







字符串的基本概念
串的基本概念:串(字符串的简称)是由零个或多个字符组成的有限序列。字符可以是数字、字母、下划线。字符串是编程语言中表示文本的数据类型。
-
串中所含字符的个数成为该串的长度(或串长)
-
含零个字符的串(即:"")称为空串,用Ф表示,空串不包含任何字符。
-
串的逻辑表示:“a1a2…an”,双引号不是串的内容,起标识作用,ai(1≤i≤n)代表一个字符。
-
串相等:两个串的长度相等并且各个对应位置上的字符都相同时。如:“abcd” ≠ “abc”、“abcd” ≠ “abcde”、“abc” = “abc”,所有空串是相等的。
-
子串:一个串中任意个连续字符组成的子序列(含空串)称为该串的子串。
例如, “abcde”的子串有:
“”、“a”、“ab” 、“abc”、“abcd”和“abcde”等
真子串是指不包含自身的所有子串。
串抽象数据类型=逻辑结构+基本运算(运算描述),通常以串的整体作为操作对象,如:在串中查找某个子串、求取一个子串、在串的某个位置上插入一个子串以及删除一个子串等。串的基本运算如下:
- StrAssign(&s,cstr):将字符串常量cstr赋给串s,即生成其值等于cstr的串s。
- StrCopy(&s,t):串复制。将串t赋给串s。
- StrEqual(s,t):判串相等。若两个串s与t相等则返回真;否则返回假。
- StrLength(s):求串长。返回串s中字符个数。
- Concat(s,t):串连接:返回由两个串s和t连接在一起形成的新串。
- SubStr(s,i,j):求子串。返回串s中从第i(1≤i≤n)个字符开始的、由连续j个字符组成的子串。
- InsStr(s1,i,s2):插入。将串s2插入到串s1的第i(1≤i≤n+1)个字符中,即将s2的第一个字符作为s1的第i个字符,并返回产生的新串。
- DelStr(s,i,j):删除。从串s中删去从第i(1≤i≤n)个字符开始的长度为j的子串,并返回产生的新串。
- RepStr(s,i,j,t):替换。在串s中,将第i(1≤i≤n)个字符开始的j个字符构成的子串用串t替换,并返回产生的新串。
- DispStr(s):串输出。输出串s的所有元素值。
字符串的存储结构
串的两种最基本的存储方式是顺序存储方式和链接存储方式。
顺序存储
串的顺序存储(顺序串)有两种方法:
- 每个单元(如4个字节)只存一个字符,称为非紧缩格式(其存储密度小)。
- 每个单元存放多个字符,称为紧缩格式(其存储密度大)。
顺序串基本运算的算法
#include <stdio.h>
#define MaxSize 100
typedef struct
{
char data[MaxSize];
int length; //串长
} SqString;
void StrAssign(SqString &s,char cstr[]) //字符串常量赋给串s
{
int i;
for (i=0;cstr[i]!='\0';i++)
s.data[i]=cstr[i];
s.length=i;
}
void DestroyStr(SqString &s) //销毁串
{ }
void StrCopy(SqString &s,SqString t) //串复制
{
int i;
for (i=0;i<t.length;i++)
s.data[i]=t.data[i];
s.length=t.length;
}
bool StrEqual(SqString s,SqString t) //判断串相等
{
bool same=true;
int i;
if (s.length!=t.length) //长度不相等时返回0
same=false;
else
for (i=0;i<s.length;i++)
if (s.data[i]!=t.data[i]) //有一个对应字符不相同时返回0
{ same=false;
break;
}
return same;
}
int StrLength(SqString s) //求串长
{
return s.length;
}
SqString Concat(SqString s,SqString t) //串连接
{
SqString str;
int i;
str.length=s.length+t.length;
for (i=0;i<s.length;i++) //将s.data[0..s.length-1]复制到str
str.data[i]=s.data[i];
for (i=0;i<t.length;i++) //将t.data[0..t.length-1]复制到str
str.data[s.length+i]=t.data[i];
return str;
}
SqString SubStr(SqString s,int i,int j) //求子串
{
SqString str;
int k;
str.length=0;
if (i<=0 || i>s.length || j<0 || i+j-1>s.length)
return str; //参数不正确时返回空串
for (k=i-1;k<i+j-1;k++) //将s.data[i..i+j]复制到str
str.data[k-i+1]=s.data[k];
str.length=j;
return str;
}
SqString InsStr(SqString s1,int i,SqString s2) //插入串
{
int j;
SqString str;
str.length=0;
if (i<=0 || i>s1.length+1) //参数不正确时返回空串
return str;
for (j=0;j<i-1;j++) //将s1.data[0..i-2]复制到str
str.data[j]=s1.data[j];
for (j=0;j<s2.length;j++) //将s2.data[0..s2.length-1]复制到str
str.data[i+j-1]=s2.data[j];
for (j=i-1;j<s1.length;j++) //将s1.data[i-1..s1.length-1]复制到str
str.data[s2.length+j]=s1.data[j];
str.length=s1.length+s2.length;
return str;
}
SqString DelStr(SqString s,int i,int j) //串删除
{
int k;
SqString str;
str.length=0;
if (i<=0 || i>s.length || i+j>s.length+1) //参数不正确时返回空串
return str;
for (k=0;k<i-1;k++) //将s.data[0..i-2]复制到str
str.data[k]=s.data[k];
for (k=i+j-1;k<s.length;k++) //将s.data[i+j-1..s.length-1]复制到str
str.data[k-j]=s.data[k];
str.length=s.length-j;
return str;
}
SqString RepStr(SqString s,int i,int j,SqString t) //子串替换
{
int k;
SqString str;
str.length=0;
if (i<=0 || i>s.length || i+j-1>s.length) //参数不正确时返回空串
return str;
for (k=0;k<i-1;k++) //将s.data[0..i-2]复制到str
str.data[k]=s.data[k];
for (k=0;k<t.length;k++) //将t.data[0..t.length-1]复制到str
str.data[i+k-1]=t.data[k];
for (k=i+j-1;k<s.length;k++) //将s.data[i+j-1..s.length-1]复制到str
str.data[t.length+k-j]=s.data[k];
str.length=s.length-j+t.length;
return str;
}
void DispStr(SqString s) //输出串s
{
int i;
if (s.length>0)
{ for (i=0;i<s.length;i++)
printf("%c",s.data[i]);
printf("\n");
}
}
链式存储
链串的组织形式与一般的链表类似。链串中的一个结点可以存储多个字符。通常将链串中每个结点所存储的字符个数称为结点大小。
链串基本运算的算法:
#include <stdio.h>
#include <malloc.h>
typedef struct snode
{
char data;
struct snode *next;
} LinkStrNode;
void StrAssign(LinkStrNode *&s,char cstr[]) //字符串常量cstr赋给串s
{
int i;
LinkStrNode *r,*p;
s=(LinkStrNode *)malloc(sizeof(LinkStrNode));
r=s; //r始终指向尾结点
for (i=0;cstr[i]!='\0';i++)
{ p=(LinkStrNode *)malloc(sizeof(LinkStrNode));
p->data=cstr[i];
r->next=p;r=p;
}
r->next=NULL;
}
void DestroyStr(LinkStrNode *&s)
{ LinkStrNode *pre=s,*p=s->next; //pre指向结点p的前驱结点
while (p!=NULL) //扫描链串s
{ free(pre); //释放pre结点
pre=p; //pre、p同步后移一个结点
p=pre->next;
}
free(pre); //循环结束时,p为NULL,pre指向尾结点,释放它
}
void StrCopy(LinkStrNode *&s,LinkStrNode *t) //串t复制给串s
{
LinkStrNode *p=t->next,*q,*r;
s=(LinkStrNode *)malloc(sizeof(LinkStrNode));
r=s; //r始终指向尾结点
while (p!=NULL) //将t的所有结点复制到s
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
}
bool StrEqual(LinkStrNode *s,LinkStrNode *t) //判串相等
{
LinkStrNode *p=s->next,*q=t->next;
while (p!=NULL && q!=NULL && p->data==q->data)
{ p=p->next;
q=q->next;
}
if (p==NULL && q==NULL)
return true;
else
return false;
}
int StrLength(LinkStrNode *s) //求串长
{
int i=0;
LinkStrNode *p=s->next;
while (p!=NULL)
{ i++;
p=p->next;
}
return i;
}
LinkStrNode *Concat(LinkStrNode *s,LinkStrNode *t) //串连接
{
LinkStrNode *str,*p=s->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
r=str; //r指向结果串的尾结点
while (p!=NULL) //用p扫描s的所有数据结点
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data; //将p结点复制到q结点中
r->next=q;r=q; //将p结点复制到q结点中
p=p->next;
}
p=t->next;
while (p!=NULL) //用p扫描t的所有数据结点
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data; //将p结点复制到q结点中
r->next=q;r=q; //将q结点链接到str的末尾
p=p->next;
}
r->next=NULL; //尾结点的next域置为空
return str;
}
LinkStrNode *SubStr(LinkStrNode *s,int i,int j) //求子串
{
int k;
LinkStrNode *str,*p=s->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾结点
if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s))
return str; //参数不正确时返回空串
for (k=0;k<i-1;k++)
p=p->next;
for (k=1;k<=j;k++) //将s的第i个结点开始的j个结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}
LinkStrNode *InsStr(LinkStrNode *s,int i,LinkStrNode *t) //串插入
{
int k;
LinkStrNode *str,*p=s->next,*p1=t->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾结点
if (i<=0 || i>StrLength(s)+1) //参数不正确时返回空串
return str;
for (k=1;k<i;k++) //将s的前i个结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
while (p1!=NULL) //将t的所有结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p1->data;
r->next=q;r=q;
p1=p1->next;
}
while (p!=NULL) //将结点p及其后的结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}
LinkStrNode *DelStr(LinkStrNode *s,int i,int j) //串删去
{
int k;
LinkStrNode *str,*p=s->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾结点
if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s))
return str; //参数不正确时返回空串
for (k=0;k<i-1;k++) //将s的前i-1个结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
for (k=0;k<j;k++) //让p沿next跳j个结点
p=p->next;
while (p!=NULL) //将结点p及其后的结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}
LinkStrNode *RepStr(LinkStrNode *s,int i,int j,LinkStrNode *t) //串替换
{
int k;
LinkStrNode *str,*p=s->next,*p1=t->next,*q,*r;
str=(LinkStrNode *)malloc(sizeof(LinkStrNode));
str->next=NULL;
r=str; //r指向新建链表的尾结点
if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s))
return str; //参数不正确时返回空串
for (k=0;k<i-1;k++) //将s的前i-1个结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;q->next=NULL;
r->next=q;r=q;
p=p->next;
}
for (k=0;k<j;k++) //让p沿next跳j个结点
p=p->next;
while (p1!=NULL) //将t的所有结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p1->data;q->next=NULL;
r->next=q;r=q;
p1=p1->next;
}
while (p!=NULL) //将结点p及其后的结点复制到str
{ q=(LinkStrNode *)malloc(sizeof(LinkStrNode));
q->data=p->data;q->next=NULL;
r->next=q;r=q;
p=p->next;
}
r->next=NULL;
return str;
}
void DispStr(LinkStrNode *s) //输出串
{
LinkStrNode *p=s->next;
while (p!=NULL)
{ printf("%c",p->data);
p=p->next;
}
printf("\n");
}
字符串的模式匹配
设s、t是两个串,求s在t中首次出现的位置的运算叫做模式匹配。
成功是指在目标串s中找到一个模式串t->t是s的子串,返回t在s中的位置。
不成功则指目标串s中不存在模式串t->t不是s的子串,返回-1。
Brute-Force算法
Brute-Force简称为BF算法,亦称简单匹配算法。采用穷举的思路。BF是指暴力的意思!
例如,s=“aaaabcd”,t=“abc”。
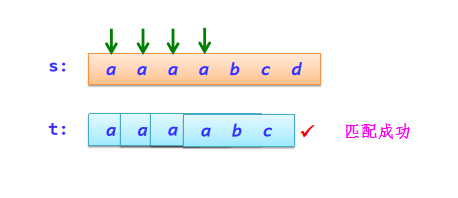
BF算法思路:从s的每一个字符开始依次与t的字符进行匹配。
- i,j分别扫描字符串s和t
- i从0到s.length-t.length循环。
- 对于每个s[i],k=i,j=0开始比较
- 如果t扫描完毕,则返回i
- 若s全部比较完毕都没有返回,则返回-1
算法代码实现:
int index(SqString s,SqString t)
{
int i,j,k;
for (i=0;i<=s.length-t.length;i++)
{
for (k=i,j=0; k<s.length && j<t.length &&
s.data[k]==t.data[j]; k++,j++);
if (j==t.length)
return(i);
}
return(-1);
}
实际上,可以只采用两个变量i、j,通过i回退实现:
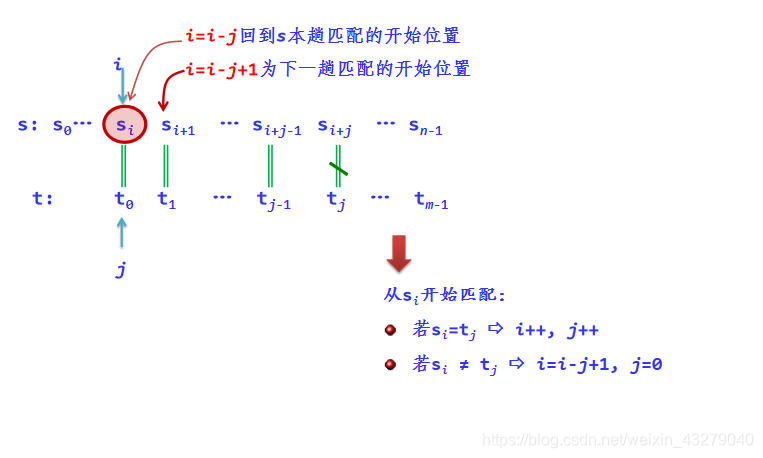
对应的BF算法如下:
int BF(SqString s,SqString t)
{
int i=0,j=0;
while (i<s.length && j<t.length)
{
if (s.data[i]==t.data[j]){
i++; //主串和子串依次匹配下一个字符
j++;
}
else{ //主串、子串指针回溯重新开始下一次匹配
i=i-j+1; //主串从下一个位置开始匹配
j=0; //子串从头开始匹配
}
}
if (j>=t.length) //或者if (j==t.length)
return(i-t.length); //返回匹配的第一个字符的下标
else
return(-1); //模式匹配不成功
}
BF算法分析
- 算法在字符比较不相等,需要回溯(即i=i-j+1):即退到s中的下一个字符开始进行继续匹配。
- 最好情况下的时间复杂度为O(m)。
- 最坏情况下的时间复杂度为O(n×m)。
- 平均的时间复杂度为O(n×m)。
KMP算法
KMP算法是D.E.Knuth、J.H.Morris和V.R.Pratt共同提出的,简称KMP算法。
该算法较BF算法有较大改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
KMP算法的思路:
- 基于BF算法,采用空间换时间的方式,提取保存有利于匹配的信息。
- 提取s还是t中的信息?每次从s不同字符开始匹配,而t总是从t0开始匹配 ->提取t中的信息
- t中的什么信息-> 部分匹配信息。
KMP算法用next数组保存部分匹配信息
KMP算法:
void GetNext(SqString t,int next[]) //由模式串t求出next值
{
int j,k;
j=0;k=-1;next[0]=-1;
while (j<t.length-1)
{
if (k==-1 || t.data[j]==t.data[k]) //k为-1或比较的字符相等时
{
j++;k++;
next[j]=k;
}
else
{
k=next[k];
}
}
}
int KMPIndex(SqString s,SqString t) //KMP算法
{
int next[MaxSize],i=0,j=0;
GetNext(t,next);
while (i<s.length && j<t.length)
{
if (j==-1 || s.data[i]==t.data[j])
{
i++;j++; //i,j各增1
}
else j=next[j]; //i不变,j后退
}
if (j>=t.length)
return(i-t.length); //返回匹配模式串的首字符下标
else
return(-1); //返回不匹配标志
}
KMP算法分析:
- 设串s的长度为n,串t长度为m。
- KMP算法中求next数组的时间复杂度为O(m),在后面的匹配中因主串s的下标不减即不回溯,比较次数可记为n,所以KMP算法平均时间复杂度为O(n+m)。
- 最坏的时间复杂度为O(n×m)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









