







 本文介绍了序列化和反序列化的概念,特别是在Hadoop中的应用。与Java的序列化相比,Hadoop的Writable接口提供了一种轻量级且高效的序列化方式,适合网络传输。在Hadoop中,实现序列化主要是通过实现Writable接口,对于更复杂的需求,如bean对象的序列化,需要额外的步骤。文中以用户手机上网详单数据处理为例,展示了如何在实际开发中实现这一过程。
本文介绍了序列化和反序列化的概念,特别是在Hadoop中的应用。与Java的序列化相比,Hadoop的Writable接口提供了一种轻量级且高效的序列化方式,适合网络传输。在Hadoop中,实现序列化主要是通过实现Writable接口,对于更复杂的需求,如bean对象的序列化,需要额外的步骤。文中以用户手机上网详单数据处理为例,展示了如何在实际开发中实现这一过程。
什么是序列化和反序列化?
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
Hadoop中的序列化和Java中的序列化有什么不同?
Java 的序列化(Serializable)是一个重量级序列化框架,一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系…),不便于在网络中高效传输;所以,hadoop 自己开发了一套序列化机制(Writable),精简,高效。不用像 java 对象类一样传输多层的父子关系,需要哪个属性就传输哪个属性值,大大的减少网络传输的开销。
Hadoop中的序列化怎么实现?
Writable是Hadoop的序列化格式,hadoop定义了这样一个Writable接口。 一个类要支持可序列化只需实现这个接口即可。
另外Writable有一个子接口是WritableComparable,writableComparable是既可实现序列化,也可以对key进行比较,我们这里可以通过自定义key实现WritableComparable来实现我们的排序功能
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下步骤。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
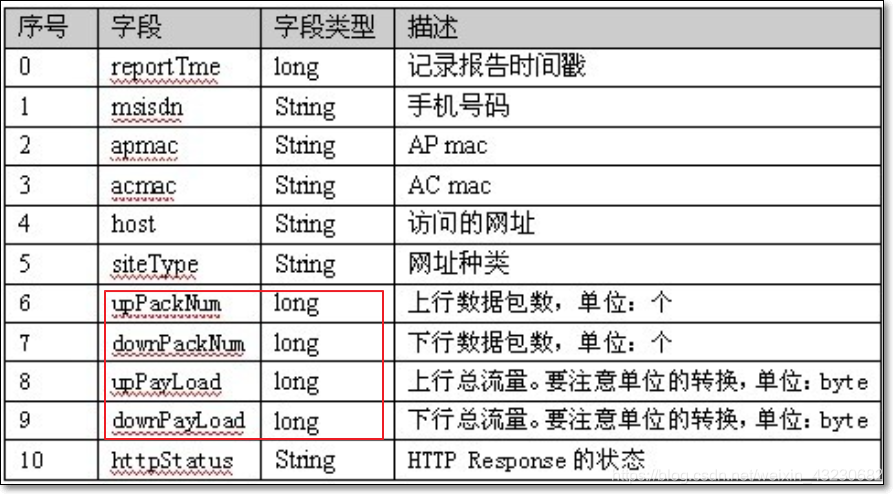
案例实操
需求:
现有用户手机上网详单数据如上图,求取每个手机号的上行包个数之和、下行包个数之和,以及上行总流量之和、下行总流量之和
代码实现:
1、定义javaBean对象:
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//序列化与反序列化
public cla 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









