







文章目录
- 概要
- 命名空间之间的路由
- 同一节点上的 Pod 到 Pod 路由
- 跨节点的 Pod 间路由
- 总结
概要
在前一篇讨论网络接口的内容中,详细分析了如何识别所有参与 Pod 间路由的接口。同时,以简明的非技术语言阐述了 Cilium 在 Kubernetes 集群中的路由机制。接下来,将展示具体实现。
我们仍将沿用上一章节形成的示意图:
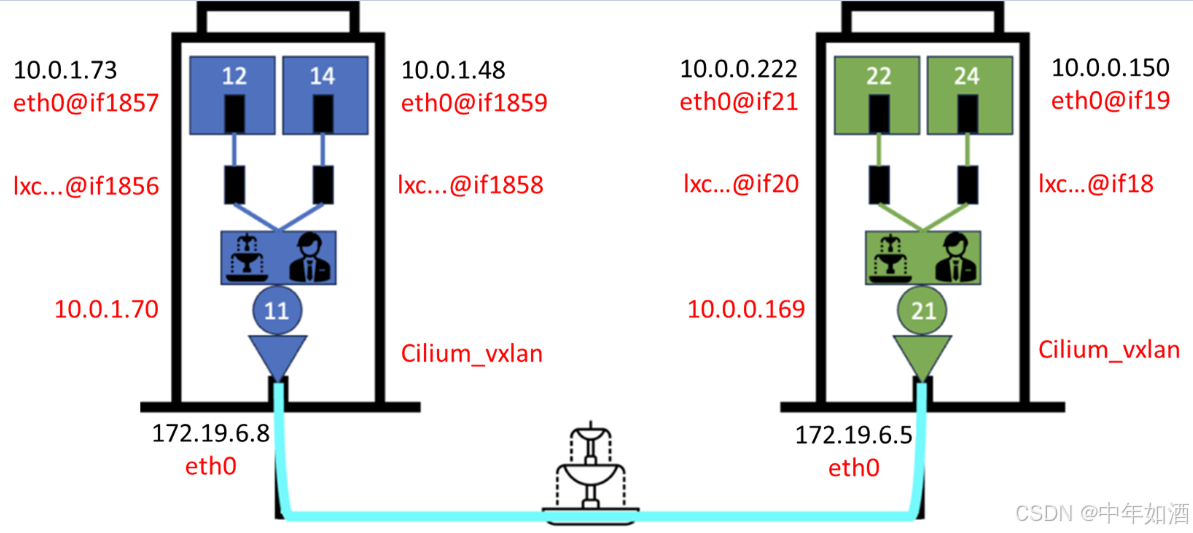
继续采用相同的方法,模拟数据包从左上角的公寓(Pod)10.0.1.73 出发,传递至 Kubernetes 集群中的其他 Pod。在此之前,将看看命名空间的概念,并通过新的类比进一步完善示意图。
命名空间之间的路由
命名空间是一种逻辑对象组,用于在集群中实现隔离。然而,在默认配置的 Kubernetes 集群中,所有 Pod 无论是否属于同一命名空间,都可以彼此通信。因此,命名空间的隔离功能并不等同于限制 Pod 之间的通信。若需控制这种通信行为,需要通过创建网络策略来实现。
命名空间可以类比为集群中所有建筑的同一楼层。每座建筑内处于相同楼层的所有公寓在逻辑上归属于同一命名空间。以下示例展示了命名为 web 的命名空间结构。
$ kubectl get pods -n web -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-77598f9f86-g4dqg 1/1 Running 0 19h 10.0.1.73 k8sworker1.pci.co.id <none> <none>
redis-77598f9f86-hpmsh 1/1 Running 0 18h 10.0.0.222 k8smaster.pci.co.id <none> <none>
service-python-7f7c9d4fc4-jhp4d 1/1 Running 0 8d 10.0.1.135 k8sworker1.pci.co.id <none> <none>
webserver-5f9579b5b5-4vj77 1/1 Running 0 19h 10.0.0.150 k8smaster.pci.co.id <none> <none>
webserver-5f9579b5b5-qw2m4 1/1 Running 0 19h 10.0.1.48 k8sworker1.pci.co.id <none> <none>
这是一层楼上的四个公寓/Pod,被归类为同一个命名空间:
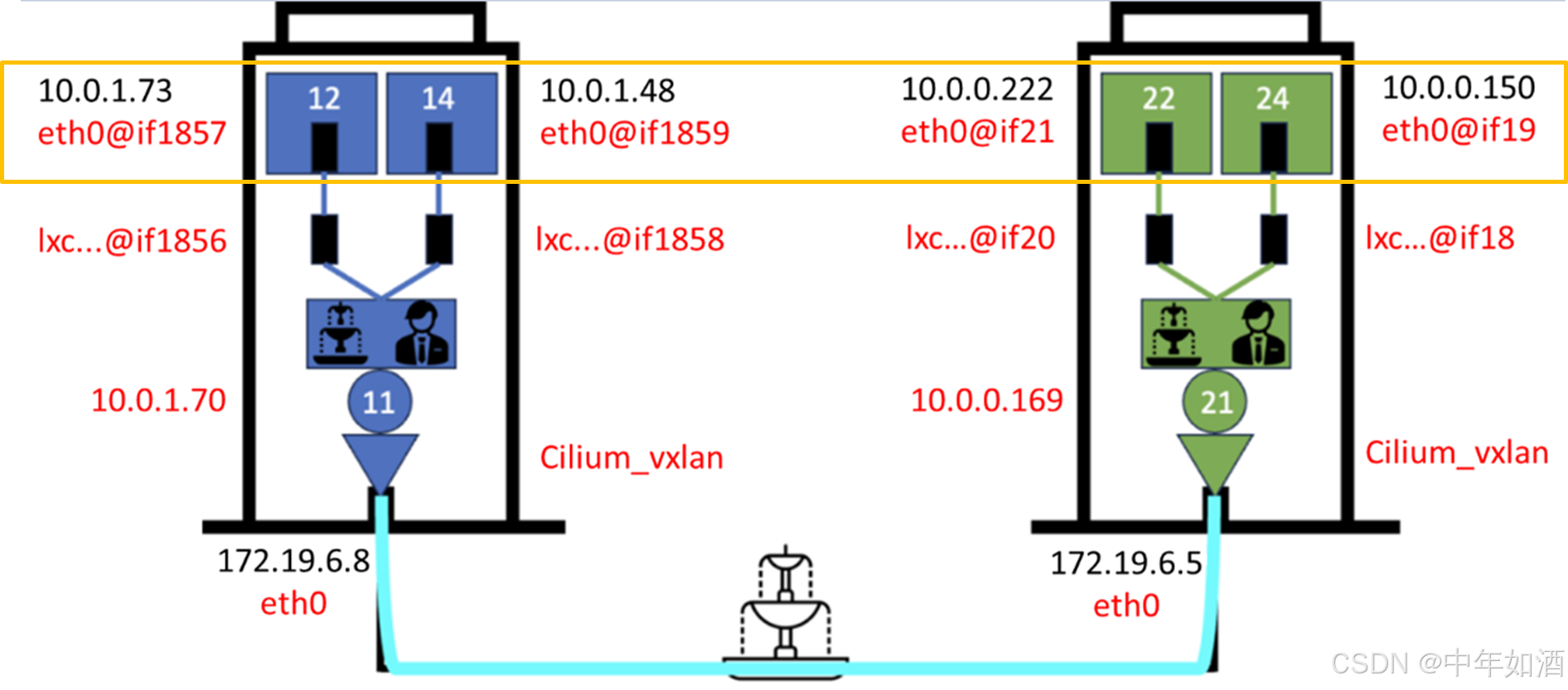
路由过程不涉及 Pod 所在的命名空间,仅使用目标 IP 地址。接下来,将展示如何从同一栋大楼(节点)中的公寓 10.0.1.73路由至公寓 10.0.1.48。
同一节点上的 Pod 到 Pod 路由
从 Pod 10.0.1.73 启程,目标为访问 10.0.1.48。首先,需查阅路由表以确定到达目标的路径。然而,在出发之前,必须获取目标的 MAC 地址。只有同时获得目标的 IP 地址和 MAC 地址,才能开始路由过程。因此,需要查看 ARP 表,查找目标的 MAC 地址。ARP 表包含了同一 IP 子网内已知的 MAC 地址与 IP 地址的映射。如果该地址不在表中,则会发送 ARP 请求,向网络中的其他设备查询目标的 MAC 地址。收到目标地址后,将其记录到 ARP 表中。此时,经过确认,已准备好启动路由过程,Pod 开始出发。
接下来,分析如何在源 Pod 10.0.1.73中追踪该过程。
$ kubectl exec -it -n web redis-77598f9f86-g4dqg -- ip route
default via 10.0.1.70 dev eth0 mtu 1450
10.0.1.70 dev eth0 scope link
路由指令非常简洁,对于每个目标,均通过 10.0.1.70,并使用 Pod 中的唯一网络接口 eth0。可以从上述示意图中看出,10.0.1.70是 cilium_host 的 IP 地址。接下来,检查 ARP 表:
$ kubectl exec -it -n web redis-77598f9f86-g4dqg -- arp -a
arp -a 命令列出了 ARP 表的内容,但其中没有任何记录。
一种发送侦查请求的方法是使用 arping 工具向目标发送请求。
需要注意的是,假如所使用镜像不包含这些 命令,可以使用下面的方式安装
kubectl exec -it -n web redis-77598f9f86-g4dqg -- apt update
kubectl exec -it -n web redis-77598f9f86-g4dqg -- apt install net-tools
kubectl exec -it -n web redis-77598f9f86-g4dqg -- apt update arping
当然,建议尽量使用 busybox 和 netshoot镜像,这些镜像提供了在故障排除过程中非常有用的网络工具。
确认有了这些网络命令工具后,可以向目标发出请求:
$ kubectl exec -it -n web redis-77598f9f86-g4dqg -- arping 10.0.1.48
arping: lookup dev: No matching interface found using getifaddrs().
arping: Unable to automatically find interface to use. Is it on the local LAN?
arping: Use -i to manually specify interface. Guessing interface eth0.
ARPING 10.0.1.48
58 bytes from 9a:a4:00:74:ef:bb (10.0.1.48): index=0 time=5.200 usec
58 bytes from 9a:a4:00:74:ef:bb (10.0.1.48): index=1 time=7.701 usec
58 bytes from 9a:a4:00:74:ef:bb (10.0.1.48): index=2 time=7.401 usec
缺失的信息,即目标的 MAC 地址,现已获取。接下来,可验证该信息是否已记录在源 Pod 的 ARP 表中:
$ kubectl exec -it -n web redis-77598f9f86-g4dqg -- arp -a
? (10.0.1.70) at 9a:a4:00:74:ef:bb [ether] on eth0
所需信息已成功获取。然而,可能会疑惑为何在此未显示目标 IP 地址 10.0.1.48。在传统网络中,通常能够看到目标 IP 地址,但在 Kubernetes 集群中,网络由 Cilium 管理。此外,从源 Pod 的路由表可以观察到,所有目标的通信均通过 cilium_host 接口进行。
因此,即便是在同一 IP 子网内的 Pod 间进行通信,节点上的 cilium_host 依然会接收并处理所有流量。
此外,以下命令可用于快速显示集群中 cilium_host 和各节点的所有 IP 地址:
$ kubectl get ciliumnodes
NAME CILIUMINTERNALIP INTERNALIP AGE
k8smaster.pci.co.id 10.0.0.169 172.19.6.5 49d
k8sworker1.pci.co.id 10.0.1.70 172.19.6.8 47d
在传统网络的二层交换中,目标 MAC 地址通常与目标 IP 地址直接关联。然而,在 Kubernetes 网络中情况有所不同。那么,究竟是哪一个接口的 MAC 地址为 9a:a4:00:74:ef:bb ?以下将对此进行解析:
$ ip a | grep -B1 -A2 -i "9a:a4:00:74:ef:bb"
1857: lxc45ed99168f62@if1856: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 9a:a4:00:74:ef:bb brd ff:ff:ff:ff:ff:ff link-netns cni-635aef78-02ec-0461-5e37-830ca81c8812
inet6 fe80::98a4:ff:fe74:efbb/64 scope link
valid_lft forever preferred_lft forever
该 MAC 地址对应的是节点的 LXC 接口,这是源 Pod 通往目标的下一步路径。在本系列网络文章的第一篇中已提及,在 LXC 接口处有一个“服务者”等待(配置了一个服务组件),于引导通信流向目标
从传统的 Linux 路由视角来看,此处目标的通信路径并不直观。这是因为路由由 Cilium Agent 使用 eBPF 技术完成。鉴于目标与源 Pod 位于同一 IP 子网内,Cilium Agent 会将流量直接切换至目标的 LXC 接口,最终到达目标 Pod。
目标 Pod 在响应源 Pod 时,会经历相同的过程。为确保表述完整,以下展示了目标 Pod 中的路由表和 ARP 表:
$ kubectl exec -it -n web webserver-5f9579b5b5-qw2m4 -- ip route
default via 10.0.1.70 dev eth0 mtu 1450
10.0.1.70 dev eth0 scope link
$ kubectl exec -it -n web webserver-5f9579b5b5-qw2m4 -- arp -a
? (10.0.1.70) at a6:bf:8b:47:ee:3e [ether] on eth0
$ ip a | grep -B1 -A2 -i "a6:bf:8b:47:ee:3e"
1859: lxc9a32fc44db3c@if1858: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:bf:8b:47:ee:3e brd ff:ff:ff:ff:ff:ff link-netns cni-980c48cf-6b31-2ca3-4b39-fa0b409a1b66
inet6 fe80::a4bf:8bff:fe47:ee3e/64 scope link
valid_lft forever preferred_lft forever
从传统 Linux 路由的视角来看,所有流量均被转发至 cilium_host,目标 MAC 地址则对应于节点中与 Pod 关联的 LXC 接口。这一行为与源 Pod 的情况完全相同。
跨节点的 Pod 间路由
接下来将探讨如何从源 Pod 10.0.1.73(位于某一节点)访问目标 Pod 10.0.0.222(位于另一节点)。初始的路由过程与之前相同,但当流量到达 LXC 接口的“服务者”时,目标 IP 地址被判定为不属于同一 IP 子网,因此流量会被引导至大厅中的 cilium_host。随后,流量通过 cilium_vxlan 接口进行路由,最终到达托管目标 Pod 的节点。
现将查看主机的路由表:
kubeuser@k8sworker1:~$ ip route
default via 172.19.7.254 dev eth0 proto static
10.0.0.0/24 via 10.0.1.70 dev cilium_host proto kernel src 10.0.1.70 mtu 1450
10.0.1.0/24 via 10.0.1.70 dev cilium_host proto kernel src 10.0.1.70
10.0.1.70 dev cilium_host proto kernel scope link
172.19.6.0/23 dev eth0 proto kernel scope link src 172.19.6.8
在此并未呈现太多信息,因为路由是通过 eBPF 完成的,并由 Cilium Agent 管理,正如前述所示。
另外,为了全面展示相关信息,Cilium Agent Pod 中的网络接口输出和 ip route 与节点的完全相同。这是因为在启动时,Cilium Agent 会将这些信息提供给节点。可通过以下命令检查 Cilium Agent:
kubectl exec -it -n kube-system cilium-kbwq7 -- ip a
kubectl exec -it -n kube-system cilium-kbwq7 -- ip route
因此,流量通过 VXLAN 隧道到达节点 目标节点。以下是该节点的路由表
kubeuser@k8smaster:~/yaml$ ip route
default via 172.19.7.254 dev eth0 proto static
10.0.0.0/24 via 10.0.0.169 dev cilium_host proto kernel src 10.0.0.169
10.0.0.169 dev cilium_host proto kernel scope link
10.0.1.0/24 via 10.0.0.169 dev cilium_host proto kernel src 10.0.0.169 mtu 1450
172.19.6.0/23 dev eth0 proto kernel scope link src 172.19.6.5
从传统的 Linux 路由视角来看,除了所有针对 Pod 子网的流量都会被引导到由 Cilium Agent 管理的 cilium_host 外,并未显示出更多的内容。这一过程与在其他节点所观察到的情况完全一致。当流量到达 cilium_vxlan 接口时,借助 eBPF 映射,流量将被引导通过一条隐秘通道,最终到达左上角 Pod 的 LXC 区域接口,进而抵达目标。
总结
Cilium 在 Kubernetes 中使用 eBPF 进行数据包路由的工作原理。在传统 Linux 路由视角下,流量会通过常规路由过程传递,但 Cilium 通过 eBPF 技术实现了更高效的路由。特别是,Cilium 使用了“服务者”模式和秘密通道,使得流量在 Kubernetes 集群内部更加迅速和精确地转发。
在跨节点路由中,Cilium 会将流量通过 cilium_vxlan 接口传递,进一步利用 eBPF 引导流量到达目标 Pod。而通过传统 Linux 路由命令查看时,虽然看不见所有的细节,但通过 Cilium 代理的管理和 eBPF 的支持,流量路由的速度显著提升。
总的来说,Cilium 的网络路由通过结合传统网络技术与现代的 eBPF 技术,提供了更高效、灵活的网络连接方案。
kubeneters-循序渐进Cilium网络(一)
kubeneters-循序渐进Cilium网络(二)
kubeneters-循序渐进Cilium网络(三)
[kubeneters-循序渐进Cilium网络(四)


















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









