






一、基础数据类型占用内存
unsafe.Sizeof()
| 类型 | 字节数 |
|---|---|
| bool | 1 |
| string | 2 * 计算机字长/8 (64位16个字节,32位8个字节) |
| int、uint、uintptr | 计算机字长/8 (64位8个字节,32位4个字节) |
| *T, map, func, chan | 计算机字长/8 (64位8个字节,32位4个字节) |
| intN, uintN, floatN, complexN | N/8个字节(int32是4个字节,float64是8个字节) |
| interface | 2 * 计算机字长/8 (64位16个字节,32位8个字节) |
| []T | 3 * 计算机字长/8 (64位24个字节,32位12个字节) |
二、什么是内存对齐
各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐
三、为什么需要内存对齐
- 不同硬件平台的cpu读取内存方式具有差异性,内存对其可以帮助代码的平台移植性
- cpu访问内存不是一个个字节去读取的,而是以字长为单位去读取的,32位操作系统是4个字节,64位操作系统是8个字节,如果没有对齐内存,会导致一个变量可能需要多次读取才能获得完整数据,不利于原子性处理
四、结构体对齐过程
对齐系数 = min(计算机字长/8,unsafe.Sizeof(x))
对于任意类型的变量 x ,unsafe.Alignof(x) 至少为 1;
对于 struct 结构体类型的变量 x,计算 x 每一个字段 f 的 unsafe.Alignof(x.f),unsafe.Alignof(x) 等于其中的最大值;
对于 array 数组类型的变量 x,unsafe.Alignof(x) 等于构成数组的元素类型的对齐倍数。
func main() {
fmt.Println(unsafe.Sizeof(MemStruct{}), unsafe.Alignof(MemStruct{})) //8 4
fmt.Println(unsafe.Sizeof(MemStruct1{}), unsafe.Alignof(MemStruct1{})) //12 4
fmt.Println(unsafe.Sizeof(MemStruct2{}), unsafe.Alignof(MemStruct2{})) //24 8
}
type MemStruct struct {
b bool // 1
i8 int8 // 1
i16 int16 // 2
i32 int32 // 4
}
type MemStruct1 struct {
b bool // 1
i32 int32 // 4
i8 int8 // 1
}
type MemStruct2 struct {
b bool // 1
i8 int8 // 1
i64 int64 // 8
}
S1 明显占用的内存更少。让我们来分析一下,S1 和 S2 的对齐系数都等于其子字段 int16 的对齐系数,也就是 4。对于S1,经过内存对齐,它们在内存中的布局是这样的:
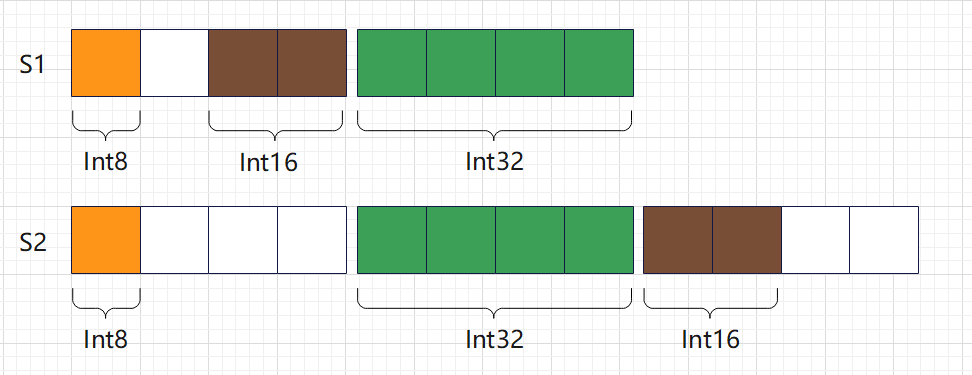
对于 S1:
- i8 是第一个字段,默认已经对齐,从 0 开始占据 1 个字节;
- i16 是第二个字段,对齐系数为 2,因此,必须填充 1 个字节,其偏移量才是 2 的倍数,从 2 开始占据 2 字节;
- i32 是第三个字段,对齐系数为 4,此时,内存已经是对齐的,从第 4 开始占据 4 字节即可;
因此 S1 在内存占用了 8 个字节,浪费了 1 个字节。
对于 S2:
- i8 是第一个字段,默认已经对齐,从 0 开始占据 1 个字节;
- i32 是第二个字段,对齐系数为 4,因此,必须填充 3 个字节,其偏移量才是 4 的倍数,从第 4 开始占据 4 字节;
- i16 是第三个字段,对齐系数为 2,此时,内存已经是对齐的,从第 8 开始占据 2 字节即可。
因此 S2 在内存占用了 12 个字节,浪费了 5 个字节。

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









