







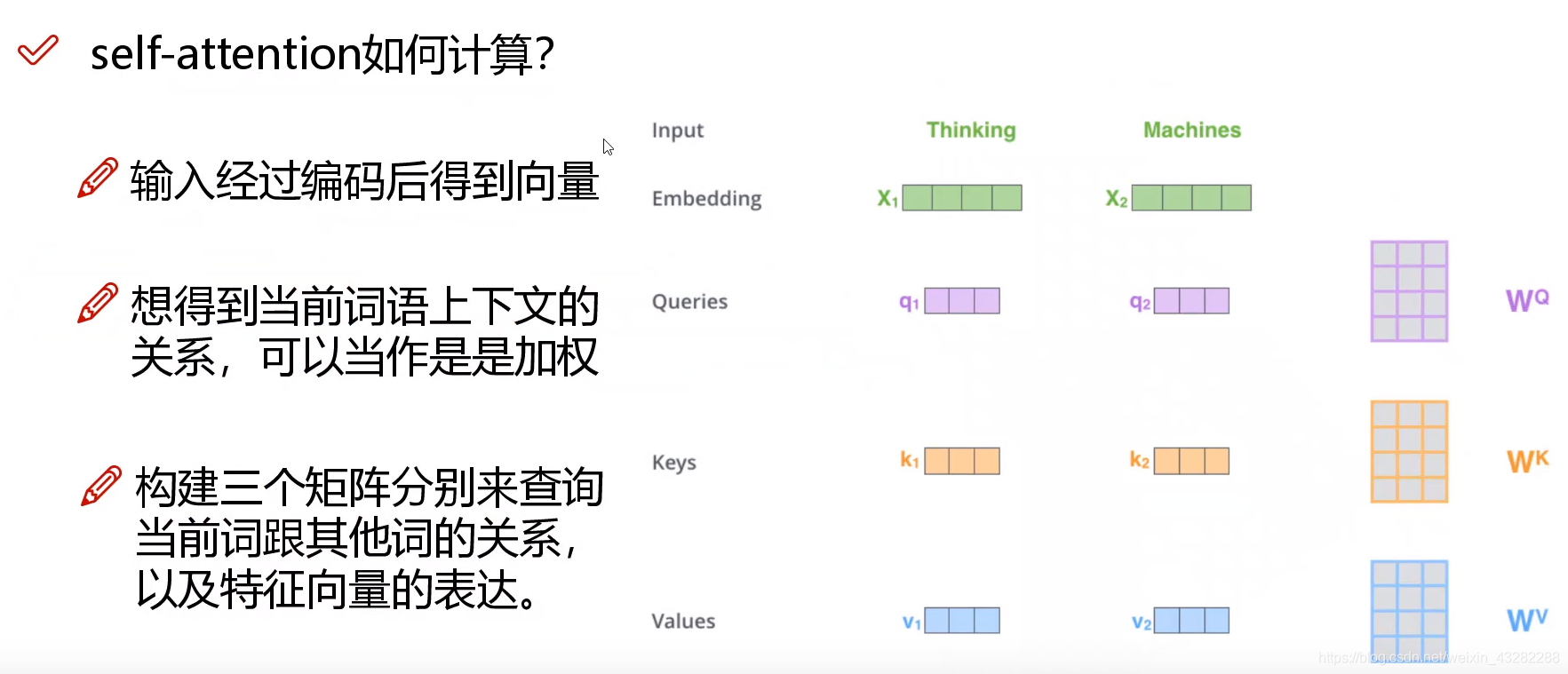
三个矩阵
首先,Inputs为x1~x4,是一个sequence,每一个Input先通过一个Embedding,乘上一个Matrix得到(a1,a4),然后放入self-attention
在self-attention当中,每一个Input都分别乘上3个不同的Matrix产生3个不同的Vector,分别命名为q,k,v

q代表query,to match others,每一个Input都乘上一个Matrix Wq,就得到q1~q4,叫做query
k代表key,to be matched计算同上
v就是要被抽取出来的information,计算同上

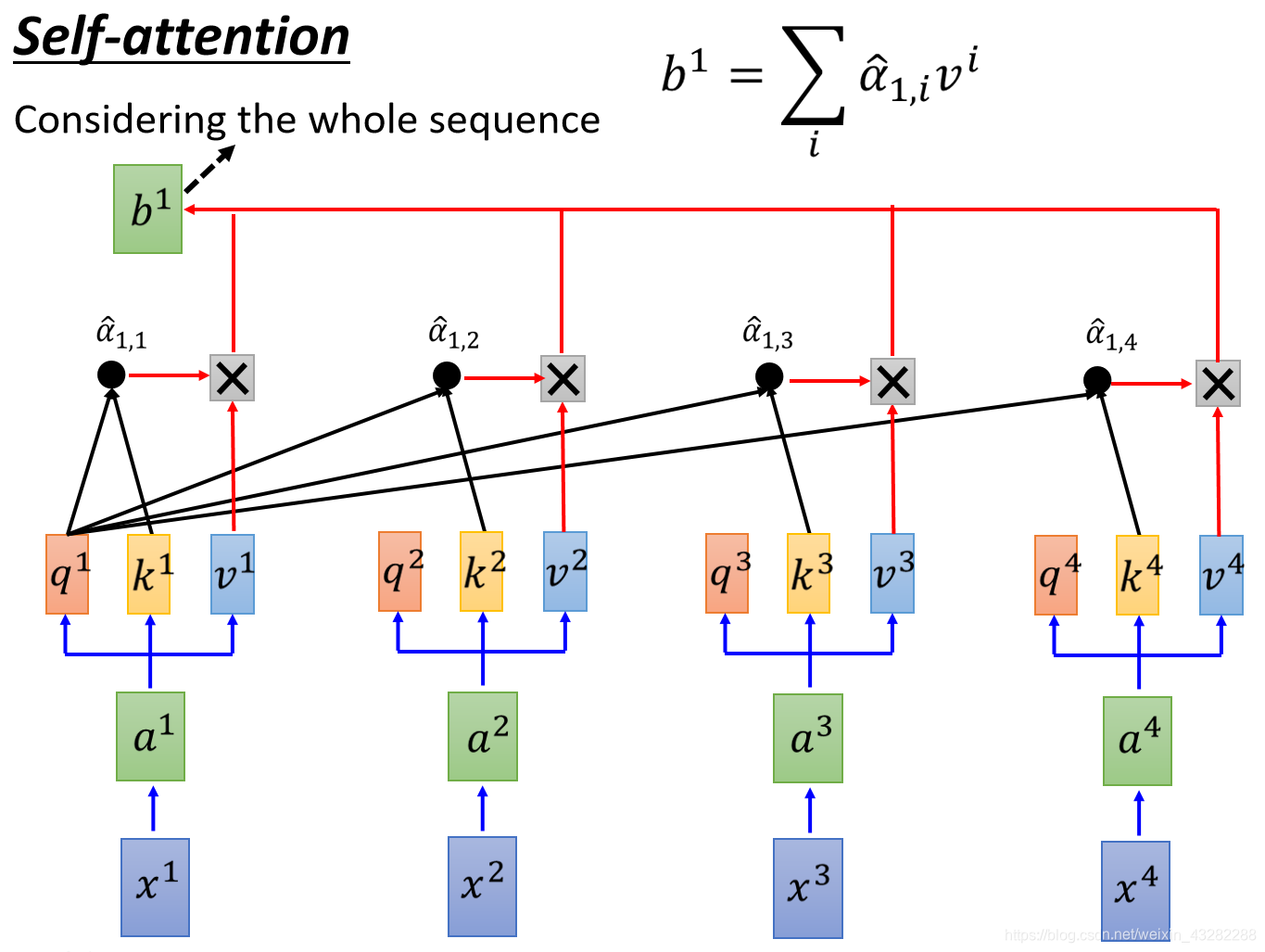
现在,每一个a都有qkv3个不同的Vector,接下来,拿每一个query q,去对每一个key k去做attention
attention简单来说就是输入2个向量,out一个分数 先看q1,对k1做attention,得到α1,1
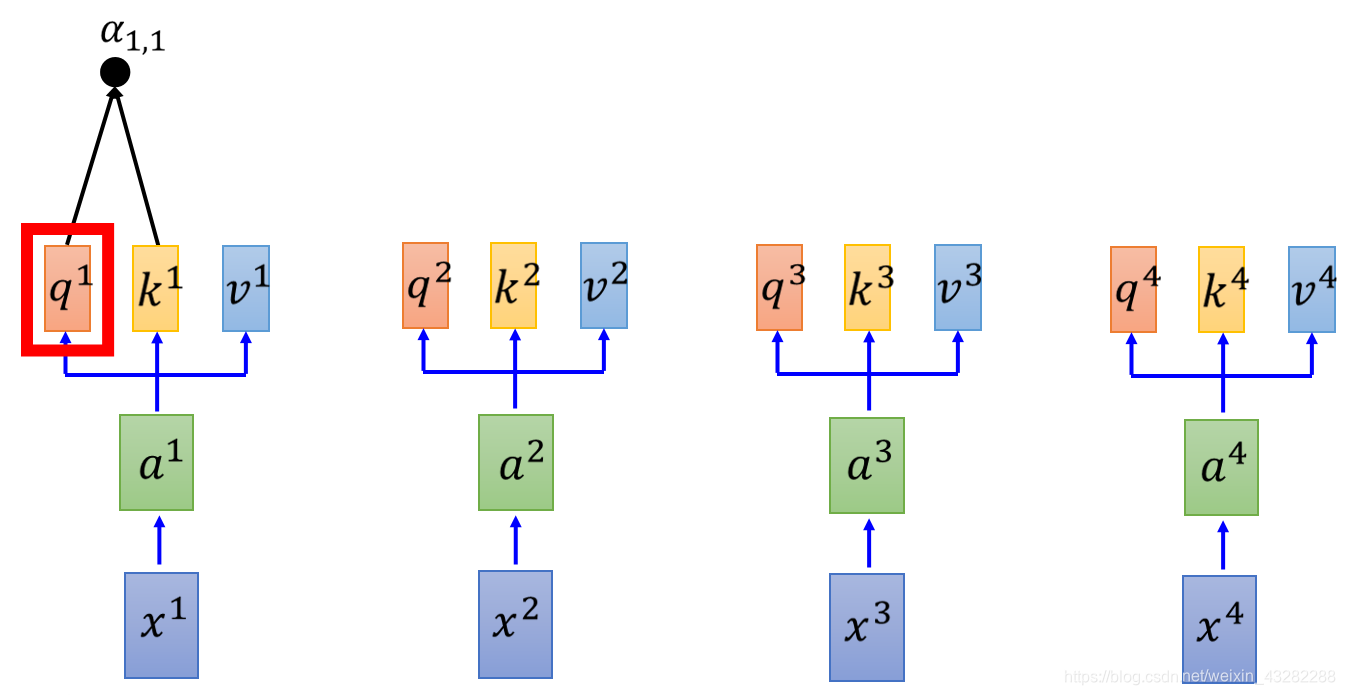
同理得到α1,2,α1,3,α1,4,至此得到了q1对k1,2,3,4的attention,d为q与k的Dimension(维度),因为q与k做点乘,所以维度越大,算出来的值越大。
前面说过attention是输入2个Vector,输出1个out分值,不能让分值随向量维度的增大而增大,softmax之后会导致梯度消失,所以要先进行一个缩放。
也可以尝试用其他的attention,不一定要用Dot-Product Attention
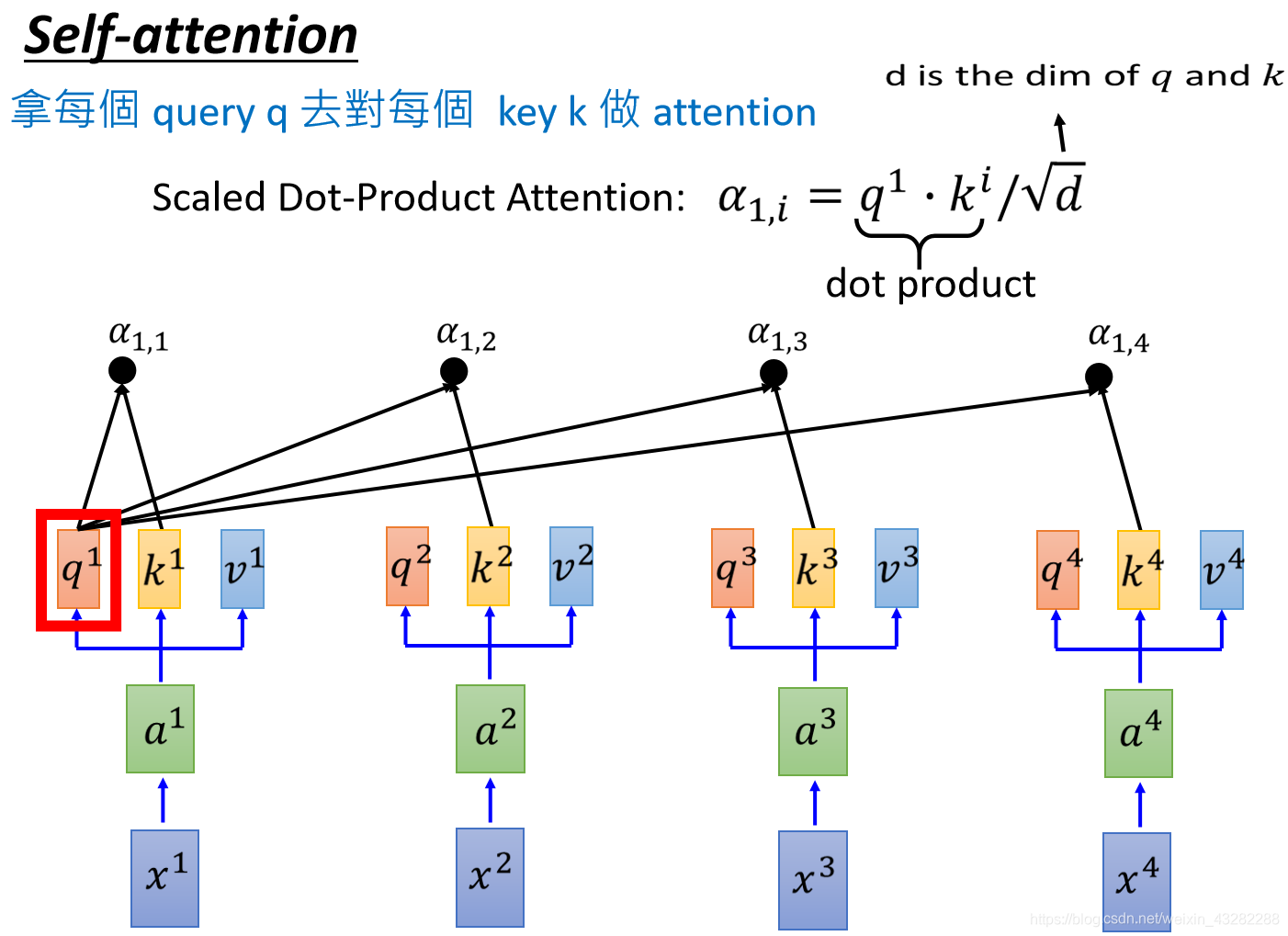
接下来将得到的α1,1~α1,4通过一个softmax层得到 α ^ \hat α α^
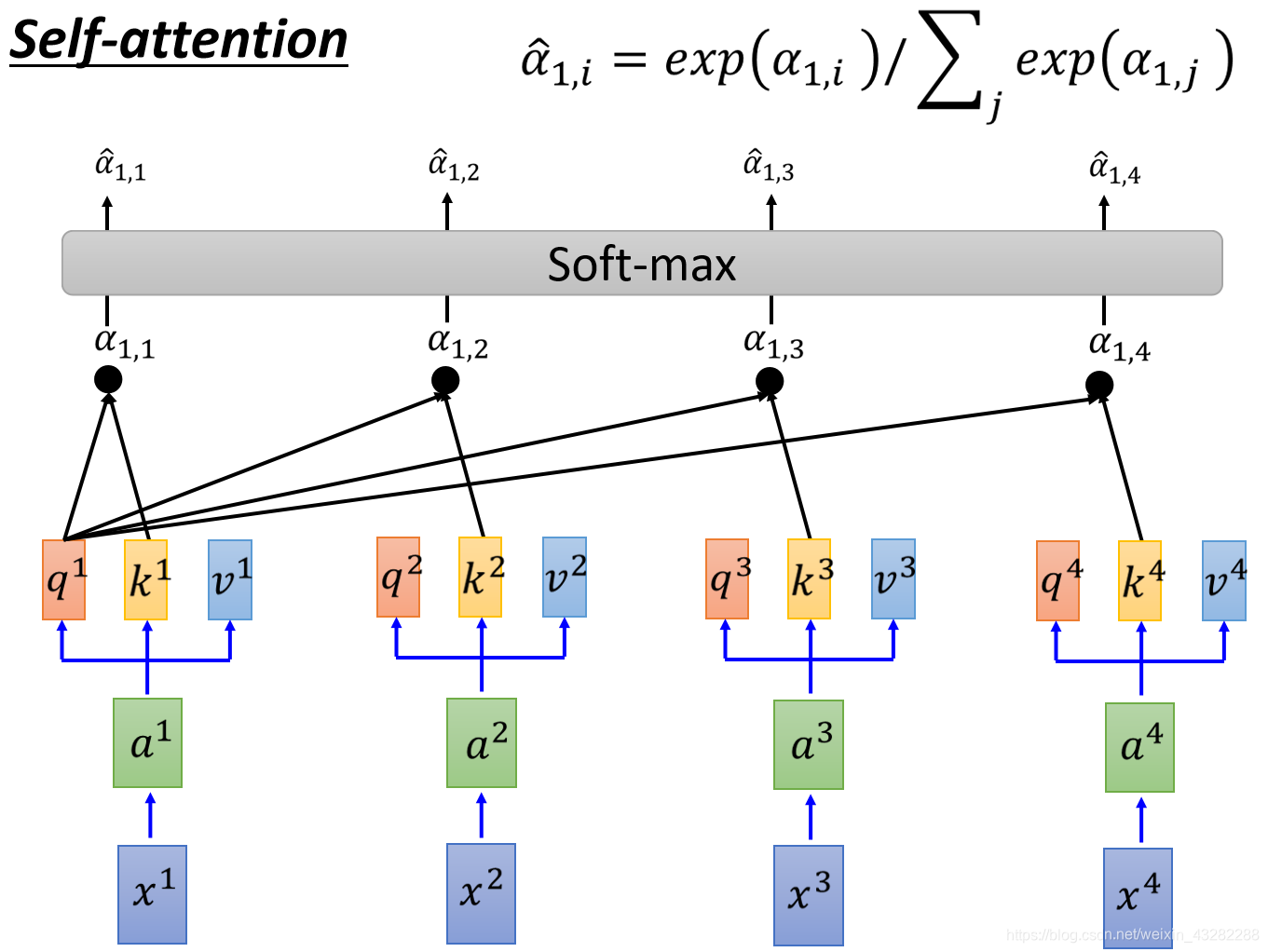
然后拿 α ^ \hat α α^去和每一个v相乘,得到的Vector加起来,就得到了一个Vector,这个Vector就是b1
self-attention输入是一个sequence,输出也是一个sequence,现在得到了输出的seq的第一个Vector b1,此时可以知道,产生b1的时候,已经看到了a1~a4的词序
如果产生b1的时候不想考虑整个句子的词序,只想考虑local的information,只需要让 α ^ \hat α α^234产生出来的值变为0,就可以只考虑local的information
而如果要考虑最远的x4产生的影响,只需要让 α ^ \hat α α^4有值就可以了
刚刚算出来了b1,在同时也可以算b2,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









