 XGBoost算法详解:从原理到参数调优
XGBoost算法详解:从原理到参数调优








 XGBoost是一种优化的梯度增强算法,通过不断添加树来提高预测模型性能。其损失函数包括MSE或对数损失,目标函数含有正则化项以防止过拟合。XGBoost支持对缺失值处理,并有多种策略选择分裂点。它还具有正则化参数γ和λ,以及sklearn参数如objective和eval_metric,常用于分类和回归问题。
XGBoost是一种优化的梯度增强算法,通过不断添加树来提高预测模型性能。其损失函数包括MSE或对数损失,目标函数含有正则化项以防止过拟合。XGBoost支持对缺失值处理,并有多种策略选择分裂点。它还具有正则化参数γ和λ,以及sklearn参数如objective和eval_metric,常用于分类和回归问题。
算法原理
XGBoost(eXtreme Gradient Boosting)是工业界逐渐风靡的基于GradientBoosting算法的一个优化的版本,可以给预测模型带来能力的提升。其算法思想就是不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。
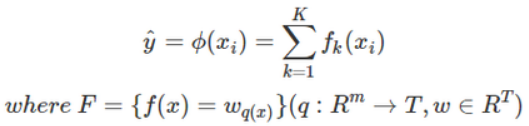
注:w_q(x)为叶子节点q的分数,f(x)为其中一棵回归树
损失函数
对于回归问题,我们常用的损失函数是MSE,即:
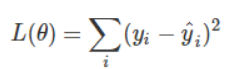
对于分类问题,我们常用的损失函数是对数损失函数:

XGBoost目标函数定义为:
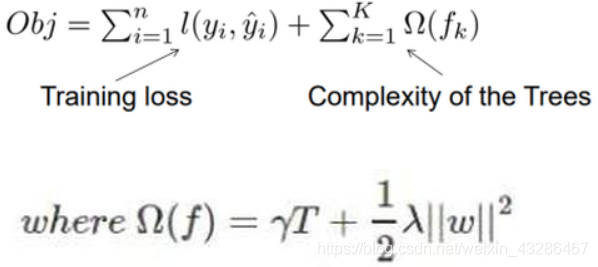
目标函数由两部分构成,第一部分用来衡量预测分数和真实分数的差距,另一部分则是正则化项。正则化项同样包含两部分,T表示叶子结点的个数,w表示叶子节点的分数。γ可以控制叶子结点的个数,λ可以控制叶子节点的分数不会过大,防止过拟合。
正如上文所说,新生成的树是要拟合上次预测的残差的,即当生成t棵树后,预测分数可以写成:
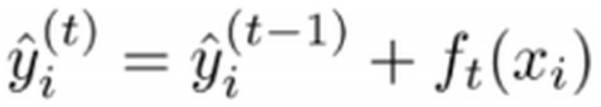
同时,可以将目标函数改写成:
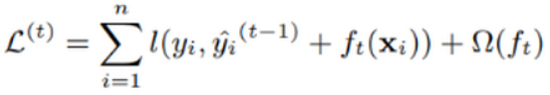
很明显,我们接下来就是要去找到一个f_t能够最小化目标函数。XGBoost的想法是利用其在f_t=0处的泰勒二阶展开近似它。所以,目标函数近似为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









