







文章目录
- Overview
- 理解 Kubernetes 中的 Pod 阶段
- 理解 Pod 内的不同容器状态
- Kubernetes 中的 CrashLoopBackOff 状态
- 什么是BackOff时间及其重要性?
- Kubernetes 重启策略概述
- 检测 Kubernetes CrashLoopBackOff
- Kubernetes 中导致 CrashLoopBackOff 的常见原因
- 如何排查并解决 CrashLoopBackOff
- 结论
Overview
CrashLoopBackOff 是 Kubernetes 中的一种状态,表示 Pod 处于反复崩溃和重启的循环中,即 Pod 内的某个容器启动后崩溃,并不断被 Kubernetes 重新启动。
CrashLoopBackOff 并非直接的错误,而是表明 Pod 在启动过程中遇到问题,导致无法正常运行。
默认情况下,Pod 的重启策略(restart policy)为 Always,即在失败时会自动重启(其他选项包括 Never 和 OnFailure)。根据 Pod 模板中设定的策略,Kubernetes 可能会多次尝试重启该 Pod。
每次 Pod 重新启动后,Kubernetes 都会等待更长的时间再进行下一次重启,这个递增的等待时间被称为“退避延迟(backoff delay)”。在此过程中,Kubernetes 会显示 CrashLoopBackOff 状态,以指示 Pod 正在经历反复重启的问题。
理解 Kubernetes 中的 Pod 阶段
通常,在 Kubernetes 中创建 Pod(资源)时,需要提交一个 YAML 配置文件。Kube API Server 负责验证该配置,并将其接收处理。同时,Kube-Scheduler 监视新创建的 Pod,并根据资源需求将其调度到合适的节点上运行。
| 状态 | 描述 |
|---|---|
| Pending | Pod 创建后的第一步,Kubernetes 调度器会将其分配到合适的节点运行。 |
| Running | Pod 内的容器成功创建后,Pod 会进入 Running 状态。 |
| Succeeded | Pod 的主容器执行完毕且成功完成后,Pod 会转变为 Succeeded 状态。 |
| Failed | 如果 Pod 内的任何容器发生故障或返回非零退出码,Pod 会进入 Failed 状态。 |
可以使用以下命令查看上述 Pod 状态:
$ kubectl get pod -A
理解 Pod 内的不同容器状态
与 Pod 具有不同的阶段类似,Kubernetes 也会跟踪 Pod 内每个容器的状态。容器在创建和运行过程中可能处于三种状态:“Waiting”(等待)、“Running”(运行)和 “Terminated”(终止)。当 Kubernetes 调度器将 Pod 分配到节点后,Kubelet 会使用容器运行时(container runtime)为特定 Pod 创建容器。
可以使用以下命令查看容器状态:
$ kubectl describe pod <name-of-pod>
| 状态 | 描述 |
|---|---|
| Waiting | 该状态表示容器仍在创建过程中,尚未准备好运行。 |
| Running | 该状态表示容器已成功分配资源(CPU、内存),进程已启动。 |
| Terminated | 该状态表示容器的进程已停止运行。 |
Kubernetes 中的 CrashLoopBackOff 状态
在 Kubernetes 中,CrashLoopBackOff 状态表示 Pod 处于持续重启的循环中,即 Pod 内的一个或多个容器无法成功启动,并不断发生崩溃和重启。
通常情况下,容器在启动后崩溃,并不断被 Kubernetes 重新启动,这种情况被称为 CrashLoop。
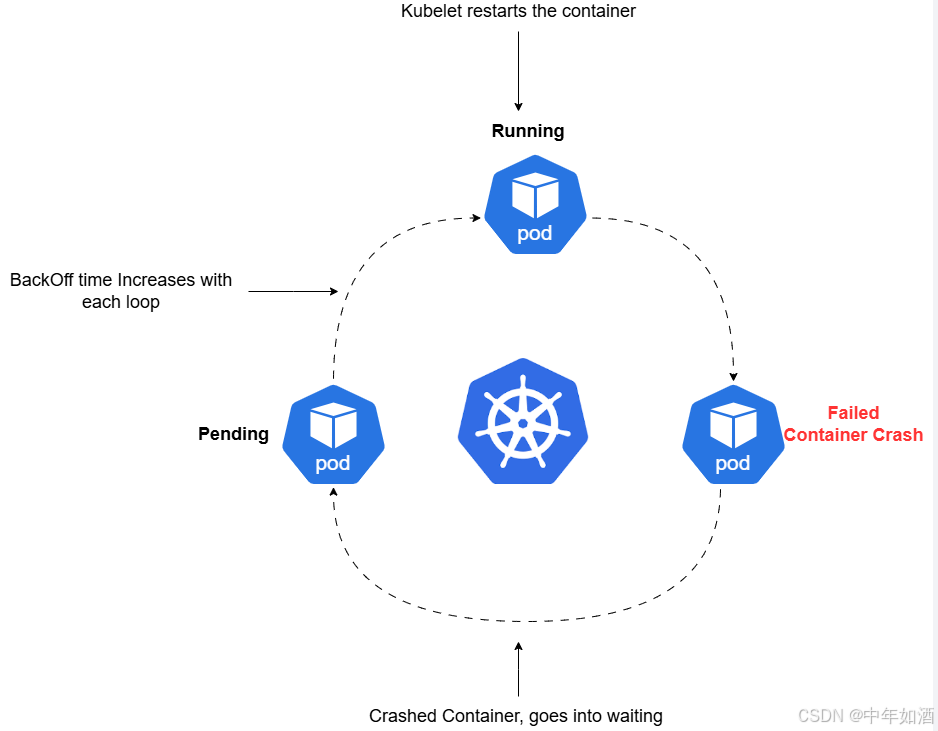
什么是BackOff时间及其重要性?
BackOff 算法是一种常见的重试机制,在计算机科学和网络通信领域广泛应用。当任务执行失败时,该算法通过逐步增加重试间隔的方式,避免频繁失败带来的资源浪费和系统压力。例如,在发送消息失败后,并不会立即再次尝试,而是等待一段时间后再重试。如果再次失败,则等待时间会逐步增加,形成指数增长的重试间隔。
在 Kubernetes 中,BackOff 时间 指的是 Pod 终止后重新启动前的延迟时间。该机制确保 Pod 有足够的时间恢复并解决潜在错误,同时避免频繁重启可能导致的资源浪费和系统过载。
例如,当 Pod 启动失败时,默认情况下(受 kubelet 配置影响),首次重试间隔为 10 秒。如果失败仍然持续,重试间隔通常会按 指数增长 方式翻倍,即:10 秒 → 20 秒 → 40 秒 → 80 秒,依此类推。kubelet 在每次重试时会使用该增长的间隔时间,并发送新的 API 请求来尝试重新启动 Pod 内的容器。
Kubernetes 重启策略概述
在 Kubernetes 中,Pod 具备自愈能力,能够在容器发生错误或崩溃时自动重启。此行为由 Pod 规范中的 restartPolicy 参数控制,用于定义 Kubernetes 处理容器故障的方式。restartPolicy 可能的取值包括 “Always”、“OnFailure” 和 “Never”,默认值为 “Always”。
- Always:无论容器退出状态如何,Kubernetes都会自动重启容器。
- OnFailure:仅在容器因错误退出(非零退出码)时重启容器。
- Never:无论容器退出状态如何,都不会重启容器。
通过合理配置restartPolicy,可以有效管理Pod中容器的生命周期,确保应用在故障时能够自动恢复或按需停止。
K8s重启策略配置
apiVersion: v1
kind: Pod
metadata:
name: my-nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
restartPolicy: Always #restart policy
检测 Kubernetes CrashLoopBackOff
可以使用 kubectl 命令检查 Pod 的状态,以确认是否处于 CrashLoopBackOff 状态。
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
default busybox 1/1 Running 2 (6d4h ago) 33d
default my-nginx 0/1 CrashLoopBackOff 12(2m5s ago) 5s
default nginx 1/1 Running 1 (6d4h ago) 18d
default nginx1 1/1 Running 1 (6d4h ago) 17d
default service-nginx-d8fb6d8fd-4jwtr 1/1 Running 1 (6d4h ago) 37d
default service-python-7f7c9d4fc4-hxmcz 1/1 Running 1 (6d4h ago) 37d
default webserver-574d8d4f99-qz6pf 1/1 Running 2 (6d4h ago) 43d
ingress-nginx ingress-nginx-admission-create-v9dwh 0/1 Completed 0 44d
ingress-nginx ingress-nginx-admission-patch-s6r2f 0/1 Completed 0 44d
ingress-nginx ingress-nginx-controller-7d56585cd5-mvwsq 1/1 Running 1 (6d4h ago) 44d
执行该命令后,将会看到类似上述的输出结果。其中,my-nginx Pod 处于以下状态:
- 未处于 Ready 状态
- 状态显示为 “CrashLoopBackOff”
- 重启次数为一次或多次
这表明 Pod 发生故障,并在多次尝试重启后仍未成功运行,因此进入 “CrashLoopBackOff” 状态。在此期间,可以分析失败或重启的原因。
Kubernetes 中导致 CrashLoopBackOff 的常见原因
- 资源限制问题
Kubernetes 资源分配对 Pod 的稳定运行至关重要。如果未合理设置内存限制,Pod 可能会进入 CrashLoopBackOff 状态。
例如,当应用程序的实际内存需求超过分配的内存时,会触发 OOM(Out Of Memory),导致 Pod 反复崩溃并尝试重启,从而进入 CrashLoopBackOff 状态。 - 镜像相关问题
- 权限不足:如果容器镜像缺少访问所需资源的权限,容器可能无法正常运行并发生崩溃。
- 镜像错误:如果 Pod 拉取了错误的容器镜像,可能会导致容器启动失败,从而进入反复崩溃和重启的状态。
- 配置错误
- 语法错误或拼写错误:在配置 Pod 规范(Pod spec)时,容器名称、镜像名称或环境变量可能存在拼写错误,导致容器无法正确启动。
- 资源请求与限制配置错误:requests(最小所需资源)和 limits(最大允许资源)配置不当,可能导致容器崩溃或无法正常启动。
- 缺少依赖项:如果 Pod 依赖的服务或组件缺失,容器可能启动失败,从而影响 Pod 的正常运行。
- 外部服务问题
- 网络问题:如果容器依赖的外部服务(如数据库)在启动时不可达或不可用,可能导致容器反复崩溃,从而触发 CrashLoopBackOff。
- 外部服务不可用:当 Pod 依赖的外部服务自身发生故障,容器无法建立连接,可能导致启动失败并进入 CrashLoopBackOff 状态。
- 未处理的应用异常
容器化应用在运行时遇到错误或异常,可能会导致应用崩溃。这些错误可能由多种原因引起,例如:
- 无效输入
- 资源限制
- 网络问题
- 文件权限问题
- Secrets 或环境变量配置错误
- 代码缺陷
如果应用程序缺少完善的错误处理机制,无法捕获和处理异常,可能导致容器不断崩溃并进入 CrashLoopBackOff 状态。
- Liveness 探针配置错误
Liveness 探针用于检测容器进程是否陷入死锁。如果探测失败,Kubernetes 会根据 Pod 的 restartPolicy 规则终止并重启容器。
常见的错误配置包括:
- 误判短暂的响应延迟:如果 Pod 由于负载过高而临时变慢,错误配置的 Liveness 探针可能会误判容器无响应,触发重启。
- 加剧问题:频繁的容器重启可能会进一步增加负载,而不是解决问题。
如何排查并解决 CrashLoopBackOff
从前面的内容可以看出,导致 Pod 进入 CrashLoopBackOff 状态的原因有多种。接下来介绍几种常见的排查方法。
排查的核心思路是:分析可能的原因,逐一调试并排除问题。
执行 kubectl get pods 命令时,如果 Pod 处于 CrashLoopBackOff 状态,需要进一步分析具体原因。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
app 1/1 Running 1 (3d12h ago) 8d
busybox 0/1 CrashLoopBackOff 18 (2m12s ago) 70m
hello-8n746 0/1 Completed 0 8d
my-nginx-5c9649898b-ccknd 0/1 CrashLoopBackOff 17 (4m3s ago) 71m
my-nginx-7548fdb77b-v47wc 1/1 Running 0 71m
- 查看 Pod 详细信息
使用 kubectl describe pod 命令可获取指定 Pod 和容器的详细状态信息,有助于分析问题原因。
$ kubectl describe pod pod-name
Name: pod-name
Namespace: default
Priority: 0
……………………
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: StartError
……………………
Warning Failed 41m (x13 over 81m) kubelet Error: container init was OOM-killed (memory limit too low?): unknown
执行 kubectl describe pod 后,可以从输出信息中提取关键内容,例如:
State:Waiting
Reason:CrashLoopBackOff
Reason:StartError
通过这些信息,可以分析 CrashLoopBackOff 的具体原因。例如,在输出的最后几行出现:
kubelet Error: container init was OOM-killed (memory limit too low?)
这表明容器因 内存不足(OOM-Killed) 而无法正常启动。
2. 查看 Pod 日志
日志记录了容器启动过程中的详细信息,包括运行中的异常、终止原因以及执行状态等。
可以使用以下命令查看 Pod 的日志:
- 提取只有一个容器的 pod 的日志。
$ kubectl logs pod-name
- 检查具有多个容器的 pod 的日志。
$ kubectl logs pod-name --all-conainers=true
- 可以按指定时间范围查看 Pod 日志。例如,要查看过去 1 小时内的日志,可以执行以下命令:
$ kubectl logs pod-name --since=1h
- 查看事件(Events)
事件(Events)提供了 Kubernetes 资源的最新状态信息。可以按命名空间查询,或针对特定工作负载进行筛选。
$ kubectl events
LAST SEEN TYPE REASON OBJECT MESSAGE
4h43m (x9 over 10h) Normal BackOff Pod/my-nginx-5c9649898b-ccknd Back-off pulling image "nginx:latest"
3h15m (x11 over 11h) Normal BackOff Pod/busybox Back-off pulling image "busybox"
40m (x26 over 13h) Warning Failed Pod/my-nginx-5c9649898b-ccknd Error: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: container init was OOM-killed (memory limit too low?): unknown
可以查看与资源相关的所有事件。
- 列出所有命名空间中的最新事件:
$ kubectl get events --all-namespaces
- 列出特定 pod 的所有事件:
$ kubectl events --for pod/pod-name
结论
本文详细探讨了 Kubernetes 中的 CrashLoopBackOff 现象。需要注意的是,CrashLoopBackOff 并不是具体的错误,而是一种状态。
文中分析了常见的 CrashLoopBackOff 状态,结合示例进行原因解析,并提供相应的解决方案,以帮助 Pod 恢复正常运行。
此外,还介绍了排查和解决 CrashLoopBackOff 状态的方法,以优化 Kubernetes 部署,提高系统的稳定性和可用性。


















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









