







 超级会员免费看
超级会员免费看
 本文探讨了Java中HashMap的工作原理和效率问题。为了保证元素不重复,equals方法用于判断元素是否重复。然而,大量元素时,直接使用equals方法效率低下。哈希表(如HashMap)采用哈希函数提高查找速度,但可能导致冲突。解决冲突的方法包括线性探查法和双散列函数法等。重写hashcode和equals方法至关重要,确保对象相同则哈希码相同,提升HashSet和HashMap的性能和准确性。
本文探讨了Java中HashMap的工作原理和效率问题。为了保证元素不重复,equals方法用于判断元素是否重复。然而,大量元素时,直接使用equals方法效率低下。哈希表(如HashMap)采用哈希函数提高查找速度,但可能导致冲突。解决冲突的方法包括线性探查法和双散列函数法等。重写hashcode和equals方法至关重要,确保对象相同则哈希码相同,提升HashSet和HashMap的性能和准确性。
总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set。你知道它们的区别吗?前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。那么这里就有一个比较严重的问题了:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?这就是Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
于是,Java采用了哈希表的原理。哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
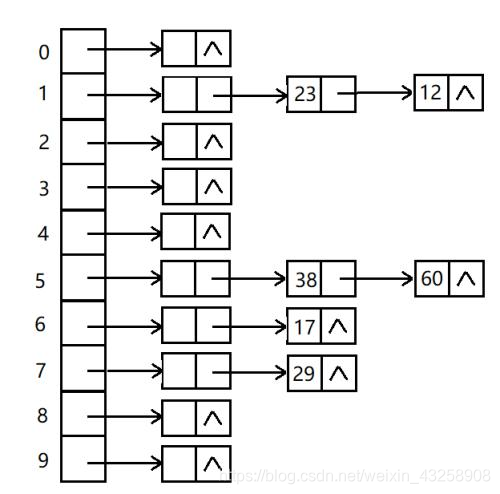
比如我们存储70个元素,但我们可能为这70个元素申请了100个元素的空间。70/100=0.7,这个数字称为负载因子。我们之所以这样做,也是为了“快速存取”的目的。我们基于一种结果尽可能随机平均分布的固定函数H为每个元素安排存储位置,这样就可以避免遍历性质的线性搜索,以达到快速存取。但是由于此随机性,也必然导致一个问题就是冲突。所谓冲突,即两个元素通过散列函数H得到的地址相同,那么这两个元素称为“同义词”。这类似于70个人去一个有100个椅子的饭店

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2250
2250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











