







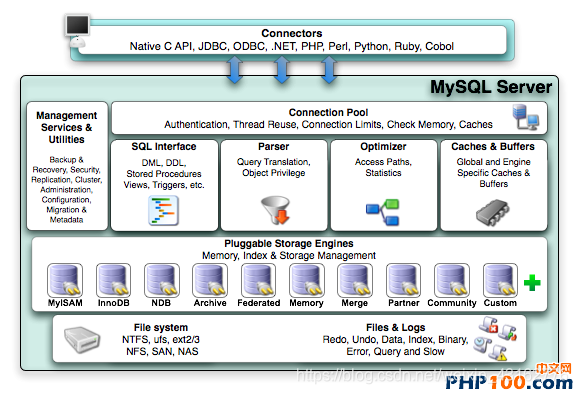
Mysql的整体架构
了解MySql必须牢牢记住其体系结构图,Mysql是由SQL接口,解析器,优化器,缓存,存储引擎组成的。
1、Connectors指的是不同语言中与SQL的交互 例如 java ,c , python , php等;
2、Management Serveices & Utilities: 系统管理和控制工具,备份、容灾恢复、集群等
3、Connection Pool: 连接池
管理缓冲用户连接,线程处理等需要缓存的需求。
4、SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface。
5、Parser: 解析器。
SQL命令传递到解析器的时候会被解析器验证和解析。解析器是由Lex和YACC实现的,是一个很长的脚本。
主要功能:
a . 将SQL语句分解成数据结构,并将这个结构传递到后续步骤,以后SQL语句的传递和处理就是基于这个结构的 。
b. 如果在分解构成中遇到错误,那么就说明这个sql语句是不合理的。
6、Optimizer: 查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。他使用的是“选取-投影-联接”策略进行查询。
用一个例子就可以理解: select uid,name from user where gender = 1;
这个select 查询先根据where 语句进行选取,而不是先将表全部查询出来以后再进行gender过滤。
这个select查询先根据uid和name进行属性投影,而不是将属性全部取出以后再进行过滤。
将这两个查询条件联接起来生成最终查询结果。
7、Cache和Buffer: 查询缓存
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等。
8、Engine :存储引擎
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)。
现在有很多种存储引擎,各个存储引擎的优势各不一样,最常用的MyISAM,InnoDB,BDB。
默认下MySql是使用MyISAM引擎,它查询速度快,有较好的索引优化和数据压缩技术。但是它不支持事务。
InnoDB支持事务,并且提供行级的锁定,应用也相当广泛。
Mysql也支持自己定制存储引擎,甚至一个库中不同的表使用不同的存储引擎,这些都是允许的。
存储引擎的概念
存储引擎是做什么的?如何实现的?不同的存储引擎有何不同?我们应该如何去选择?本文将围绕这几个核心点去介绍;
存储引擎说白了就是如何存储数据,如何为存储的数据建立索引和如何更新,查询数据等技术的实现方法! 在oracle , sql server 等数据可中只有一种存储引擎, mysql则提供了多种存储引擎,用户可以根据不同的需求动态选择!
也正如图所示, 动态配置存储引擎是mysql的核心!
查看Mysql中支持的引擎
show engines;
show engines\G //可以更美观显示
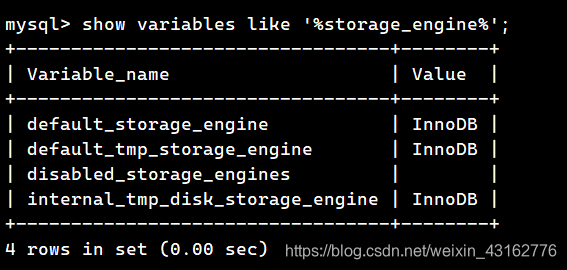
查看当前默认引擎
show variables like ‘%storage_engine%’;
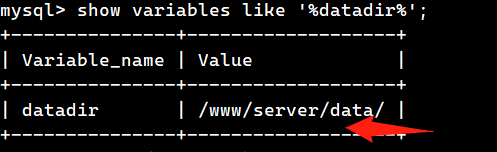
查看引擎物理位置
create table ocean_innodb(id int,name varchar(10)) engine=innodb;
show variables like ‘%datadir%’;

db.opt MySQL建库过程中自动生成,记录该库的默认字符集编码和字符集排序规则;

HeatWave 引擎
浅谈 InnoDB 存储引擎
特点:
支持事务,回滚,崩溃修复能力和多版本并发控制的事务安全.
支持外键约束
支持自动增长列
注意:

刚刚我通过innodb引擎创建了一个ocean_innodb表 ,mysql的文件层生成了 frm ibd两个文件,frm是MySQL表结构定义文件,通常frm文件是不会损坏的,但是如果出现特殊情况出现frm文件损坏也不要放弃希望,例如下面报错:
150821 16:31:27 [ERROR] /usr/local/mysql51/libexec/mysqld: Incorrect information in file: './t/test1.frm'
当修复MyISAM和InnoDB表时,MySQL服务会首先去调用frm文件,所以我们只能通过修复frm文件进行后面的数据恢复。
MySQL通过sql/table.cc的create_frm()函数创建frm文件,创建出来的frm文件是二进制文件,需要通过hexdump解析成16进制来分析。
ibd是MySQL数据文件、索引文件,无法直接读取。
InnoDB通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了SQL标准的4种隔离级别,默认为REPEATABLE级别。同时,使用一种被称为next-key locking的策略来避免幻读(phantom)现象的产生。除此之外,InnoDB储存引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能和高可用的功能。
此处参考文章
InnoDB存储引擎是目前mysql的默认引擎,数据页结构,页是innodb存储引擎管理数据的最小磁盘单位,而B-TREE节点就是实际存放表数据的节点,一个innodb页有七个部分组成:
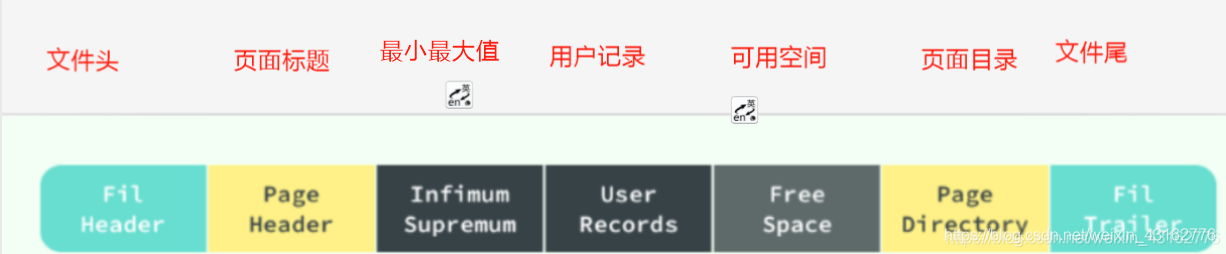
每一个页中包含了两对 header/trailer:内部的 Page Header/Page Directory 关心的是页的状态信息,而 Fil Header/Fil Trailer 关心的是记录页的头信息。
在页的头部和尾部之间就是用户记录和空闲空间了,每一个数据页中都包含 Infimum 和 Supremum 这两个虚拟的记录(可以理解为占位符),Infimum 记录是比该页中任何主键值都要小的值,Supremum 是该页中的最大值:

User Records 就是整个页面中真正用于存放行记录的部分,而 Free Space 就是空余空间了,它是一个链表的数据结构,为了保证插入和删除的效率,整个页面并不会按照主键顺序对所有记录进行排序,它会自动从左侧向右寻找空白节点进行插入,行记录在物理存储上并不是按照顺序的,它们之间的顺序是由 next_record 这一指针控制的。
B+ 树在查找对应的记录时,并不会直接从树中找出对应的行记录,它只能获取记录所在的页,将整个页加载到内存中,再通过 Page Directory 中存储的稀疏索引和 n_owned、next_record 属性取出对应的记录,不过因为这一操作是在内存中进行的,所以通常会忽略这部分查找的耗时。
索引是数据库中非常非常重要的概念,它是存储引擎能够快速定位记录的秘密武器,对于提升数据库的性能、减轻数据库服务器的负担有着非常重要的作用;索引优化是对查询性能优化的最有效手段,它能够轻松地将查询的性能提高几个数量级。需要注意的是查询记录时每次只能使用一个索引,因为和全表扫描和只是用一个索引的速度比起来,去分析两个索引二叉树更耗费时间。
那么索引是如何存储的呢?
InnoDB 存储引擎在绝大多数情况下使用 B+ 树建立索引,这是关系型数据库中查找最为常用和有效的索引,但是 B+ 树索引并不能找到一个给定键对应的具体值,它只能找到数据行对应的页,然后正如上一节所提到的,数据库把整个页读入到内存中,并在内存中查找具体的数据行。
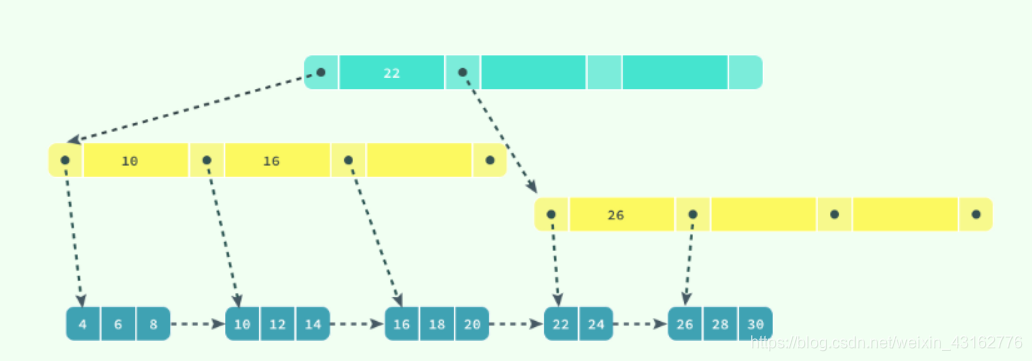
B+ 树是平衡树,它查找任意节点所耗费的时间都是完全相同的,比较的次数就是 B+ 树的高度;在这里,我们并不会深入分析或者动手实现一个 B+ 树,只是对它的特性进行简单的介绍。
数据库中的 B+ 树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),它们之间的最大区别就是,聚集索引中存放着一条行记录的全部信息,而辅助索引中只包含索引列和一个用于查找对应行记录的『书签』,在mysql中,可以把主键理解成聚集索引,如果没有创建,系统会自动创建一个隐含列为表的聚集索引。
MyISAM
MEMORY
如果选择存储引擎
存储引擎的基操
存储引擎的转换三种方式:
1,ddl语句
将表从一个存储引擎修改为另一种存储引擎最简单的方式是执行DDL语句,下面语句将mytable的引擎有InnoDB改为MyISAM:
alter table ocean_innodb engine=myisam;
执行效果如下图:

这种修改方法适用于任何存储引擎,但是需要注意的是:如果表的数据量很大,执行的时间会很长,Mysql会将原表的数据复制到一张新表中,在复制的期间可能会消耗完所有的系统I/O能力,同时会对原表上加读锁。同时更换存储引擎后的新表将丢失旧的存储引擎一切特性,例如InnoDB转换为MyISAM之后,所有的外键将丢失。
2,mysqldump
为了更好的控制转换过程,可以使用mysqldump工具将数据导出到文件,然后手动的修改文件CREATE TABLE 语句的存储引擎选项ENGINE,注意同时修改表名,因为同一个数据库中不能存在相同的表名,还要注意的是,mysqldump中会默认在CREATE TABLE 前加上DROP TABLE 语句,不注意这一点可能会导致数据丢失。
3.CREATE 和 SELECT
这种方式相对于前面两种高效和安全的特点。不需要导出整个表的数据,而是创建一张新的表,然后通过INSERT …SELECT 语法来导入数据。
如果数据量不大的话,上面操作处理结果很令人满意。如果数据量很大,可以分批操作,针对每一段数据执行事务提交,避免大事务带来的问题,例如可以根据时间筛选或者根据id大小筛选分段提交。
START TRANSACTION;
INSERT INTO innodb_table SELECT * FROM mytable where id between x AND y (或者create_time之类);
COMMIT;
实践记录


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









