 开发环境,如果还没配置好可以先看Eclipse配置Hadooop开发环境。
1、新建MapReduce项目
点击 File --> New --> Project
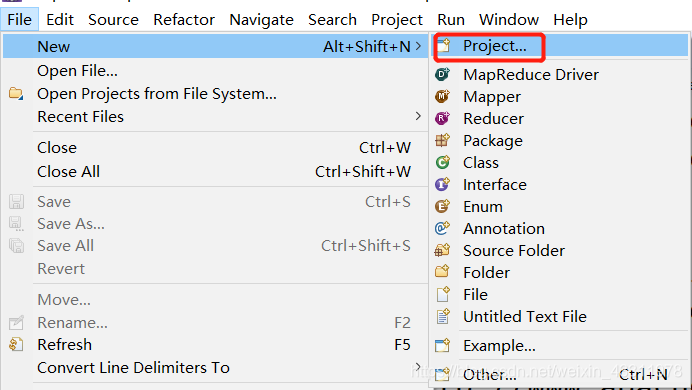
选择 Map/Reduce Project
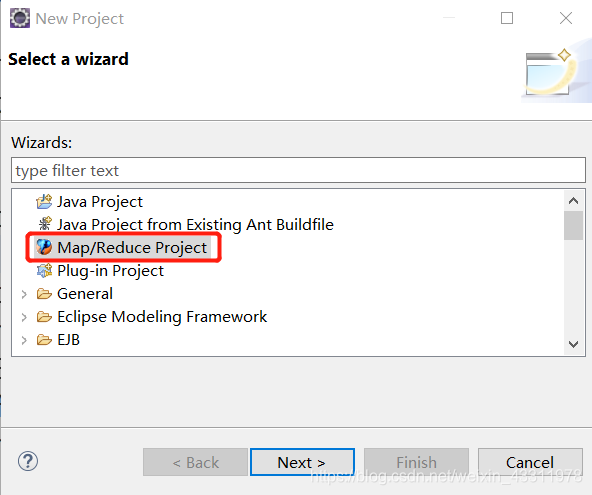
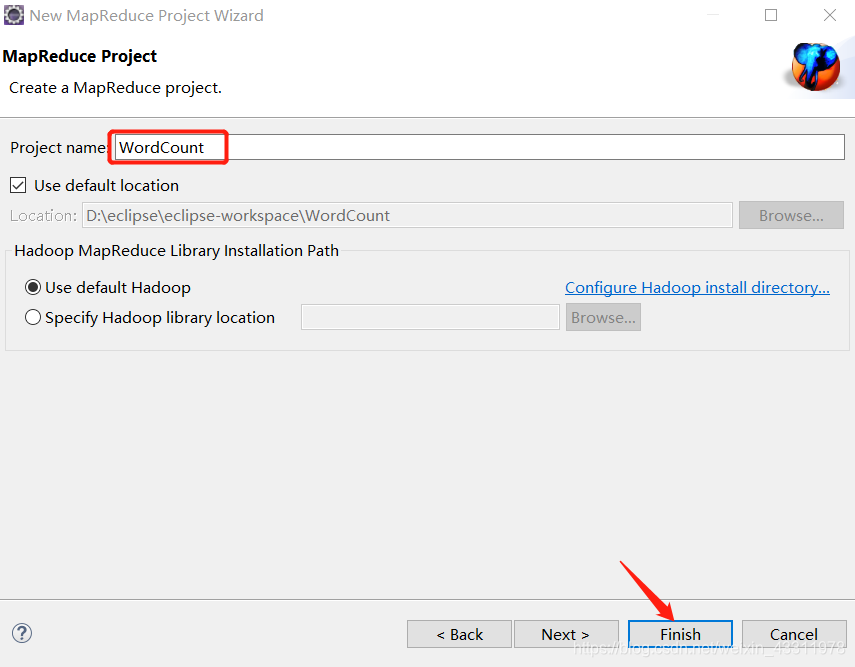
输入项目名字,直接点击 Finish 即可
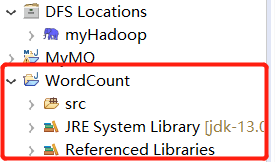
在左侧的 Project Explorer 处就能看到刚才建立的项目
2、新建Class类
New --> Class
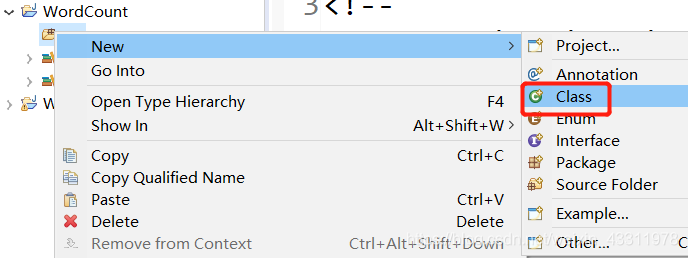
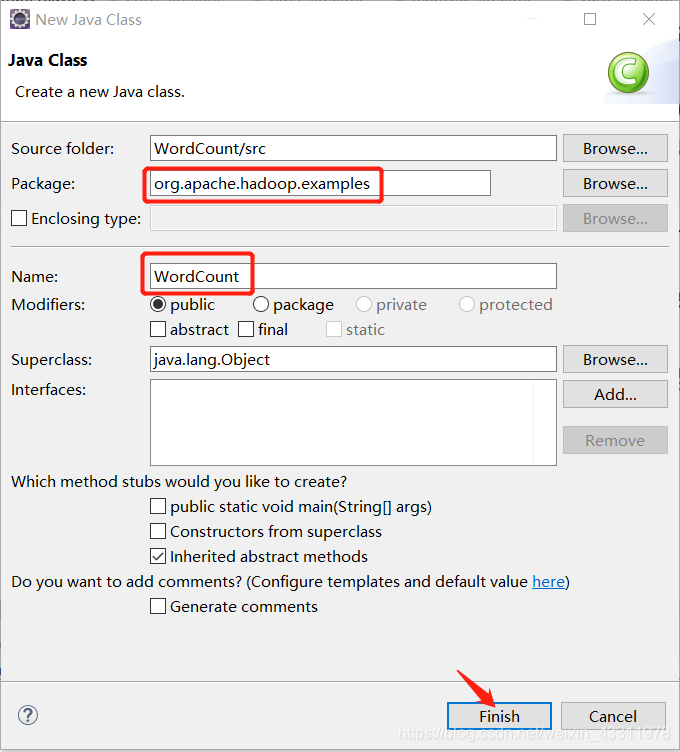
输入包名 org.apache.hadoop.examples 和类名 WordCount,点击 Finish
下面是 wordCount 的代码,将它复制到刚刚建的 Java 文件中
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public WordCount() {
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
// System.out.println(this.word);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i$ = values.i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









