









参照https://blog.youkuaiyun.com/weixin_35756522/article/details/8187653
s2表结构如下:
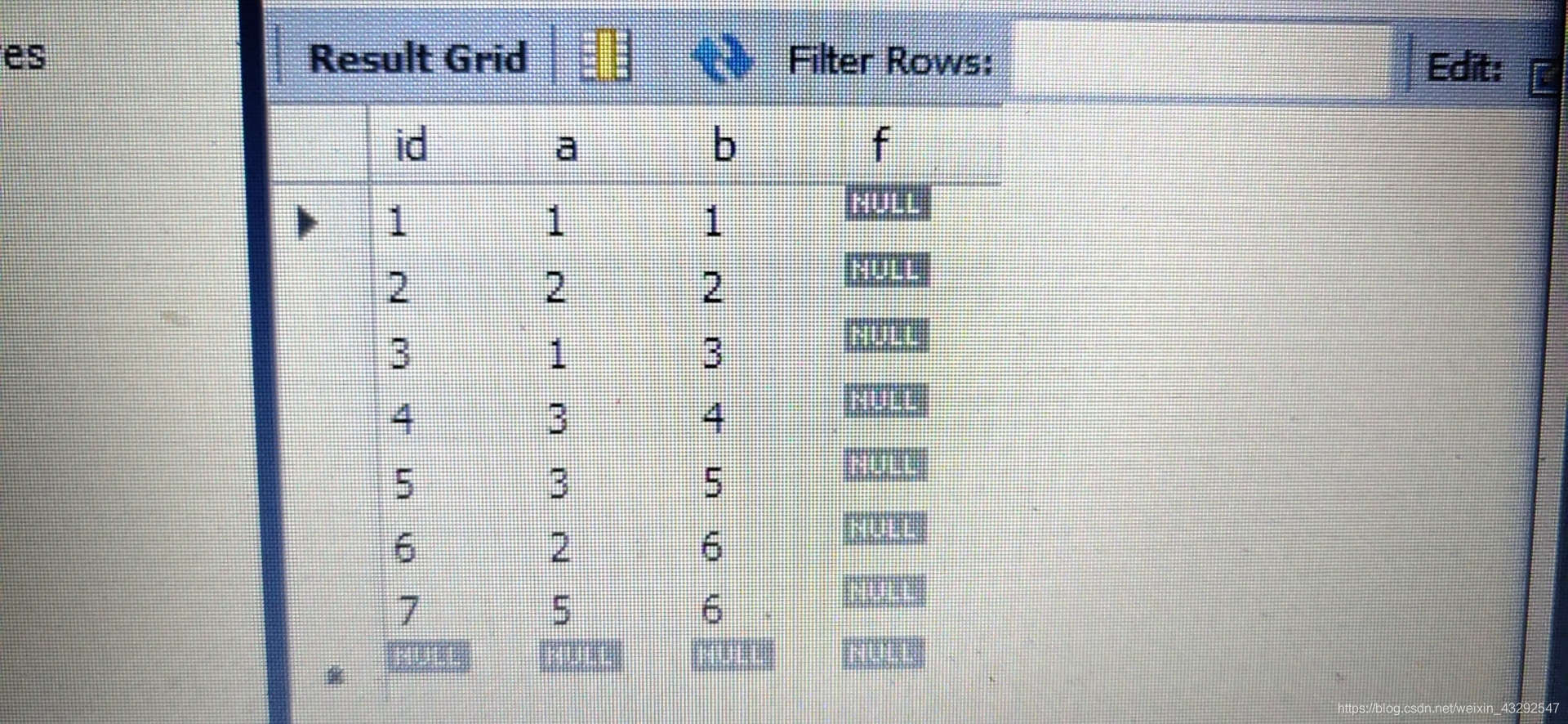
set @a=6;
select @a as _id,(select @a:=a from s2 where id=_id) as pid
from s2 where @a<>1;
或者
select @a as _id,(select @a:=a from s2 where b=_id) as pid #where b=_id可以改成where b=_@a
from (select @a:=6) tmp,s2 where @a<>1;
的查询结果如下图。
第一个语句分两次执行;第二个第三个语句的from (select @a:=6) tmp,s2唯一目的是初始化@a,使它=6,
执行步骤是先where生成7条数据,然后遍历这七条,
首先@a=6,然后子查询发现a=2,返回(6,2)并令@a=2;
之后发现a=2导致@a=2,重复6次,所以得到如下结果。
语句3说明即使@a=6对应a=2和a=5两个值,也始终返回第一个值。
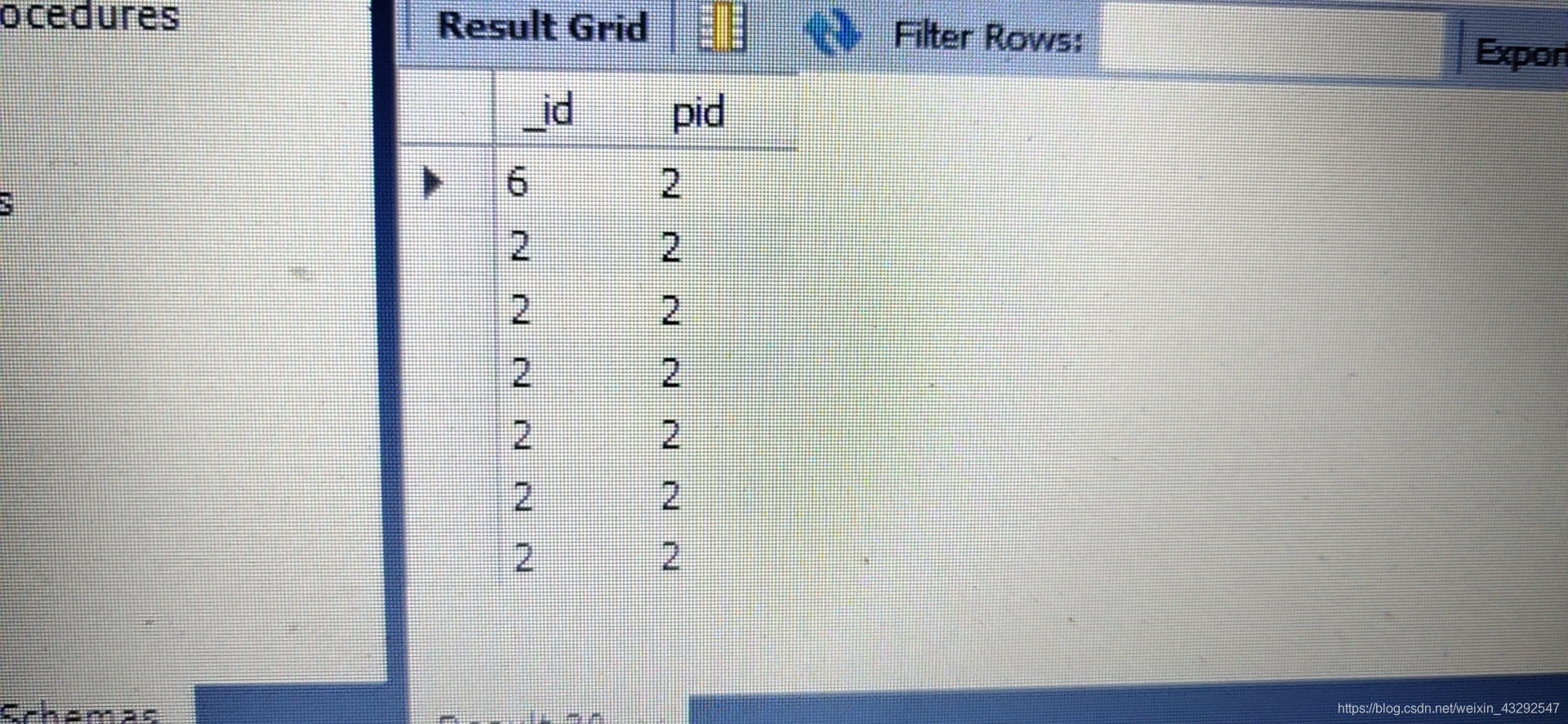
只要把id=6和id=7的a值替换或者令b列值唯一,上面的这些sql可以得到下面图片的结果。
select @a as _id,(select @a:=a from s2 where id=_id) as pid #where id=_id可以改成where id=_@a
from (select @a:=6) tmp,s2 where @a<>1;
或者
select @a as _id,(select @a:=a from (select * from s2 order by b desc,a desc) ttmp where b=_id) as pid
from (select @a:=6) tmp,s2 where @a<>1;
返回结果如下。不同之处在于@a=6先找到a=5,然后找了3次后@a=1,
导致从第4次开始where判断返回false,所以只返回3条数据。
这个语句的执行顺序似乎是先按顺序执行()里的内容,之后就不明白了
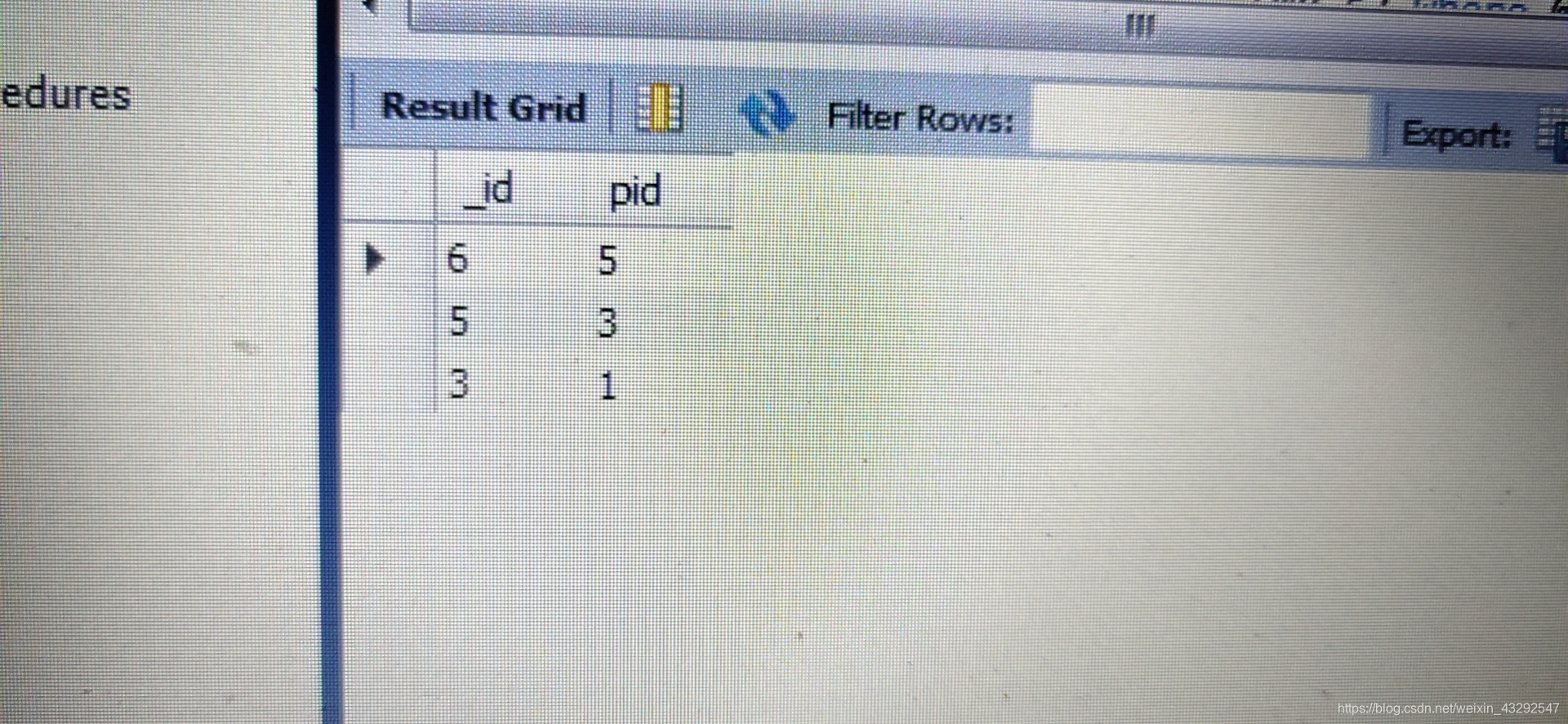
用存储过程查找父节点:
把找到的数据插入临时表。@lastid是为了防止出现死循环。
#SELECT * FROM db1.t1;
drop procedure if exists p1;
delimiter $
create procedure p1(in pid integer)
begin
drop table if exists tt;
CREATE TEMPORARY TABLE tt like t1;
set @lastid=pid,@id=pid;
lp:loop
#select @id;
insert tt select id `id`,@id:=a `a` from t1 where id=@id;
if @id=1 or @id=@lastid then
leave lp;
end if;
set @lastid=@id;
end loop lp;
select * from tt;
end$
delimiter ;
call p1(3);

















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









