






目录
标题:Effective Zero Compression on ReRAM-based Sparse
来源:DAC-2022 /首尔国家大学
DNN Accelerators
摘要
利用模型的稀疏性减少无效的计算是DNN推理加速器中实现高能效被广泛使用的方案。然而由于紧耦合的交叉阵列结构,利用基于ReRAM的神经网络加速器是很少被探索的领域。现有的基于ReRAM的架构研究假定所整个交叉阵列可在一个周期内被激活。然而,鉴于对推理精度的考量,矩阵向量乘计算在实际中必须在小的粒度下进行,称为OU(操作单元)。一个基于OU的架构创造了利用DNN稀疏的新的机会。本文中,我们第一个提出了联合利用权重和激活稀疏性的实际的稀疏ReRAM引擎。我们的评估结果表明所提出的方案在消除无效计算中是有效的,并显示了性能和能量节省上的显著提升。
(简要翻译)
1. 引言
- 图像分类、目标检测、语义识别中DNN被广泛运用。现代DNN模型参数量巨大。一些研究表明ReRAM可用于卷积和全连接层的加速,但仍处于初级阶段。首要的关注在于如何利用稀疏性。由于许多函数利用ReLU进行激活处理,因此权重和激活值都有很多稀疏。ReRAM可以利用细粒度的稀疏——bit级别的稀疏,因为bit密度和WL数量的限制。对于性能和能耗来说,稀疏性都十分重要。
结构剪枝算法被提出规整0值,因此全0的行和列可被找到。SNrram寻求细粒度列压缩,代价为引入高输出寻址消耗。
-
现存的稀疏解决方案基于过于理想的ReRAM交叉架构,大多现存的基于ReRAM的DNN加速器忽视了每个单元的电流偏移对推理精度的影响,因此假定可同时开启128×128或256×256的阵列。然而实际中,512×512的阵列中仅仅9个WL和8个BL可在1个周期被激活。因此相比于类似ISSAC和PRIME这样过于理想的设计,基于OU的实际的ReRAM加速器极有可能有显著的低功耗。
-
本文提出了一种细粒度的权重重排机制,可以有效利用ORC(Operation Unit-based row compression)与非结构化剪枝带来的高稀疏度。通过利用重排的灵活度和细粒度OU映射的,我们的机制显著提高了权重压缩率,消除了单列中的权重压缩不平衡的问题,可以更好地将压缩的权重转化为阵列资源的节省。并且,我们也引入了一个非压缩的0权重恢复机制在不增加阵列使用的情况下恢复模型精度。根据对3种常用DNN的评估,我们的想法与基准架构(2016年的ISACC)相比节省了3.27-4.26倍的的阵列资源。
2. 背景
- 基于RRAM的DNN推理加速器
- 在基于RRAM的DNN加速器中探索权重稀疏度
- 结构剪枝:消除基于交叉阵列中0值的方式是结构剪枝。通过通道剪枝可以消除一列的权重,通过对所有卷积核的同样位置进行剪枝可以消除一行的值。虽然简单但有效。但在相同精度约束的条件下,结构剪枝压缩率低。
- 0值对齐的权值压缩:介绍利用K-means聚类算法制造全0的行。然而技术有限,因为难以用成百列的0值来填满整个行。
- 细粒度的权重压缩。SRE近来引入了在操作单元级别下消除全0行。然而,在有效的0值压缩机制下,权重剪枝并未完全贡献给权重压缩。再者,权重压缩并未完全地导致阵列压缩。由于权重压缩率在每个卷积核中不同,从而卷积核的长度不同带来了不平衡。
3. 有效0值压缩
3.1 概述
- 需要在 OU中获得更多的全0行。卷积核重排可以聚集分散的0值。为了有效地聚集0权重,我们允许卷积核在一个子卷积核的尺度下在水平方向灵活地重排。与此同时,点乘运算在OU的尺度下进行。1个OU中的列权重必须来自于同一个卷积核保证准确度。因此,我们提出一种按OU的映射策略,在子卷积核的粒度下实现OU敏感的重排。
- 映射卷积核中的权重到OU中
- OU映射到阵列
- 由于OU级别的子卷积核重排比卷积核重排提供了更大的灵活度,可以产生更多的额外的全0行。从而提升了阵列的压缩率。
- 即便在细粒度的重排之后,仍然存在0值由于同一行中的非0值而无法被压缩。利用这个机会,我们提出了一种非0值恢复机制在维持同样的阵列压缩率时来进一步提升精度。
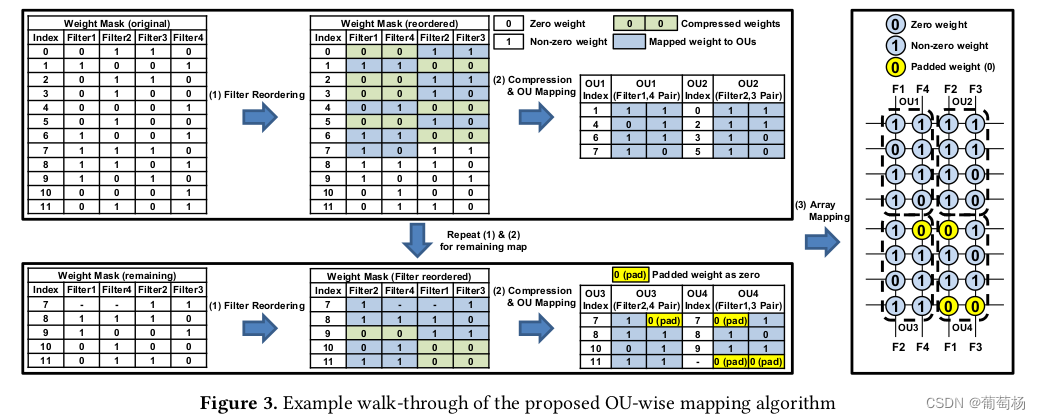

3. 2 按OU的权重映射
假设2个filter在单个OU中是相邻的
-
矩阵重排。首先,设置1个基准fitlter,随后贪婪搜索能产生最多0行的filter。此为一次性搜索。有数量最多的未映射权重的矩阵被选为base filter来平衡所有列的压缩率。图3展示了所提出权重映射算法的运行示例。最左侧的表格展示了给定层的weight mask。最左侧为weight index。
-
压缩和OU映射。在filter重排之后,所有的0行会在OU的粒度下被压缩。非0行会被映射到OU上。此过程被重复直到获得同样数量的非0行来映射到单个OU中。为了在1个更小的粒度下获得同样数量的非0行,并非在整个filter的粒度下进行搜索,从而input index是必要的。同时,由于filter的排布对于每个OU都是不同的,因此output index也是不同的。input/output index的开销在第4部分被讨论。Filter 1和4来到OU1,Filter 2和3被映射到OU2。所有的0行(标记成绿色)被compressed out。非0行被复制到右侧的OU table中。
OU1和OU2完成后,重复同样的步骤继续下一轮。
对于剩下的weight mask中7-11的部分,选择filter2为基准filter。随后重复以上步骤,对于缺失的部分补0.得到OU3和OU4 -
阵列映射:一旦所有的权重重排,压缩,映射到OU后,我们将OU映射到1个或者多个交叉阵列中。由于我们产生了第1个OU并且压缩这些OU到单列中。图3最右侧的子阵列展示了阵列映射的结果。OU在水平方向经历了重排和垂直方向的压缩,我们可以正确地执行点乘,我们可以在合适的输入和输出上正确地执行点乘。
3.3 非压缩的0权重恢复
- 图3展示了 阵列映射的例子。即便在compression之后,仍旧存在着很多被剪枝但还没有被压缩的例子。2个权重在单个OU行的例子中,00组合可被消除,但10和01不会。
- 基于以上观察,我们提出在这些行中恢复未被压缩的10和01组合,在保持阵列压缩率的同时维持精度。由于我们知道未被压缩权重的行和列上的index,我们可以修订最初在非结构化剪枝中的mask。在图3中,Filter1的index4,Filter2的Index10,Filter3中的index3, 5, 8以及Filter中的Index4是未映射的。(没懂)
4. 硬件架构
- 输入寻址:input index buffer
- b编码:delta coding,存差额
- bit packing
- 输出寻址
- 数据流:在PE中提出的基于ReRAM架构的数据流如图5所示

eDRAM buffer 用于存储输入激活和输入输出寻址。为了喂右侧的输入值到每个OU中,我们同eDRAM buffer中获取PE中的地址随后解码成相应的地址。使用这些地址,输入激活值被取到,并送入输入寄存器中同时被传送到相应的WL上,一旦相应的WL激活,则电流值会在每个bitline上被采样保持电路读出。接着,模拟输出被ADC采样成数字输出。如果相同filter的部分和的数据已经被存储到输出寄存器中,我们可以从输出寄存器中得到相应的数字输出并被合适地移位。与此同时,为了在输出寄存器中存储新产生的部分和,控制逻辑产生了带有输出寻址的寄存器的地址。
5. 评估
5.1 方案
-
工作量:定制的仿真器;3种DNN模型:VGG-16,ResNet-18HE GoogleLeNet。在CIFAR-100上剪枝,稀疏度不同。输入和权重被量化为16bit固定浮点数。
-
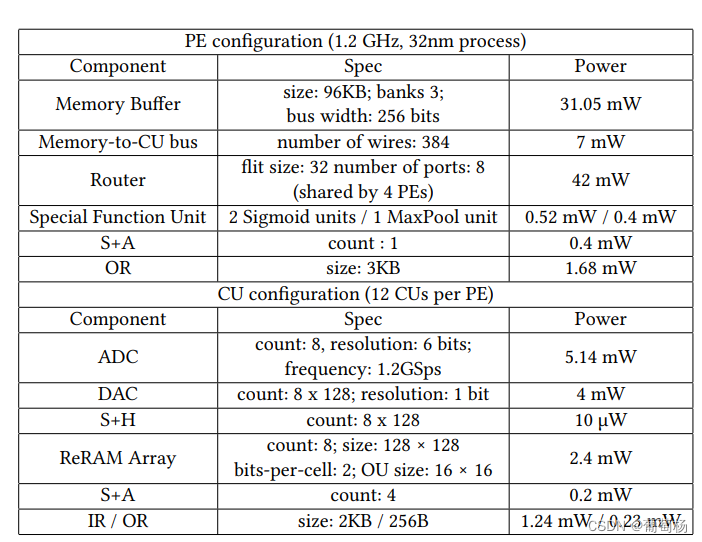
比较设计: 表1展示了基于ISAAC的加速器配置,作为本文基准。保守地增加32KB在PE的存储缓存中来存储输入和输出索引(总量为96KB)。ISAAC并未利用任何的稀疏。此外,我们与我们的机制和ISAAC和SRE中的机制进行比较。我们也比较了SRE中的小批量结构剪枝。公平起见,我们在相同的损失精度下比较这些机制。
-
5.2 性能和能耗
-
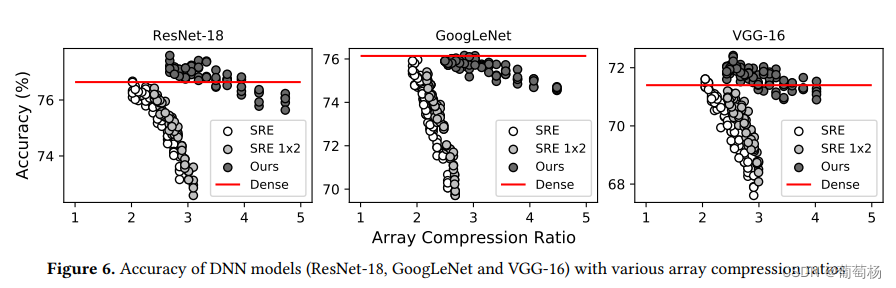
阵列压缩率:3.27-4.26倍(2.49-3.70倍)
-
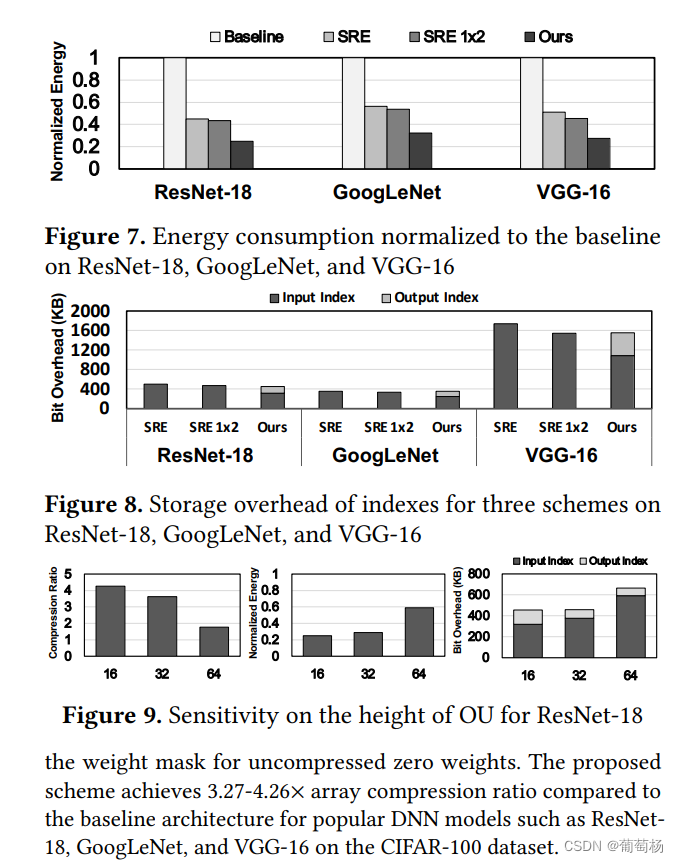
能耗:即便寻址和输入缓存消耗,与基准相比,只消耗了基准的0.25-0.32x。原因在于只消耗了更少的PE。SRE比较我们的方案需要更多的PE
-
敏感性分析:我们基于ResNet-18识别CIFAR-100数据集评估了3中OU高度下的阵列压缩率,能耗以及bit消耗,由于OU的高度取决于ReRAM单元的可靠性。我们实现了更高的阵列压缩率。
5.3 寻址开销
所提出的架构在寻址时需要额外的存储和解码器来寻址。例如317KB需要用于在利用ResNet-18识别CIFAR-100的情况,然而SRE需要图8中几乎500KB的缓存。为了评估面积和功耗,我们用Verilog实现了寻址并用TSMC 40nm工艺综合。总面积为0.0015mm2和0.3mW,在我们的配置中几乎可忽略,在5.2部分的能量评估中,我们缩放这个结果到32nm工艺。
6. 总结
- 本文提出一种新的卷积核重排的权重映射机制。利用基于DNN的稀疏和基于OU的行压缩操作。介绍了从未压缩0权重的恢复机制。我们有效地将权重的压缩率转换为阵列的压缩率,导致了更高的吞吐量,减轻了列之间压缩率不平衡的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









