






 本文介绍了微调预训练模型的方法,包括如何在PyTorch中保存和加载模型,下载第三方模型,以及在不同训练策略下(如微调所有参数、冻结部分参数等)如何进行模型调整和训练。重点在于理解和应用模型的参数保存与加载,以及在新任务上进行有效微调的技巧。
本文介绍了微调预训练模型的方法,包括如何在PyTorch中保存和加载模型,下载第三方模型,以及在不同训练策略下(如微调所有参数、冻结部分参数等)如何进行模型调整和训练。重点在于理解和应用模型的参数保存与加载,以及在新任务上进行有效微调的技巧。
微调模型
例如:第一章 微调模型
前提:微调模型
微调(fine-tuning)的步骤
- 在源数据集(例如ImageNet数据集)上预训练神经网络模型,即源模型。
- 创建一个新的神经网络模型,即目标模型。这将复制源模型上的所有模型设计及其参数(输出层除外)。我们假定这些模型参数包含从源数据集中学到的知识,这些知识也将适用于目标数据集。我们还假设源模型的输出层与源数据集的标签密切相关;因此不在目标模型中使用该层。
- 向目标模型添加输出层,其输出数是目标数据集中的类别数。然后随机初始化该层的模型参数。
- 在目标数据集(如椅子数据集)上训练目标模型。输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。
一、保存自己训练出的模型并加载模型
要保存自己训练的模型,您可以使用PyTorch提供的torch.save()函数来保存模型的状态字典或整个模型。通常,保存模型的状态字典是更常见的做法,因为它仅包含模型的参数,而不包含模型的结构,这样在加载时可以更加灵活地构建模型。
1、保存【模型框架+保存模型的状态字典(参数)】并加载模型
(1)保存模型框架+保存模型的状态字典(参数)
希望将模型的框架和状态参数都保存下来:
可以使用torch.save()函数保存整个模型,包括模型的结构和状态参数。示例代码如下:
import torch
# 假设您的模型为model,并且希望保存整个模型
torch.save(model, "path/to/save/complete_model.pth")
在这个示例中,model是您已经训练好的模型。torch.save()函数将模型保存到名为"model_params.pth"的文件中。您可以根据需要更改文件路径和文件名。
(2)加载模型
要加载模型,您可以使用torch.load()函数来加载整个模型:
# 加载保存的整个模型
loaded_model = torch.load("path/to/save/complete_model.pth")
2、保存【保存模型的状态字典(参数)】并加载模型
(1)保存模型的状态字典
希望将模型的状态参数保存下来,但不保存框架:
这种情况下,您可以直接使用torch.save()函数保存模型的状态字典,不需要保存整个模型的结构。示例代码如下:
# 假设您的模型为model,并且希望保存模型的框架
torch.save(model.state_dict(), "path/to/save/model_structure.pth")
(2)加载模型
请注意,当您需要重新加载模型时,您需要确保重新创建一个与原始模型相同结构的新模型,然后再使用load_state_dict()函数加载保存的参数。这样可以保证参数的维度匹配,从而正确加载模型的状态字典。
# 创建新的模型实例
new_model = YourModel() # 替换成您的模型的实例化方法
# 加载保存的模型结构
new_model.load_state_dict(torch.load("path/to/save/model_structure.pth"))
3、保存【保存模型的框架】并加载模型
(1)保存模型的框架
希望将模型的框架保存下来,不保存状态参数:
如果只想保存模型的结构而不包括状态参数,可以直接使用torch.save()函数保存整个模型,不必使用state_dict()方法。示例代码如下:
# 假设您的模型为model,并且希望保存整个模型
torch.save(model, "path/to/save/complete_model.pth")
(2)加载模型
在这个示例中,model是您已经训练好的模型。**torch.save()函数将整个模型保存到名为"model_structure.pth"的文件中**。要加载模型结构,您可以直接使用torch.load()函数加载整个模型:
# 加载保存的模型结构
loaded_model = torch.load("path/to/save/model_structure.pth")
不保存状态参数的话,加载时模型的参数将是随机初始化的。所以在加载模型后,需要自行根据需求对模型参数进行初始化
二、下载第三方提供的模型框架和参数
1、使用torchvision下载模型
(1)pretrained决定是否下载参数
pretrained=True #-----> 将模型的框架+模型的参数 都下载下来
pretrained=False #-----> 只将模型的框架下载下来
(2)下载模型
pretrained_net = torchvision.models.resnet18(pretrained=True)
print(pretrained_net)
# 输出
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
三、创建目标模型
1、如何在原有模型后面再添加一层或者多层
import torch
import torch.nn as nn
# 假设您的模型为model,并且希望加载保存的模型参数
class YourModel(nn.Module):
def __init__(self):
super(YourModel, self).__init__()
# 定义您的模型的结构,包括您希望保存的模型部分和新增的部分
# 示例:保存的模型部分
self.features = nn.Sequential(
# 定义保存的模型的层
nn.Conv2d(3, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(64, 128, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
# 示例:新增的部分(还未指定输出特征数)
self.new_layer = nn.Sequential(
# 新增的层,输出特征数暂未指定
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.new_layer(x)
return x
# 创建新的模型实例
model = YourModel()
# 加载之前保存的模型参数
saved_model_state = torch.load("path/to/save/model_params.pth")
model.features.load_state_dict(saved_model_state) # 加载保存的模型部分的参数
# 获取保存的模型部分的输出特征数
# 假设模型的输出特征数在保存的模型中的全连接层中
# 如果输出特征数在其他层中,相应地进行调整
saved_output_features = saved_model_state['fc.weight'].size(1)
# 在新的模型实例后面添加新增的层
model.new_layer = nn.Sequential(
nn.Linear(saved_output_features, 256),
nn.ReLU(),
nn.Linear(256, num_classes) # 假设 num_classes 是新任务的类别数
)
# 可以在新增的层后面继续添加其他层,根据需要进行设计
# 现在 model 就是加载了保存的模型参数并在后面添加了新层的模型
# 您可以使用 model 进行微调或其他任务
核心操作在于
1、 首先重新创建一个
新的模型类
2、将旧的模型框架包装在一个nn.Sequential中
3、将新添加的模型框架包装在一个nn.Sequential中(可以直接写好新添加的模型框架到目标模型类中,也可以后续添加)
2、如何修改原有模型的最后一层
# 假设您的模型为model,并且希望修改最后一层的框架
in_features = model.fc.in_features # 获取最后一层的输入特征数
out_features = 10 # 新的输出特征数
model.fc = nn.Linear(in_features, out_features) # 替换最后一层为新的全连接层
四、冻结参数+从头开始训练
核心在于优化函数和
1、微调源模型的参数+从头开始训练新加的层
finetune_net = torchvision.models.resnet18(pretrained=True)
# 修改模型最后一层
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(finetune_net.fc.weight)
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
train_fine_tuning(finetune_net, 5e-5)
微调源模型的所有参数
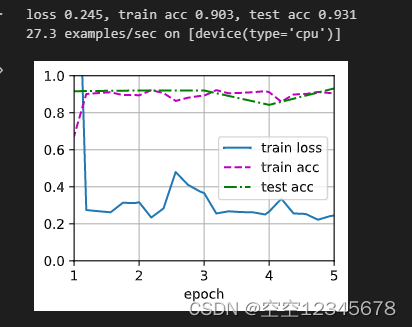
2、冻结源模型的所有参数+从头开始训练新加的层
代码如下(示例):
freeze_all_net = torchvision.models.resnet18(pretrained=True)
freeze_all_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(freeze_all_net.fc.weight);
# 如果原本的模型的参数全部冻结
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_freeze_all(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
# for name, param in pretrained_net.named_parameters():
# if "fc" not in name: # 排除输出层的参数
# param.requires_grad = False
if param_group:
trainer = torch.optim.SGD([{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
train_freeze_all(freeze_all_net, 5e-5)
冻结模型的全部参数
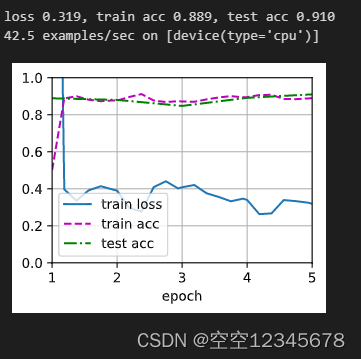
3、冻结源模型的部分参数+从头开始训练新添加的层
下面是冻源模型的15%参数,保证其不改变
import random
freeze_some_net = torchvision.models.resnet18(pretrained=True)
freeze_some_net.fc = nn.Linear(finetune_net.fc.in_features, 2)
nn.init.xavier_uniform_(freeze_some_net.fc.weight)
total_params = sum(p.numel() for p in pretrained_net.parameters())
params_to_freeze = int(0.15 * total_params)
all_params = list(pretrained_net.parameters())
random.shuffle(all_params)
# 冻结前 params_to_freeze 个参数
for param in all_params[:params_to_freeze]:
param.requires_grad = False
# 如果原本的模型的参数全部冻结
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_freeze_some(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
# for name, param in pretrained_net.named_parameters():
# if "fc" not in name: # 排除输出层的参数
# param.requires_grad = False
if param_group:
trainer = torch.optim.SGD([
{'params': filter(lambda p: p.requires_grad, pretrained_net.parameters())},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
train_freeze_some(freeze_some_net , 5e-5)
冻结15%的参数的结果:
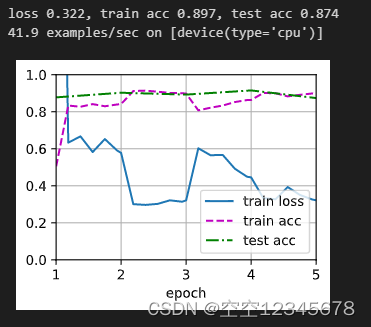
冻结5%的参数的结果
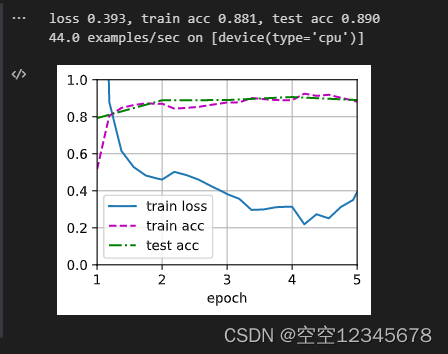
4、整个目标模型全部重新训练
scratch_net = torchvision.models.resnet18()
scratch_net.fc = nn.Linear(scratch_net.fc.in_features, 2)
# 如果原本的模型的参数全部冻结
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
train(scratch_net, 5e-5)
目标模型全部重新训练的结果:
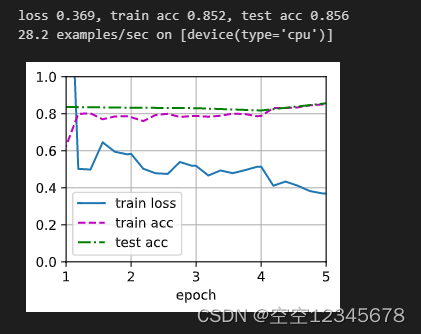
总结
1、微调源模型的所有参数:
loss 0.245, train acc 0.903, test acc 0.931
2、固定源模型的部分参数:
固定5%:loss 0.393, train acc 0.881, test acc 0.890
固定15%:loss 0.322, train acc 0.897, test acc 0.874
固定50%:loss 0.295, train acc 0.901, test acc 0.865
固定75%:loss 0.635, train acc 0.834, test acc 0.899
3. 固定源模型的全部参数(不然在模型训练的过程中发生改变)
loss 0.319, train acc 0.889, test acc 0.910
4.目标模型中的参数全部重新训练
loss 0.369, train acc 0.852, test acc 0.856
总结
1、如果新任务与预训练任务相似,且预训练模型在大规模数据上表现良好,则微调原有模型的所有参数通常是一个较好的选择,因为它在较少的训练数据上可以取得较好的效果。
2、如果任务复杂性较低,微调原本模型的15%参数可能足以达到较好的性能,并且可以减少训练成本。
3、而如果任务与预训练任务差异较大,或者没有合适的预训练模型可用,那么全部从头开始训练可能是更好的选择,尽管它需要更多的计算资源和训练时间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









