






一、查询语句
1、普通查询
select * from table
2、条件查询
select * from table where 范围
3、模糊查询
select * from table where field1 like '%value%'
select * from qt_case_session where field1 concat('%',value,'%') // 避免注入
4、排序查询
select * from table order by field1,field2 [desc]
5、条件+排序+记录:
select * from table where 范围 and field like '%value%' order by field1,field2 [desc] limit 记录数
6、子查询:
- 在SELECT中嵌套:
SELECT s.student_id,s.student_name,
(SELECT class_name FROM t_class c WHERE c.class_id=s.class_id)
FROM t_student s GROUP BY s.student_id;
- 在WHERE中嵌套
SELECT * FROM t_student WHERE student_subject='java' AND student_score>=ALL
(SELECT student_score FROM t_student WHERE student_subject='java') ;
这里出现了一个ALL,其为子查询运算符分类:
–ALL运算符
和子查询的结果逐一比较,必须全部满足时表达式的值才为真。
–ANY运算符
和子查询的结果逐一比较,其中一条记录满足条件则表达式的值就为真。
–EXISTS/NOT EXISTS运算符
EXISTS判断子查询是否存在数据,如果存在则表达式为真,反之为假。NOT EXISTS相反。
在子查询或相关查询中,要求出某个列的最大值,通常都是用ALL来比较,大意为比其他行都要大的值即为最大值。
7、组合查询(不实用)
通过UNION运算符来将两张表纵向联接,基本方式为:SELECT 列1 , 列2 FROM 表1
UNION
SELECT 列3 , 列4 FROM 表2;
UNION ALL为保留重复行:
SELECT 列1 , 列2 FROM 表1
UNION ALL
SELECT 列3 , 列4 FROM 表2;
8、四种连接查询
内连接
- 隐式的内连接,没有INNER JOIN,形成的中间表为两个表的笛卡尔积。
select a.*,b.* from a inner join b on a.id = b.parent_id
- 显示的内连接,一般称为内连接,有INNER JOIN,形成的中间表为两个表经过ON条件过滤后的笛卡尔积。
SELECT O.ID,O.ORDER_NUMBER,C.ID,C.NAME FROM CUSTOMERS C
INNER JOIN ORDERS O ON C.ID=O.CUSTOMER_ID;
外连接
- 左连接
LEFT JOIN:
select a.*,b.* from a left join b on a.id=b.parent_id
LEFT OUTER JOIN :
SELECT O.ID,O.ORDER_NUMBER,O.CUSTOMER_ID,C.ID,C.NAME
FROM ORDERS O LEFT OUTER JOIN CUSTOMERS C ON C.ID=O.CUSTOMER_ID;
- 右连接
right join:
select a.*,b.* from a right join b on a.id=b.parent_id
RIGHT OUTER JOIN:
SELECT O.ID,O.ORDER_NUMBER,O.CUSTOMER_ID,C.ID,C.NAME
FROM ORDERS O RIGHT OUTER JOIN CUSTOMERS C ON C.ID=O.CUSTOMER_ID;
- 完全连接
select a.*,b.* from a full join b on a.id=b.parent_id
交叉连接
- 隐式的交叉连接,没有CROSS JOIN。
SELECT O.ID, O.ORDER_NUMBER, C.ID, C.NAME
FROM ORDERS O , CUSTOMERS C WHERE O.ID=1;
- 显式的交叉连接,使用CROSS JOIN
SELECT O.ID,O.ORDER_NUMBER,C.ID,C.NAME
FROM ORDERS O CROSS JOIN CUSTOMERS C WHERE O.ID=1;
9、特殊情况查询:
1、查询ID在字符串中,使用精确查询 FIND_IN_SET
2、查询某字段为空,使用 is null
3、SQL查询~ 存在一个表而不在另一个表中的数据
- 方法一:使用 not in ,容易理解,效率低
select distinct A.ID from A where A.ID not in (select ID from B)
- 方法二:使用 left join…on… , “B.ID isnull” 表示左连接之后在B.ID 字段为 null的记录
select A.ID from A left join B on A.ID=B.ID where B.ID is null
- 方法三:逻辑相对复杂,但是速度最快
select * from B where (select count(1) as num from A where A.ID = B.ID) = 0
二、操作语句
1、修改表数据的值
- INSERT 插入指定的数据到指定的表:
INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)
INSERT INTO table_name VALUES (value1,value2,value3,...);
- UPDATE 语句用于修改表中的数据(修改表属性值)
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
// 例子:修改属性值
UPDATE `sys_resource` SET `menu_url` = '/freightRule' WHERE `permission_res_code` = 'chainB2CFreightRules:view';
- DELETE 语句用于删除表中的行
DELETE FROM 表名称 WHERE 列名称 = 值
- ALTER 修改已有的表数据
// 新增列:
ALTER TABLE table_name ADD column_name datatype
// 例子:新增一列并且默认设置值
ALTER TABLE activity add IS_TEAM_UP ENUM('Y','N') NOT NULL DEFAULT 'N' COMMENT '是否凑团';
- CREATE INDEX
CREATE INDEX
// 创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name ON table_name (column_name)
// 创建唯一性索引
SET STATISTICS TIME ON SELECT * FROM customer WHERE name ='阿爆' ;
SET STATISTICS TIME OFF CREATE UNIQUE INDEX customer_name ON customer(name);
2、修改表格属性
- 修改表名称
rename table 老表名 to 新表名
- 表新增字段
alter table 表名 add [column] 字段名 数据类型 [列属性][位置]
位置:字段可以存放在表中的任意位置;
first:第一个位置;
after:在哪个字段之后;默认在最后一个字段的后面。
- 修改字段:一般修改属性和数据类型
alter table 表名 modify 字段名 数据类型 [属性][位置]
- 重命名字段:
alter table 表名 change 老字段 新字段 数据类型 [属性][位置];
- 删除字段:
alter table 表名 drop 字段名;
3、刪除表格属性
- drop
- 删除内容和定义(数据结构),释放空间,删除后不可增加数据,只能重新定义新表
drop table tableName
- truncate
- 删除内容、释放空间但不删除定义(数据结构),相当于清空(截断)表
truncate table tableName
- delete
- 删除内容不删除定义(数据结构),不释放空间,可以删除整个表数据,但效率低因为是一行一行删,一般用户删除某一条数据
delete table tableName (删除整个表数据)
delete table tableName where *** (条件删除某一条数据)
delete form tableName where *** (条件删除某一条数据)
三、操作符
- IN
select * from table1 as t where t.id in (value1,value2,...)
- NOT IN
select * from table1 as t where t.id NOT IN (value1,value2,...)
- OR
SELECT * FROM Persons WHERE FirstName='Thomas' AND LastName='Carter'
- AND
SELECT * FROM Persons WHERE FirstName='Thomas' OR LastName='Carter'
- EXIST
select * from table1 as t where t.id EXIST(value1,value2,...)
- NOT EXIST
select * from table1 as t where t.id NOT EXISTS(value1,value2,...)
说明:
1、EXISTS(包括 NOT EXISTS )子句的返回值是一个BOOL值
2、in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询,一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in;
3、not in 只有当子查询中,select 关键字后的字段有not null约束或者有这种暗示时用not in,另外如果主查询中表大,子查询中的表小但是记录多,则应当使用NOT EXISTS,
- FIND_IN_SET 精确匹配
使用情况:假如字符串str 在由N个子链组成的字符串列表strlist 中,则返回值的范围在 1 到 N 之间。一个字符串列表就是一个由一些被‘,’符号分开的自链组成的字符串 ,例如 (1,2,3,4)
注意:IN 比FIND_IN_SET性能高。我们要查询的字段是主键,使用IN时会使用索引,只会查询表中部分数据。FIND_IN_SET则会查询表中全部数据
select * from table t where t.id FIND_IN_SET (?,(1,2,3,4))
- IF
- IFNULL
- 用法:查询出的这条记录要有值,只是这条记录的某个字段为null时,才可以使用ifnull
select IFNULL(T.NUMBER) WHERE TABLE T
四、sql函数
1、常用函数
- AVG(column) 返回某列的平均值
- COUNT(column) 返回某列的行数(不包括NULL值)
- COUNT(*) 返回被选行数
- COUNT(DISTINCT column) 返回相异结果的数目
- MAX(column) 返回某列的最高值
- MIN(column) 返回某列的总和
- SUM(column) 返回某列的总和
- ROUND(c,decimals) 对某个数值域进行指定小数位数的四舍五入
- EXPLAIN 数据库查询性能语句
- DISTINCT 去重
部分用法
decimals:
SELECT ROUND(column_name,decimals) FROM table_name
- HAVING 用于和聚合函数一起使用,用于sql结尾,一般和 GROUP BY 一起
SELECT Customer,SUM(OrderPrice) FROM Orders
GROUP BY Customer
HAVING SUM(OrderPrice)<2000
- GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Customer
2、高级函数
CASE WHEN
类似JAVA中的IF ELSE语句。
Case 函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
Case when 相当于一个自定义的数据透视表,group by 是行名,case when 负责列名
- 格式
CASE WHEN condition THEN result
[WHEN...THEN...]
ELSE result
END
// 简单函数
CASE SCORE WHEN 'A' THEN '优' ELSE '不及格' END
CASE SCORE WHEN 'B' THEN '良' ELSE '不及格' END
CASE SCORE WHEN 'C' THEN '中' ELSE '不及格' END
// 搜索函数
CASE WHEN SCORE = 'A' THEN '优'
WHEN SCORE = 'B' THEN '良'
WHEN SCORE = 'C' THEN '中' ELSE '不及格' END
-
实例一
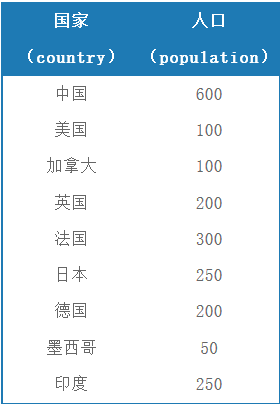
- 根据这个国家人口数据,统计亚洲和北美洲的人口数量 与GROUP BY 结合,分组,分析
SELECT CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END as '洲' , SUM(population) as '人口'
FROM new_table
GROUP BY CASE country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END;
- 结果:

这里的两个CASE WHEN都相当于一个字段,不过值得一提的是,第二个CASE WHEN 的THEN值并不用写明是什么洲,它只是用于将记录进行分组,所以THEN后面的值只有能区分这三种记录就行,GROUP BY也可以写成:
GROUP BY CASE country
WHEN '中国' THEN 0
WHEN '印度' THEN 0
WHEN '日本' THEN 0
WHEN '美国' THEN 1
WHEN '加拿大' THEN 1
WHEN '墨西哥' THEN 1
ELSE 2 END;
- 实例二
- 用一个SQL语句完成不同条件的分组。
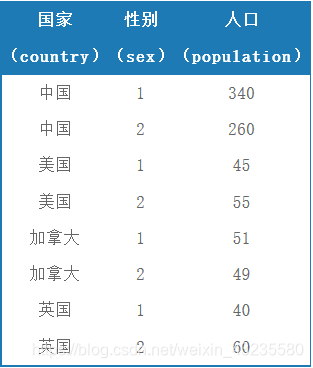
用Case函数来完成按照国家和性别进行分组:
- 用一个SQL语句完成不同条件的分组。
SELECT country,
SUM( CASE WHEN sex = '1' THEN population ELSE 0 END ), --男性人口
SUM( CASE WHEN sex = '2' THEN population ELSE 0 END ) --女性人口
FROM Table_A
GROUP BY country;
结果:
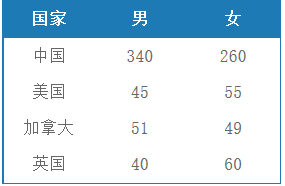
就第一个CASE WHEN讲解:
CASE WHEN sex = ‘1’ THEN
population ELSE 0 END
当记录的sex为1时,这个字段的值为记录的population值,否则为0,因此能计算出一个国家的男性人口。

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









