







MPEG音频编码
一、MPEG音频编码原理

MPEG的音频编码主要采用了心理声学模型
1.1 基本思想
- 通过子带分析滤波器组使信号具有高的时间分辨率,确保在短暂冲击信号情况下,编码的声音信号具有足够高的质量。
- 又可以使信号通过FFT运算具有高的频率分辨率,因为掩蔽阈值是从功率谱密度推出来的。
- 在低频子带中,为了保护音调和共振峰的结构,就要求用较小的量化阶、较多的量化级数,即分配较多的位数来表示样本值。而话音中的摩擦音和类似噪声的声音,通常出现在高频子带中,对它分配较少的位数
1.2 心理声学模型
MPEG-1标准定义了两个模型。
心理声学模型 1:
- 计算复杂度低
- 但对假设用户听不到的部分压缩太严重
心理声学模型 2:
- 提供了适合Layer 3编码的更多特征
- 实习实现的模型复杂度取决于所需要的压缩因子。
1.2.1 听觉阈值
听觉系统中存在一个听觉阈值电平,低于这个电平的声音信号就听不到
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ki7g5dQL-1592129735923)(https://i.loli.net/2020/06/14/gSO5lwYQkPJ3Rcs.png)]
- 听觉阈值的大小随声音频率的改变而改变
- 一个人是否听到声音取决于声音的频率,以及声音的幅度是否高于这种频率下的听觉阈值。
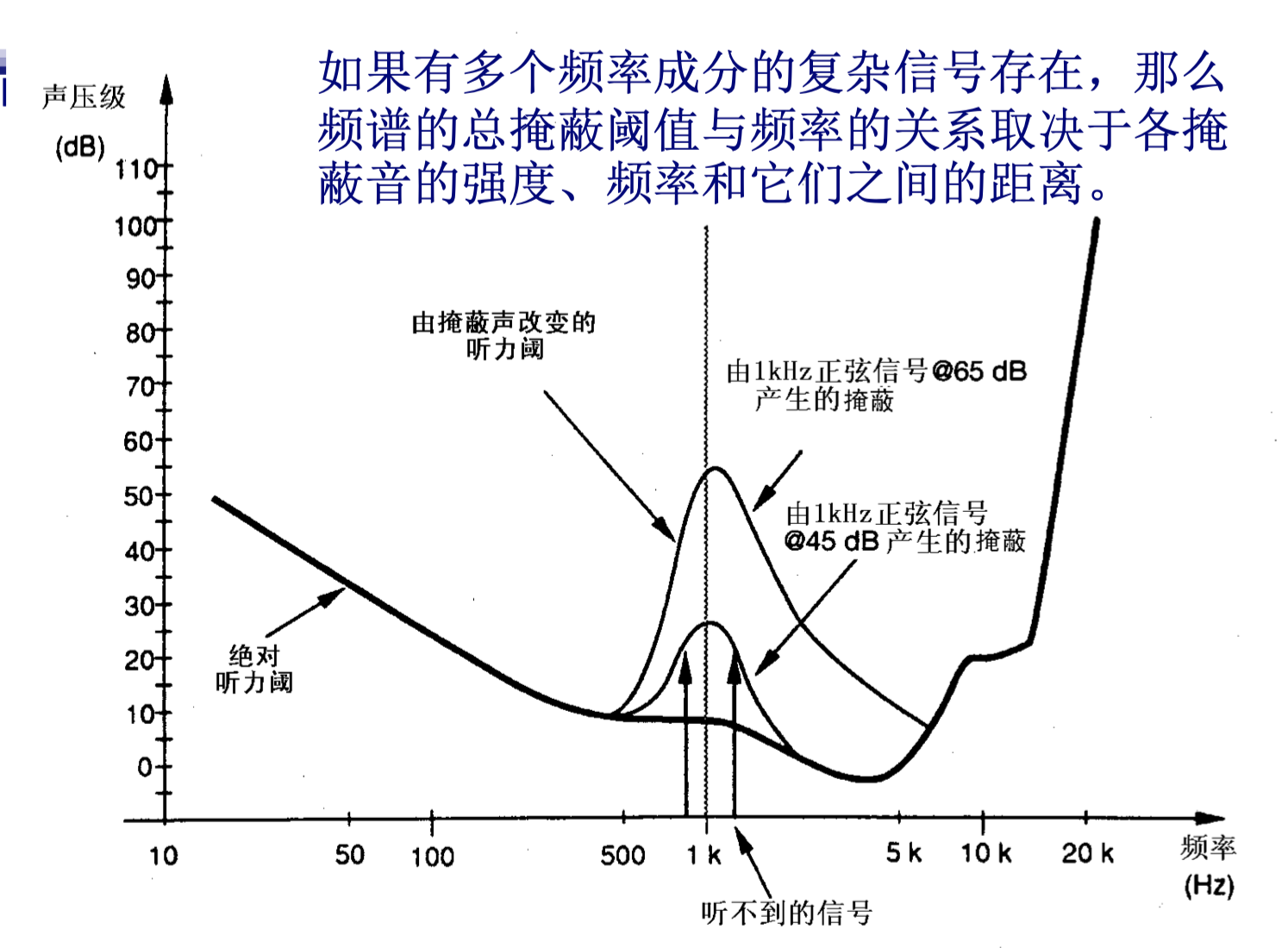
1.2.2 频域掩蔽
听觉阈值电平是自适应的,会随听到的不同频率声音而发生变化
1.3 临界频带
临界频带是指当某个纯音被以它为中心频率、且具有一定带宽的连续噪声所掩蔽时,如果该纯音刚好被听到时的功率等于这一频带内的噪声功率,这个带宽为临界频带宽度。
掩蔽效应在一定频率范围内不随带宽增大而改变,直至超过某个频率值。通常认为从20Hz到16kHz有25个临界频带,单位为Bark。 1 Bark = 一个临界频带的宽度。
1.4 人类听觉系统
人类听觉系统可以大致等效为在0 Hz—20 kHz范围内的25个重叠的带通滤波器组。
- 人耳在噪声中听某一纯音信号时,只启用中心频率与信号频率相同的那个听觉滤波器,且只有纯音信号和在通带范围内的部分信号可通过该滤波器。只有通过该滤波器的噪声才对掩蔽起作用;
- 聆听复音时启动多个听觉滤波器。听觉能够计算各滤波器输出端的信噪比。当信噪比达到或者超过听阈因子时,即可听到该频率成分。

1.5 掩蔽效果的加和
Lutfi对多个掩蔽音同时存在时的综合掩蔽效果进行了研究: 每个掩蔽音的掩蔽效果先独立变换然后再线性相加。
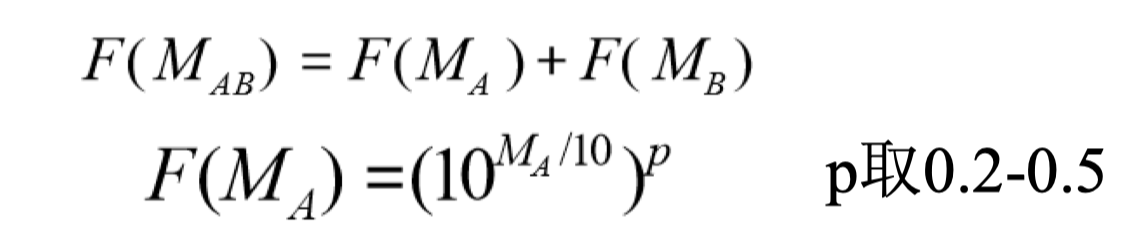
二、MPEG音频压缩编码
2.1 多相滤波器组
先分成32个相等的子带。
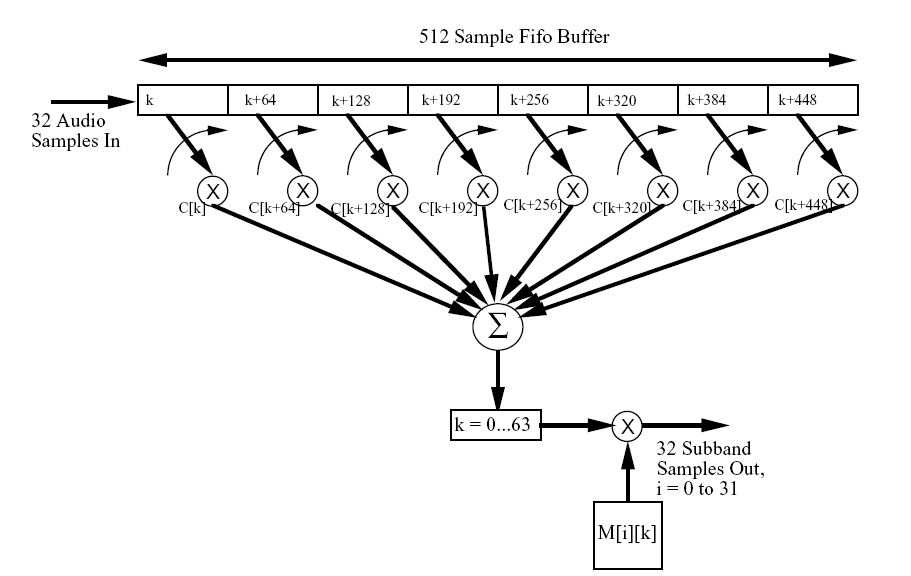
多相滤波器组的缺点:
- 等带宽的滤波器组与人类听觉系统的临界频带不对应【在低频区域,单个子带会覆盖多个临界频带。】。
- 滤波器组与其逆过程不是无失真的【但滤波器组引入的误差很小,且听不到】
- 子带间频率有混叠【滤波后的相邻子带有频率混叠现象,一个子带中的信号可以影响相邻子带的输出】
2.2 量化和编码
2.2.1 比例因子的取值和编码
对各个子带每12个样点进行一次比例因子计算【查表】。
第二层中一帧对应36个子带样值,原则上要传送3个比例因子。
为了降低比例因子的传输码率,每帧中每个子带的三个比例因子被划分成特定的几种模式,根据这些模式,1个、2个或3个比例因子和比例因子选择信息(每子带2比特)一起被传送。如 果一个比例因子和下一个只有很小的差别,就只传送大的一个【这种情况在稳态信号中经常出现】。
2.2.2 比特分配及编码
比特分配:对每个子带计算掩噪比MNR (dB) = 信噪比SNR - 信掩比SMR,然后找出其中具有最低MNR的子带,并给该子带多分配一些比特,然后重新计算MNR,继续分配,重复该步骤,直至没有比特可以分配。这样可以使得在满足比特率和掩蔽要求的前提下,使MNR最小;
2.2.3 数据帧的包装
- 帧头(Header):每帧开始的头32个比特,包含有同步和状
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 237
237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









