







 本文详细介绍了Pandas库的基础概念,包括Series和DataFrame的创建、索引、切片、读取数据、数据操作与筛选,以及DataFrame的高级操作如排序、取值和布尔索引。适合数据分析师和初学者学习数据处理技巧。
本文详细介绍了Pandas库的基础概念,包括Series和DataFrame的创建、索引、切片、读取数据、数据操作与筛选,以及DataFrame的高级操作如排序、取值和布尔索引。适合数据分析师和初学者学习数据处理技巧。
pandas模块
1. 基本概念
pandas是建立在numpy之上的,用于数据操纵和分析的一个库。
pandas常用的数据结构有两种:Series和DataFrame。
2. Series的基本操作
Series对象本质上由两个数组构成,一个数组构成对象的键(index索引),一个数组构成对象的值(values),键 -> 值。
2.1 Series的创建方法
import pandas as pd
a = pd.Series(data, index)
举例:
import pandas as pd
import numpy as np
# 传入可迭代数据之列表[],创建Series
p1 = pd.Series([1, 2, 34, 32, 56, 788, 67])
print(p1)
print(type(p1))
print(p1.dtype)
# 传入数据data,同时传入索引index,创建Series
p2 = pd.Series([1, 2, 34, 56, 34, 12, 78], index=list("abcdefg"))
print(p2)
# 传入字典{}创建Series
temp_dict = {"name": "wuyanzu", "age": 22, "tel": 10086}
p3 = pd.Series(temp_dict)
print(p3)
执行结果:
0 1
1 2
2 34
3 32
4 56
5 788
6 67
dtype: int64
<class 'pandas.core.series.Series'>
int64
a 1
b 2
c 34
d 56
e 34
f 12
g 78
dtype: int64
name wuyanzu
age 22
tel 10086
dtype: object
2.2 获取Series中数据的index、values
import pandas as pd
import numpy as np
temp_dict = {"name": "wuyanzu", "age": 22, "tel": 10086}
p3 = pd.Series(temp_dict)
print(p3)
print(p3.dtype)
print(p3.index)
print(type(p3.index))
print(p3.values)
print(type(p3.values))
执行结果:
name wuyanzu
age 22
tel 10086
dtype: object
object
Index(['name', 'age', 'tel'], dtype='object')
<class 'pandas.core.indexes.base.Index'>
['wuyanzu' 22 10086]
<class 'numpy.ndarray'>
2.3 Series的切片和索引
2.3.1 切片
切片直接传入start、end、步长即可,步长默认为1。
import pandas as pd
import numpy as np
import string
t = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
print("创建Series类型的对象:\n", t)
t1 = t[0:5]
print("切片得到的结果:\n", t1)
执行结果:
创建Series类型的对象:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int32
切片得到的结果:
A 0
B 1
C 2
D 3
E 4
dtype: int32
2.3.2 索引
一个Series对象中的元素其实就是一组组“键值对”。
(1)传入单个索引,获得对应索引的值;
(2)传入多个索引组成的列表时,获得对应索引的键值对;
(3)传入的是某个“值”,返回就是该值;
(4)传入条件语句,返回满足条件的键值对;
(5)传入的单个索引或索引列表中的索引不存在时,返回的值、键值对中的值为nan(验证后报错?)。
t = pd.Series(np.arange(10), index=list(string.ascii_uppercase[:10]))
print("创建Series类型的对象:\n", t)
t1 = t[0:5]
print("切片得到的结果:\n", t1)
# 传入某个“值”,返回该值
print(t[1])
# 传入某个index,返回对应的value
print(t["A"])
# 传入index索引列表,返回对应的键值对
t2 = t[['A', 'D', 'E']]
print(t2)
# 传入条件语句t > 4,即得到value大于4的键值对
print(t[t > 4])
执行结果:
创建Series类型的对象:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int32
切片得到的结果:
A 0
B 1
C 2
D 3
E 4
dtype: int32
1
0
A 0
D 3
E 4
dtype: int32
F 5
G 6
H 7
I 8
J 9
dtype: int32
2.4 pandas读取外部数据
import pandas as pd
#pandas读取csv中的文件
df = pd.read_csv("D:/人工智能课程/【4】14100_HM数据科学库课件/数据分析资料/day04/code/dogNames2.csv")
print(df)
执行结果:
Row_Labels Count_AnimalName
0 1 1
1 2 2
2 40804 1
3 90201 1
4 90203 1
... ... ...
16215 37916 1
16216 38282 1
16217 38583 1
16218 38948 1
16219 39743 1
[16220 rows x 2 columns]
3.DataFrame的基本操作
3.1 DataFrame的创建
3.1.1 传入可迭代对象创建DataFrame对象
DataFrame对象既有行索引,又有列索引。
(1)行索引:表明不同行,横向索引,叫index,axis=0;
(2)列索引:表明不同列,纵向索引,叫columns,axis=1.
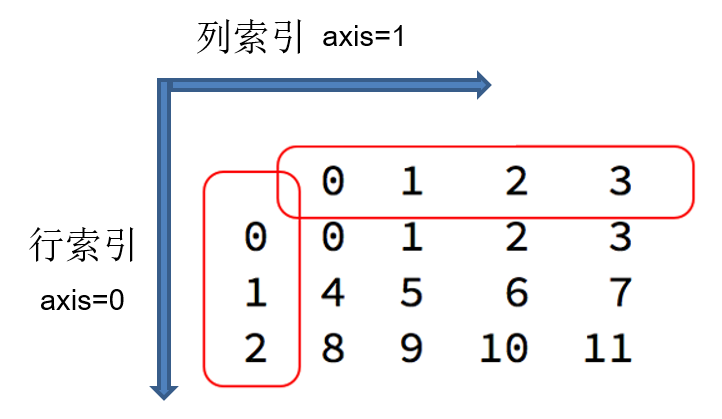
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(3, 4))
print(df)
执行结果:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3.1.2 传入可迭代对象、index、columns创建DataFrame
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
print(df)
执行结果:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
3.1.3 传入列表创建DataFrame
传入的列表中某个键值对不存在时,保留对应的位置,返回NAN。
import pandas as pd
import numpy as np
list1 = {"name": ["xiaoming", "xiaowang"], "age": [15, 23], "tel": [10023, 12340]}
df1 = pd.DataFrame(list1)
print(df1)
# 传入的列表中某个键值对不存在时,返回NAN
list2 = [{"name": "Tom", "age": 18, "tel": 10089}, {"age": 22, "tel": 10078}, {"name": "Lucy", "tel": 12789}]
df2 = pd.DataFrame(list2)
print(df2)
执行结果:
name age tel
0 xiaoming 15 10023
1 xiaowang 23 12340
name age tel
0 Tom 18.0 10089
1 NaN 22.0 10078
2 Lucy NaN 12789
3.2 DataFrame的基础属性
import pandas as pd
import numpy as np
list2 = [{"name": "Tom", "age": 18, "tel": 10089}, {"age": 22, "tel": 10078}, {"name": "Lucy", "tel": 12789}]
print(list2)
df2 = pd.DataFrame(list2)
print(df2)
print("DataFrame对象的行数、列数:", df2.shape)
print("DataFrame对象的列数据类型:", df2.dtypes)
print("DataFrame对象的数据维度:", df2.ndim)
print("DataFrame对象的行索引:", df2.index)
print("DataFrame对象的列索引:", df2.columns)
print("DataFrame对象的对象值:", df2.values)
执行结果:
name age tel
0 Tom 18.0 10089
1 NaN 22.0 10078
2 Lucy NaN 12789
DataFrame对象的行数、列数: (3, 3)
DataFrame对象的列数据类型:
name object
age float64
tel int64
dtype: object
DataFrame对象的数据维度: 2
DataFrame对象的行索引: RangeIndex(start=0, stop=3, step=1)
DataFrame对象的列索引: Index(['name', 'age', 'tel'], dtype='object')
DataFrame对象的对象值:
[['Tom' 18.0 10089]
[nan 22.0 10078]
['Lucy' nan 12789]]
3.3 DataFrame对象的整体情况查询
df.head(3) # 显示头部几行,默认5行
df.tail(3) # 显示末尾几行,默认5行
df.info() # 相关信息概览:行数、列数、列索引、列非空值个数、列类型、内存占用
df.describe() # 快速综合统计结果:计数、均值、标准差、最大值、四分位数(x%的中位数)、最小值
import pandas as pd
import numpy as np
list2 = [{"name": "Tom", "age": 18, "tel": 10089}, {"age": 22, "tel": 10078}, {"name": "Lucy", "tel": 12789}]
print(list2)
df2 = pd.DataFrame(list2)
print(df2)
print("头部2行:", df2.head(2))
print("尾部2行:", df2.tail(2))
print("相关信息概览:")
print(df2.info())
print("快速综合统计结果:\n", df2.describe())
执行结果:
头部2行:
name age tel
0 Tom 18.0 10089
1 NaN 22.0 10078
尾部2行:
name age tel
1 NaN 22.0 10078
2 Lucy NaN 12789
相关信息概览:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 2 non-null object
1 age 2 non-null float64
2 tel 3 non-null int64
dtypes: float64(1), int64(1), object(1)
memory usage: 200.0+ bytes
None
快速综合统计结果:
age tel
count 2.000000 3.000000
mean 20.000000 10985.333333
std 2.828427 1562.030836
min 18.000000 10078.000000
25% 19.000000 10083.500000
50% 20.000000 10089.000000
75% 21.000000 11439.000000
max 22.000000 12789.000000
3.4 DataFrame对象排序
import pandas as pd
import numpy as np
list2 = [{"name": "Tom", "age": 18, "tel": 10089}, {"name": "Lulu", "age": 34, "tel": 10078},
{"name": "Lucy", "age": 23, "tel": 12789}]
df2 = pd.DataFrame(list2)
print(df2)
print("排序:")
df_sort = df2.sort_values(by="age", ascending=False) #ascending默认是True,升序
print(df_sort)
执行结果:
name age tel
0 Tom 18 10089
1 Lulu 34 10078
2 Lucy 23 12789
排序:
name age tel
1 Lulu 34 10078
2 Lucy 23 12789
0 Tom 18 10089
3.5 pandas取行或者取列
(1)方括号写数组,表示取行,对行进行操作
(2)写字符串,表示的去列索引,对列进行操作
import pandas as pd
import numpy as np
list2 = [{"name": "Tom", "age": 18, "tel": 10089}, {"name": "Lulu", "age": 34, "tel": 10078},
{"name": "Lucy", "age": 23, "tel": 12789}]
df2 = pd.DataFrame(list2)
print(df2)
print("取行、取列操作")
print("取0、1行:\n",df2[0:2])
print("取age列:\n",df2["age"])
print("取0、1行,age列\n",df2[0:2]["age"])
执行结果:
name age tel
0 Tom 18 10089
1 Lulu 34 10078
2 Lucy 23 12789
取行、取列操作
取0、1行:
name age tel
0 Tom 18 10089
1 Lulu 34 10078
取age列:
0 18
1 34
2 23
Name: age, dtype: int64
取0、1行,age列
0 18
1 34
Name: age, dtype: int64
3.5 pandas获取行列数据之loc、iloc
(1)df.loc[]通过索引获取数据。
(2)df.iloc[]通过位置获取数据 。
(3)行和列之间使用逗号“,”分隔开来;loc中使用 “ : ”切片时,左闭右闭,包括[ ] 右边的元素。
3.5.1 df.loc[]
import pandas as pd
import numpy as np
t = pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
print(t)
# 通过索引获取行列交点,该方法得到的数据是numpy.int32
print(t.loc["a", "W"])
print(type(t.loc["a", "W"]))
# 通过索引获取行列交点,该方法得到的数据是DataFrame对象
print(t.loc[["a"], ["W"]])
print(type(t.loc[["a"], ["W"]]))
# 通过索引获取单行多列(单列多行),该方法得到的数据是Series对象
print(t.loc["a", ["W", "X"]])
print(type(t.loc["a", ["W", "X"]]))
# 通过索引获取间隔的多行多列,该方法得到的数据是DataFrame对象
print(t.loc[["a","c"],["X","Z"]])
print(type(t.loc[["a","c"],["X","Z"]]))
# 通过索引获取连续的多行多列,该方法得到的数据是DataFrame对象
print(t.loc["a":"c","W":"Z"])
print(type(t.loc["a":"c","W":"Z"]))
执行结果:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
0
<class 'numpy.int32'>
W
a 0
<class 'pandas.core.frame.DataFrame'>
W 0
X 1
Name: a, dtype: int32
<class 'pandas.core.series.Series'>
X Z
a 1 3
c 9 11
<class 'pandas.core.frame.DataFrame'>
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
<class 'pandas.core.frame.DataFrame'>
3.5.2 df.iloc[]
import pandas as pd
import numpy as np
t = pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
print(t)
# 通过位置获取单行数据,该方法得到的数据是Series对象
print(t.iloc[0])
print(type(t.iloc[0]))
# 通过位置获取行列交点,该方法得到的数据是numpy.int32对象
print(t.iloc[0, 0])
print(type(t.iloc[0, 0]))
# 通过位置获取行列交点,该方法得到的数据是DataFrame对象
print(t.iloc[[0], [0]])
print(type(t.iloc[[0], [0]]))
# 通过位置获取单行多列(单列多行)数据,该方法得到的数据是Series对象
print(t.iloc[0, [0, 1, 2]])
print(type(t.iloc[0, [0, 1, 2]]))
# 通过位置获取间隔的多行多列数据,该方法得到的数据是DataFrame对象
print(t.iloc[[0, 2], [1, 3]])
print(type(t.iloc[[0, 2], [1, 3]]))
# 通过位置获取连续的多行多列数据,该方法得到的数据是DataFrame对象
print(t.iloc[0:2, 0:3])
print(type(t.iloc[0:2, 0:3]))
执行结果:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
W 0
X 1
Y 2
Z 3
Name: a, dtype: int32
<class 'pandas.core.series.Series'>
0
<class 'numpy.int32'>
W
a 0
<class 'pandas.core.frame.DataFrame'>
W 0
X 1
Y 2
Name: a, dtype: int32
<class 'pandas.core.series.Series'>
X Z
a 1 3
c 9 11
<class 'pandas.core.frame.DataFrame'>
W X Y
a 0 1 2
b 4 5 6
<class 'pandas.core.frame.DataFrame'>
3.5.3 赋值更改数据
import numpy as np
import pandas as pd
t = pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
print(t)
# 使用索引赋值
t.loc["a", "W"] = 999
print(t)
# 使用位置赋值
t.iloc[2, 3] = 666
print(t)
执行结果:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
W X Y Z
a 999 1 2 3
b 4 5 6 7
c 8 9 10 11
W X Y Z
a 999 1 2 3
b 4 5 6 7
c 8 9 10 666
3.6 pandas 布尔索引筛选
import pandas as pd
import numpy as np
t = pd.DataFrame(np.arange(12).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
print(t)
# 单个条件筛选
print(t[t["W"] > 6])
# 多个条件筛选,条件之间用括号括起来
print(t[(t["W"]>3)&(t["X"]<10)])
执行结果:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
W X Y Z
c 8 9 10 11
W X Y Z
b 4 5 6 7
c 8 9 10 11
3.7 pandas 字符串方法
import pandas as pd
import numpy as np
import string
temp_str = ["hello", "world", "Tom", "abcdefg",
"huweiyong", "wuyanzu", "jinchengwu", "jinxin",
"haiqing", "john", "huihui", "Li"]
t = pd.DataFrame(np.array(temp_str).reshape(3, 4), index=list("abc"), columns=list("WXYZ"))
print(t)
# 通过字符串长度筛选
print(t[(t["W"].str.len() > 5) & (t["Z"].str.len() < 3)])
执行结果:
W X Y Z
a hello world Tom abcdefg
b huweiyong wuyanzu jinchengwu jinxin
c haiqing john huihui Li
W X Y Z
c haiqing john huihui Li



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









