







Python 爬虫之微信公众号
源代码放在文末。
本次爬虫需要的工具如下:
- selenium 驱动器
- 对应浏览器的 webdriver
- 一个微信订阅号
在 2017 年 6 月左右,微信官方发布一篇文章 https://mp.weixin.qq.com/s/67sk-uKz9Ct4niT-f4u1KA,大致意思就是以后发布文章的时候可以插入其他公众号的文章。由此,我们即可获得采集文章的接口。
一、登陆微信公众号
在这里,我们使用 selenium + chromedriver(chrome 的 webdriver) 的方式来获取登陆的 cookie,这样,以后爬取文章时只需要载入 cookie 即可登陆。首先我们打开微信公众平台进行账号登陆:
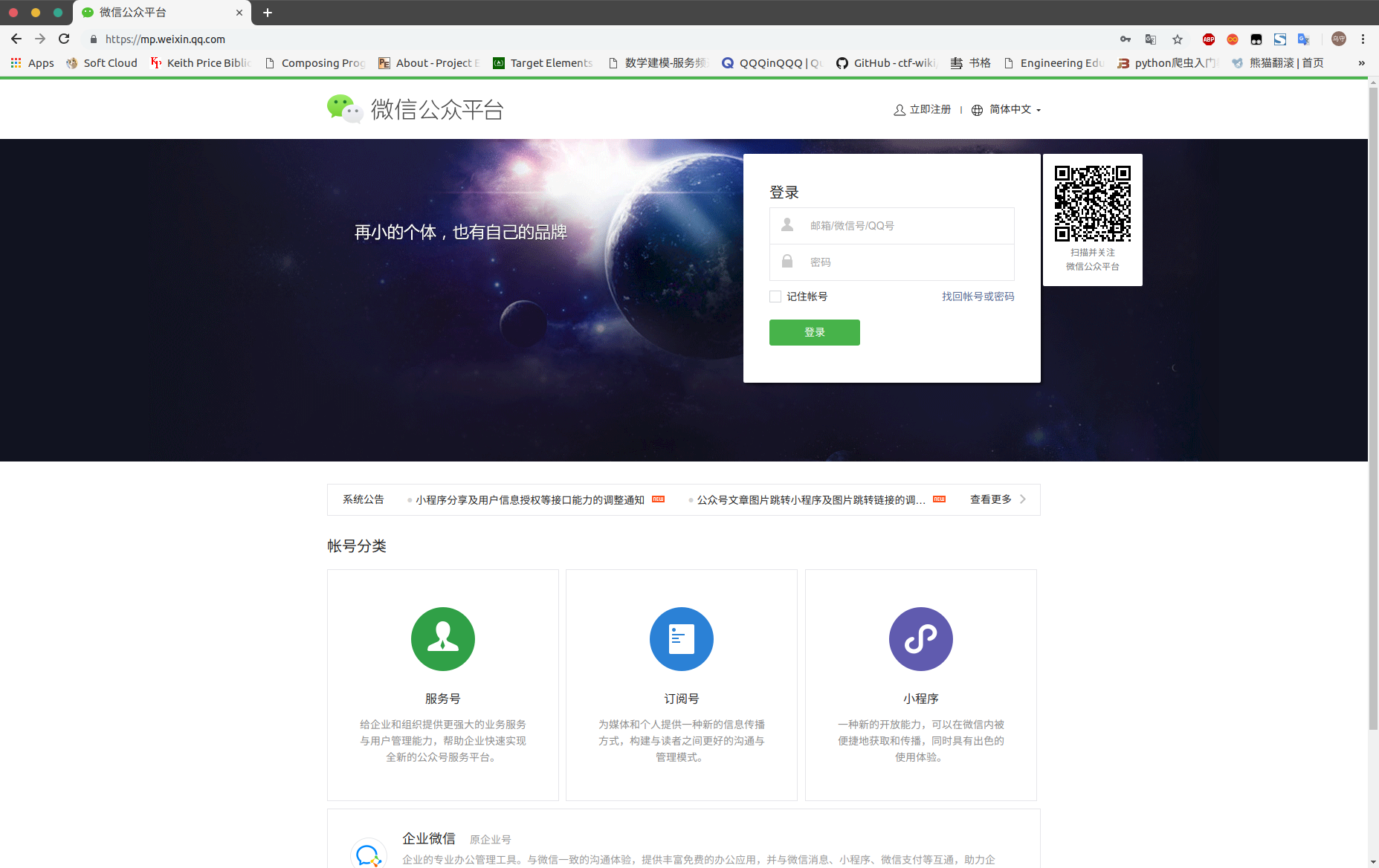
我们用 insepect 检查获取登陆的账号、密码元素所在位置,来实现自动化登陆的目的 。
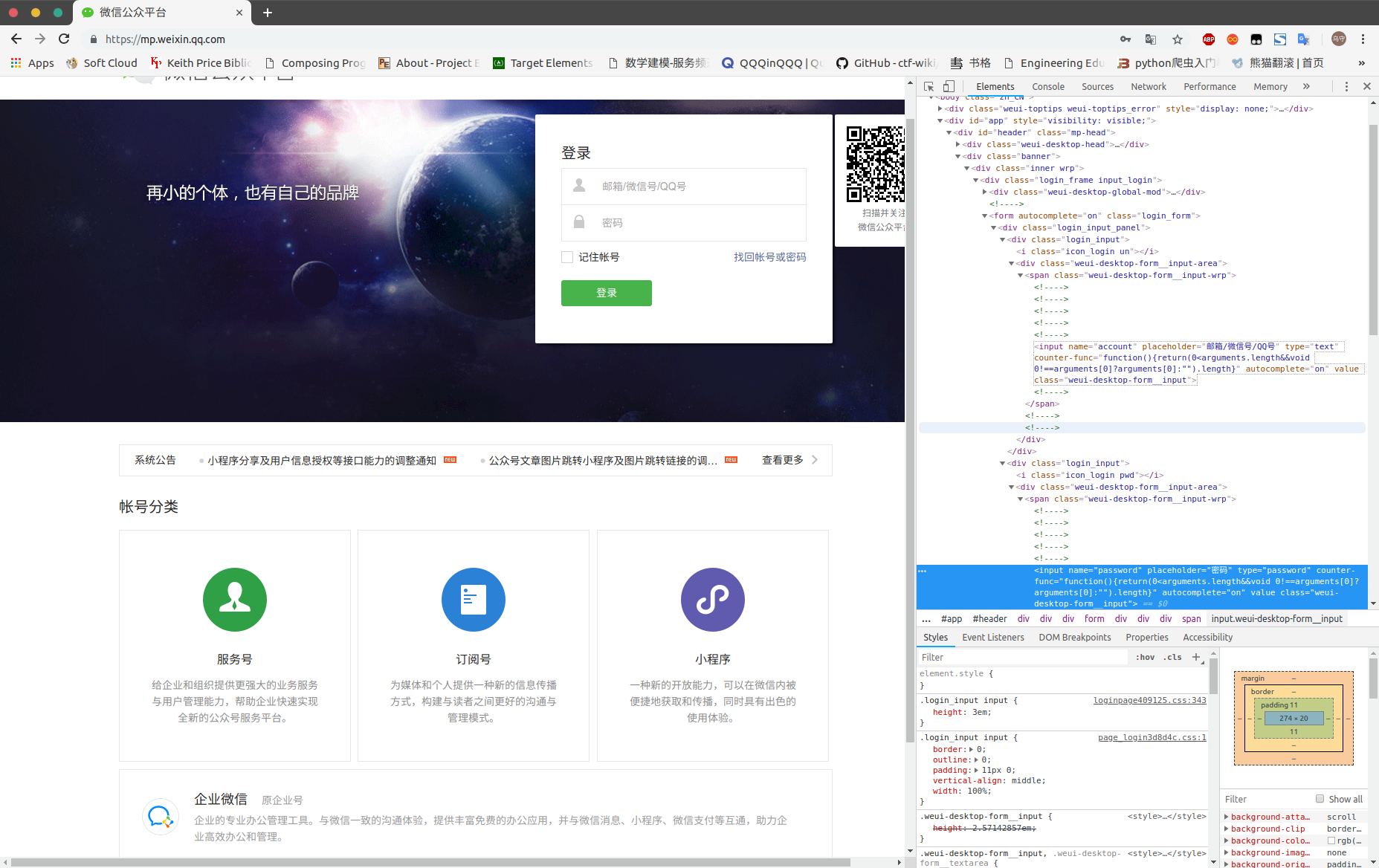
转化成代码如下:
# 用webdriver启动谷歌浏览器
print("启动浏览器,打开微信公众号登录界面")
driver = webdriver.Chrome(executable_path='/usr/bin/chromedriver')
# 此处 webdriver 根据自己的环境更改
# 打开微信公众号登录页面
driver.get('https://mp.weixin.qq.com/')
# 等待5秒钟
time.sleep(5)
print("正在输入微信公众号登录账号和密码......")
#清空账号框中的内容
driver.find_element_by_name("account").clear()
#自动填入登录用户名
driver.find_element_by_name("account").send_keys("输入你的公众号账号")
#清空密码框中的内容
driver.find_element_by_name("password").clear()
#自动填入登录密码
driver.find_element_by_name("password").send_keys("输入公众号密码")
# 在自动输完密码之后需要手动点一下记住我
print("请在登录界面点击:记住账号")
time.sleep(5)
#自动点击登录按钮进行登录
driver.find_element_by_class_name("btn_login").click()
# 拿手机扫二维码!
print("请拿手机扫码二维码登录公众号")
time.sleep(20)
print("登录成功")
之后,我们需要重新登陆一次,保存 cookie,以后则载入 cookie 即可,不需要再扫码登陆。代码如下:
# 定义一个空的字典,存放cookies内容
post = {
}
driver.get('https://mp.weixin.qq.com/')
# 获取cookies
cookie_items = driver.get_cookies()
# 获取到的cookies是列表形式,将cookies转成json形式并存入本地名为cookie的文本中
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print("cookies信息已保存到本地")
之后我们开始文章的爬取。
二、爬取文章
根据官方描述,接口应该藏在新建图文素材中的插入超链接中,和之前爬取币乎一样,我们用 F12-Network-XHR 来跟踪这几个页面来获取我们需要配置的请求:
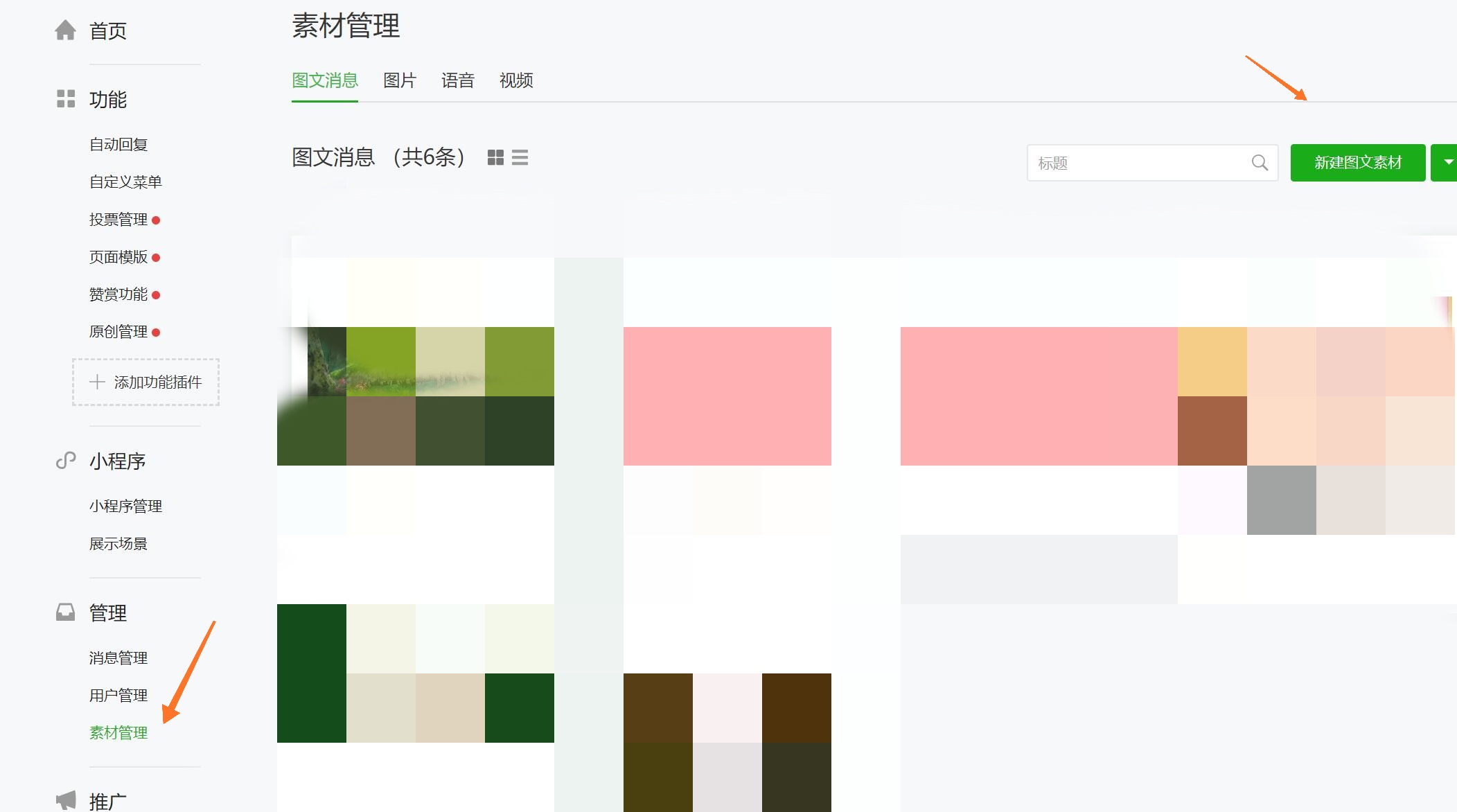
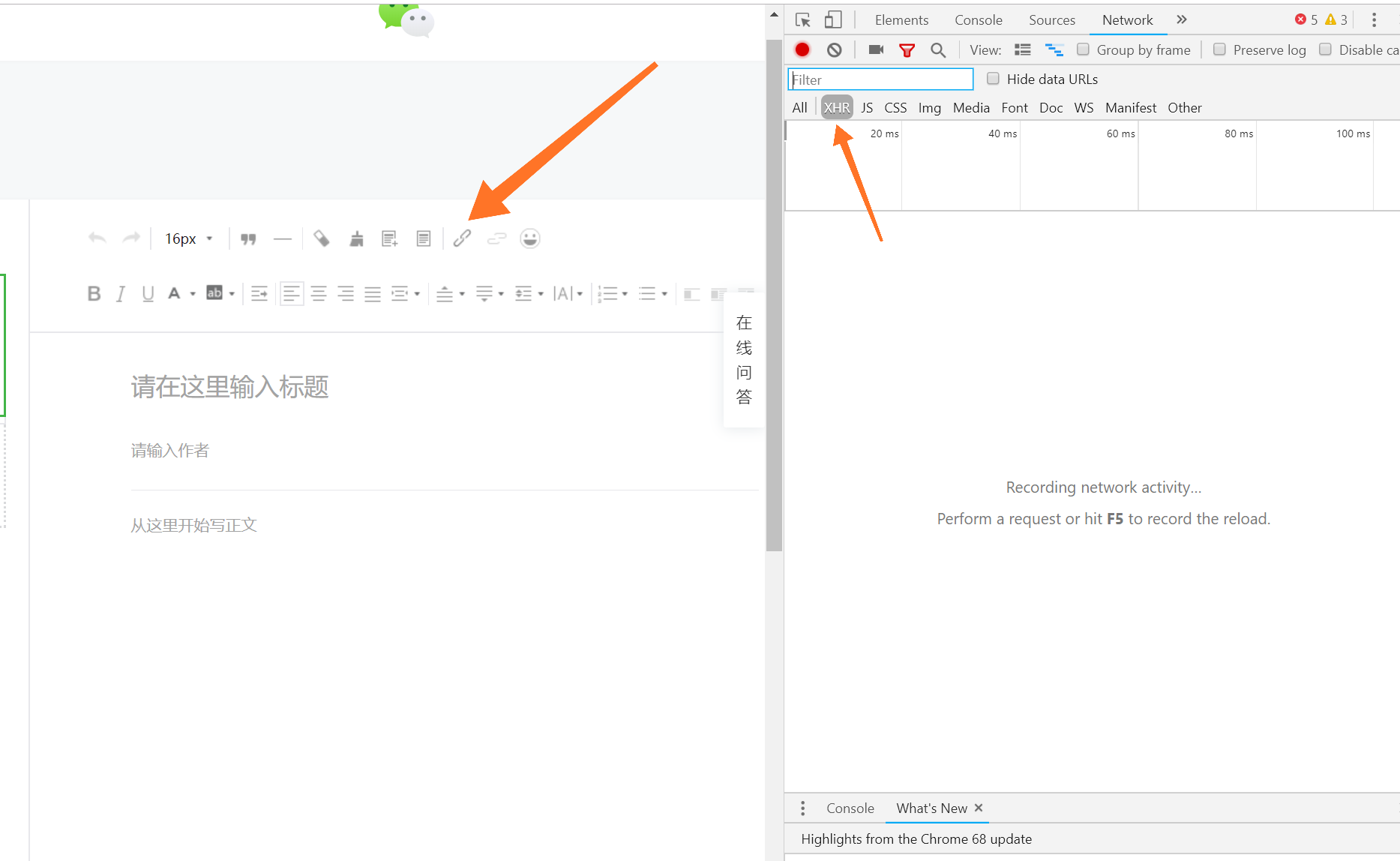
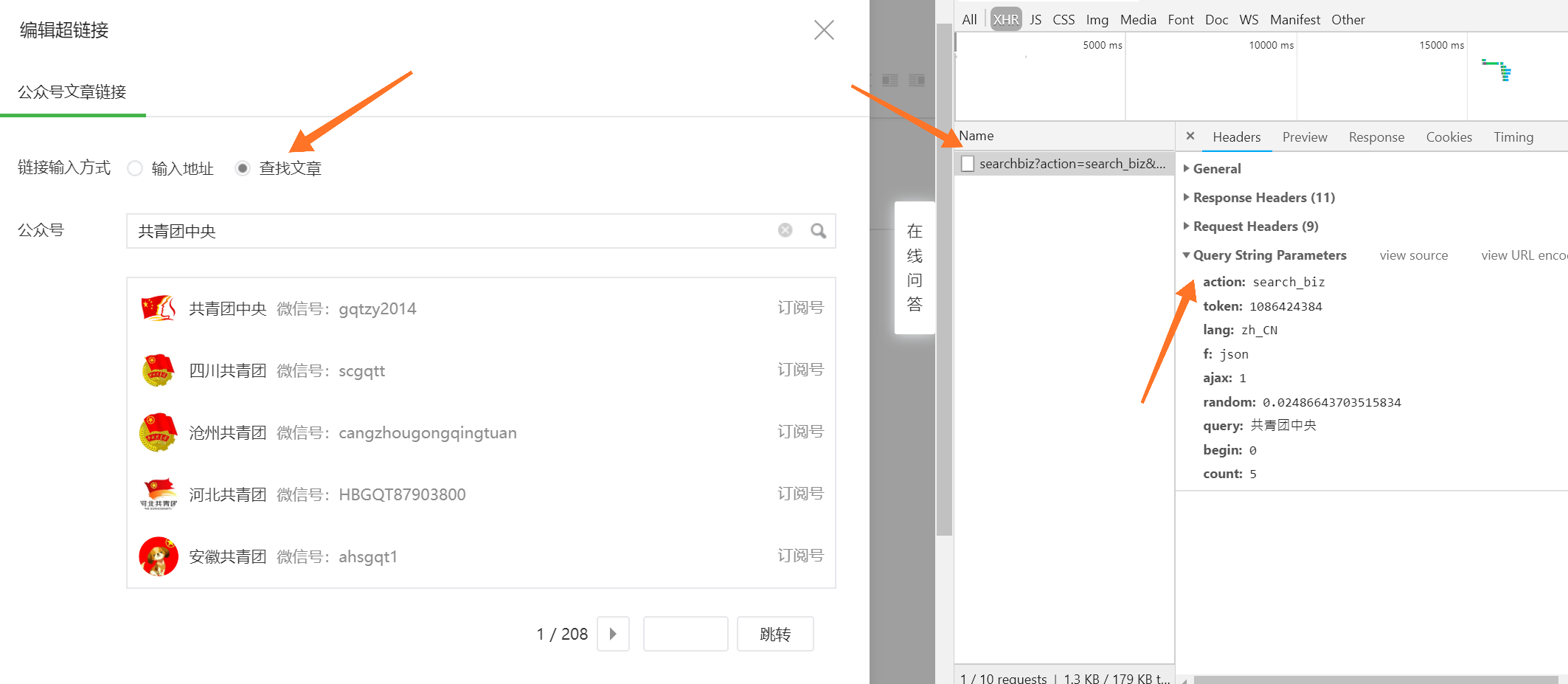
接下来,我们来配置请求参数:
#公众号主页
url = 'https://mp.weixin.qq.com'
#设置headers
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
#读取上一步获取到的cookies
with  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









