







操作系统IO模型
一、操作系统的IO交互模型
现代的操作系统对于存储空间都有一套访问限制控制,所以将存储空间分成了用户空间和内核空间。用户空间负责给应用程序使用,应用程序可以访问用户空间内的数据,但是不可以访问内核空间中的数据;而内核程序可以访问计算机的所有存储空间,包括用户空间、内核空间以及硬件设备上的数据。所以当应用程序需要访问硬件设备上的数据或者是内核空间的数据时,就必须要通过内核空间的程序来实现。所以内核空间对外也提供了很多的函数,提供给了应用程序使用,让应用程序可以通过内核程序来访问想要的数据。
整体的IO交互模型如下图示:

下面就以应用程序需要从网卡中读取数据为例,整体IO交互流程主要分成如下几个步骤:
1、应用程序调用内核提供的函数发起请求数据(请求内核函数)
2、内核访问网卡存储空间获取数据(内核获取数据)
3、内核将获取的到数据复制到用户空间(内核复制数据)
4、应用程序从用户空间中获取需要的数据(应用程序获取数据)
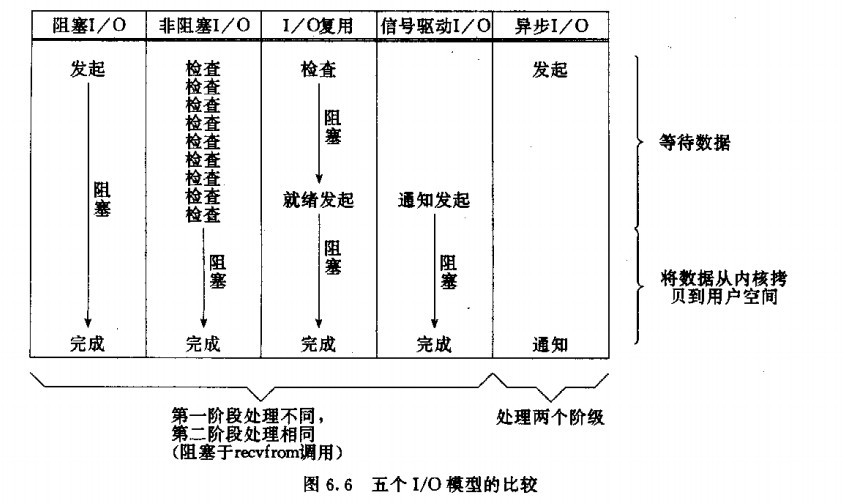
二、操作系统的IO模型
介绍操作系统的IO模型之前,可以先了解下和IO模型的分类,主要有同步IO、异步IO、阻塞IO、非阻塞IO
2.1、IO的类型
2.1.1、同步IO
应用程序调用内核函数到最终应用程序从用户空间中获取数据的整个流程是需要用户线程一次性完成的那么就是同步IO,就是上面提到的四个步骤都需要应用程序线程自己完成,操作系统不会干预。
2.1.2、异步IO
应用程序调用内核函数请求获取数据和最终从用户空间中拿到数据不是一次性完成的,而是先请求数据,等数据全部准备好了之后再获取的就是异步IO。异步io的读写是由操作系统完成。
2.1.3、阻塞IO
应用程序调用内核函数请求数据,如果此时还没有数据,那么应用程序就一直等待着,直到成功拿到数据为止,此时应用程序线程是一直处于等待状态的,那么就是阻塞IO。指的是写这个阶段是非阻塞的。
2.1.4、非阻塞IO
应用程序调用内核函数请求数据,如果此时还没有数据,那么应用程序就不等待先去处理其他事情,过一会再重新尝试请求,直到成功拿到数据为止,此时应用程序不会一直处于等待状态,那么就是非阻塞IO。指的是写这个阶段是非阻塞的。
2.2、操作系统IO模型
操作系统的IO模型也主要分成同步IO和异步IO两大类,而同步IO又分成了阻塞和非阻塞等类,异步IO不会出现阻塞IO情况,所以异步IO肯定是非阻塞的IO,操作系统IO模型主要分成如下几种类型
tips:操作系统给应用程序提供了recv函数,该函数用于从socket套接字中接收数据,默认情况下会等到网络数据接收完成并复制到用户空间之后才返回结果或者失败之后返回结果,可以通过flags参数设置如果没有数据的话立即返回结果
2.2.1、同步阻塞IO
应用程序调用操作系统的recv函数,recv函数默认会等待数据接收完成并复制到用户空间之后返回结果,而如果数据没有准备好的话,那么应用程序就一直处于等待状态,直到有数据返回,此时应用程序的线程处于阻塞状态,无法执行其他操作
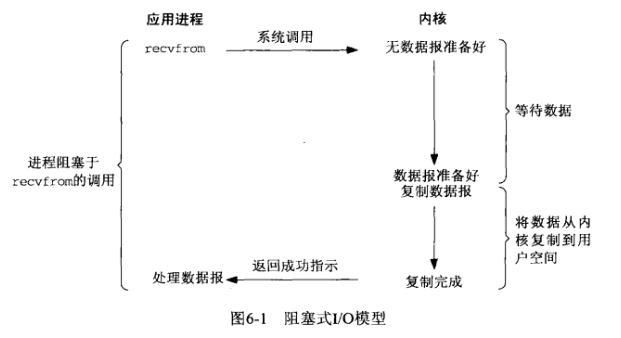
2.2.2、同步非阻塞IO
应用程序调用操作系统的recv函数,recv函数设置flags值为立即返回,那么如果内核发现没有数据时就立即返回,应用程序得到结果之后不再等待,而是先处理其他业务,然后轮询不断尝试获取数据,直到数据成功返回,此时应用程序不处于阻塞状态,可以先处理其他操作
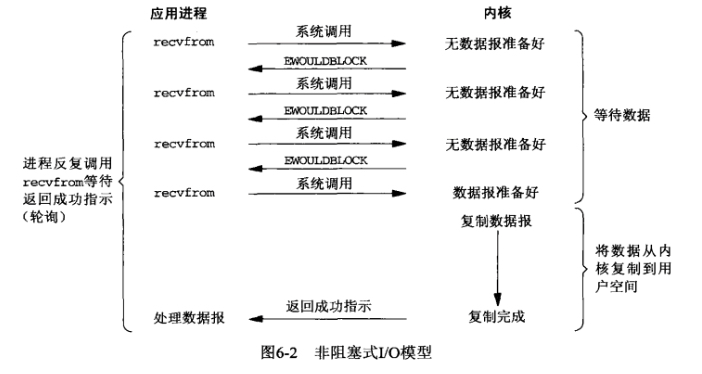
2.2.3、同步非阻塞多路复用IO
应用程序先调用操作系统的select函数或者poll函数或者epoll函数,这几个函数的作用是监听网络套接字上的数据状态,如果有数据可读,那么就通知应用程序,此时应用程序再调用recv函数来读取数据,此时肯定是可以读取到数据的。可以发现多路复用IO的特点是不需要尝试获取数据,而是先开启另外一个线程来监控数据的状态,等到有数据的时候再同步获取数据,而在没数据的时候也是不需要等待的。多路复用IO调用select函数之后也会阻塞进程,但是真正的IO操作线程没有被阻塞,所以实质上是同步非阻塞IO。
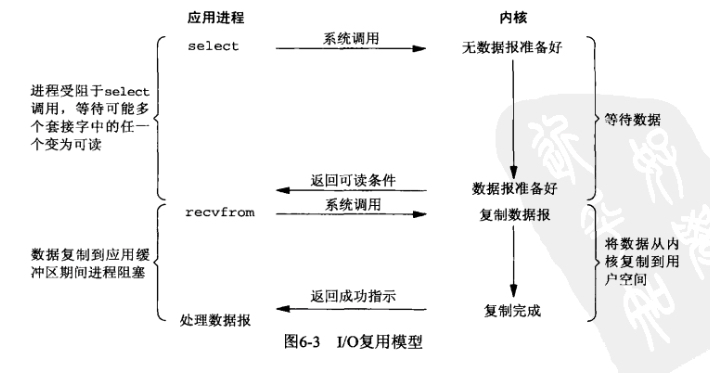
2.2.4、同步信号驱动IO
通过调用sigaction函数注册信号函数,等内核数据准备好了之后会执行信号函数通知应用程序,应用程序此时再调用recv函数同步的获取数据。信号驱动IO和异步IO有点类似,都是异步通知,不同的是信号驱动IO的真正读取数据的操作还是同步操作的。
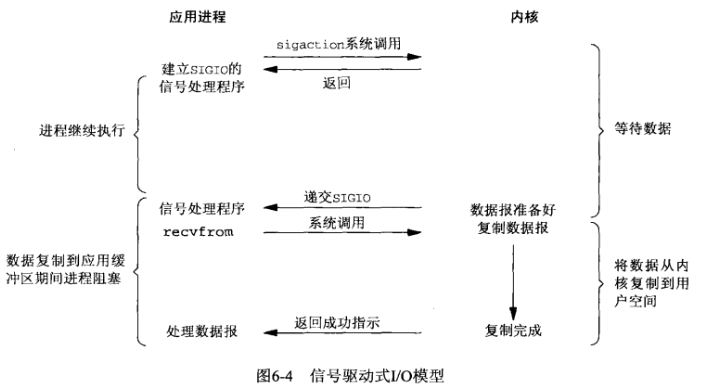
2.2.5、异步非阻塞IO
通过调用aio_read函数,那么内核会先将数据读取好,并且复制到用户空间之后,再执行回调函数通知应用程序,此时应用程序就可以直接从用户空间中读取数据,而不需要再从内核中读取数据了。
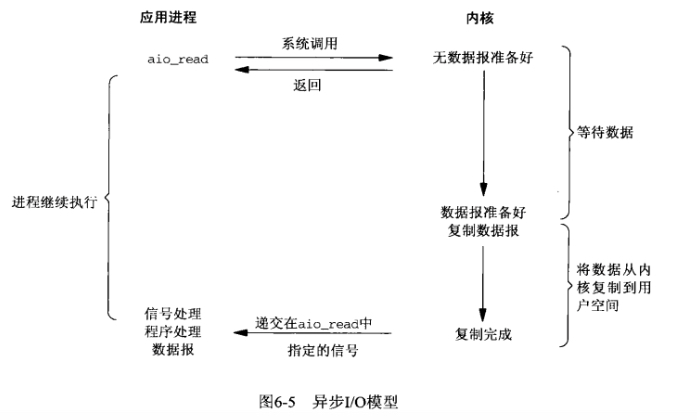
总结:
IO操作主要可以分成两个阶段:1、数据准备阶段;2、数据从内核空间复制到用户空间阶段
而阻塞IO、非阻塞IO、多路复用IO和信号驱动IO只是在第一个阶段不同,而第二个阶段是相同的,都是需要阻塞当前线程等待数据复制完成,虽然阻塞的时间足够短,所以用户线程需要执行第二阶段的都是属于同步IO;
而异步IO模型的第一阶段和第二阶段都是内核主动完成,在两个阶段都不会阻塞当前线程去处理其他事情。
java中的IO模型
BIO
java中的BIO是对底层操作系统阻塞IO模型的封装,也是java最早提供的一种io方式,具体实现放在io包下。
NIO
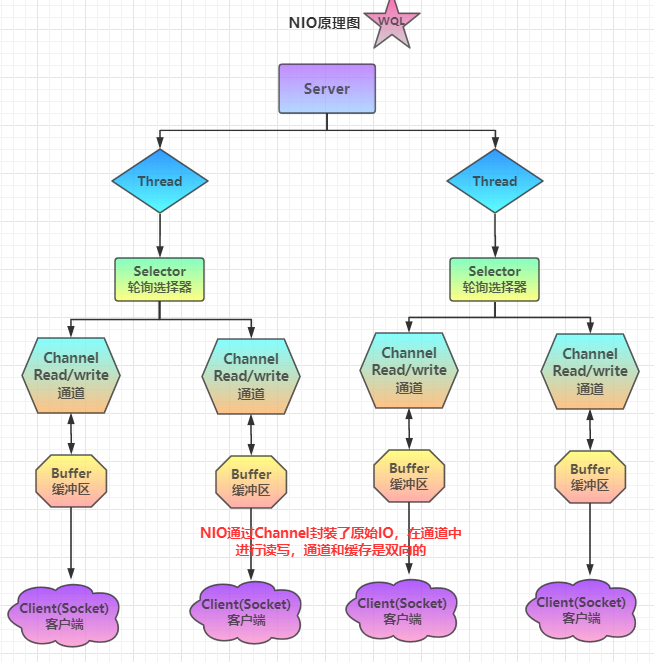
java中的NIO是基于channel(通道)、buffer(缓冲区)、selector(选择器)实现的一种非阻塞的IO多路复用模式。Selector底层是对操作系统IO多路复用select函数的的封装。
- Channel由java.nio.channels 包定义的。Channel 表示IO 源与目标打开的连接。Channel 类似于传统的“流”。只不过Channel 本身不能直接访问数据,Channel 只能与Buffer 进行交互
那么channel和传统的读取数据方式有什么不同呢?
(1)通道是双向的,既可以执行读操作,也可以执行写操作,而stream只能进行单向操作,例如:InputStream只能执行读操作。
(2)通道的读写是基于buffer缓冲区的,即通道中的数据总是要先读到一个缓冲区,或者总是要从一个缓冲区中读入。而传统io是直接在流上读写数据的。
(3)正是因为缓冲区的使用,通道可以实现异步读写。例如:从通道进行数据读取时,首先创建一个缓冲区,然后请求通道读取数据到buffer,等到数据读取到buffer之后,线程再从buffer中获取数据。对通道执行写入操作时,首先创建一个缓冲区,线程向buffer中填充数据,然后请求通道写数据。
-
Buffer用于和NIO通道进行交互。如你所知,数据是从通道读入缓冲区,从缓冲区写入到通道中的。
缓冲区本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问该块内存。
与传统I/O流相比,NIO的HeapByteBuffer有什么优势?
传统流I/O是基于字节的,所有I/O都被视为单个字节的移动;而NIO是基于块的,大家可能猜到了,NIO的性能肯定优于流I/O。没错!其性能的提高 要得益于其使用的结构更接近操作系统执行I/O的方式:通道和缓冲器。
DirectBuffer比HeapBuffer少了一次内存拷贝
JVM将使用malloc()在堆空间之外分配内存空间。 因为它不是由JVM管理的,所以你的内存空间是页面对齐的,不受GC影响,这使得它成为处理本地代码的完美选择。 然而,你要C程序员一样,自己管理这个内存,必须自己分配和释放内存来防止内存泄漏。
-
selector 的作用就是配合一个线程来管理多个 channel(fileChannel因为是阻塞式的,所以无法使用selector),获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,当一个channel中没有执行任务时,可以去执行其他channel中的任务。
BIO与NIO的区别
| BIO | NIO |
|---|---|
| 面向流(Stream Oriented) | 面向缓冲区(Buffer Oriented) |
| 阻塞IO(Blocking IO) | 非阻塞IO(NonBlocking IO) |
| 选择器(Selectors) |
AIO
AIO是jdk1.7新增的一种异步IO方式,具体是通过nio包中的几个异步通道实现的,是对底层异步非阻塞IO的封装。
AIO 用来解决数据复制阶段的阻塞问题
- 同步意味着,在进行读写操作时,线程需要等待结果,还是相当于闲置
- 异步意味着,在进行读写操作时,线程不必等待结果,而是将来由操作系统来通过回调方式由另外的线程来获得结果
异步模型需要底层操作系统(Kernel)提供支持
- Windows 系统通过 IOCP 实现了真正的异步 IO
- Linux 系统异步 IO 在 2.6 版本引入,但其底层实现还是用多路复用模拟了异步 IO,性能没有优势
零拷贝
零拷贝指的是数据无需拷贝到 JVM 内存中,同时具有以下三个优点
- 更少的用户态与内核态的切换
- 不利用 cpu 计算,减少 cpu 缓存伪共享
- 零拷贝适合小文件传输
传统 IO 问题
传统的 IO 将一个文件通过 socket 写出
File f = new File("helloword/data.txt");
RandomAccessFile file = new RandomAccessFile(file, "r");
byte[] buf = new byte[(int)f.length()];
file.read(buf);
Socket socket = ...;
socket.getOutputStream().write(buf);Copy
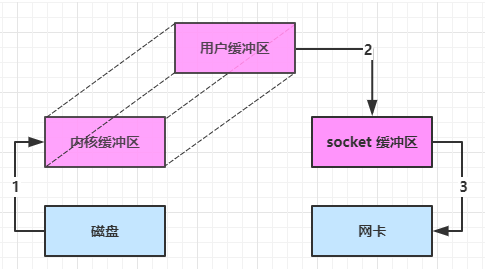
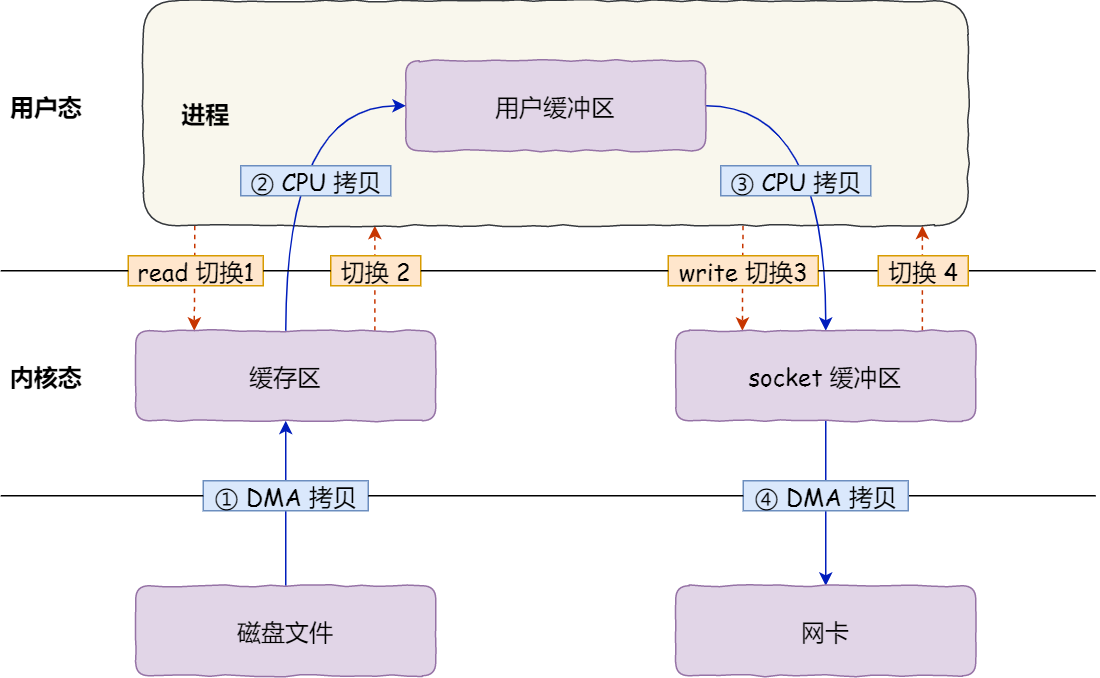
内部工作流如下
-
Java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 Java 程序的用户态切换至内核态,去调用操作系统(Kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,其间也不会使用 CPU
DMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO -
从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间 CPU 会参与拷贝,无法利用 DMA
-
调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,CPU 会参与拷贝
-
接下来要向网卡写数据,这项能力 Java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 CPU
可以看到中间环节较多,java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级
- 数据拷贝了共 4 次
NIO 优化(DirectByteBuf 对应 mmap + write)
通过 DirectByteBuf 底层对应的mmap + write
- mmap + write
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);
write(sockfd, buf, len);
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
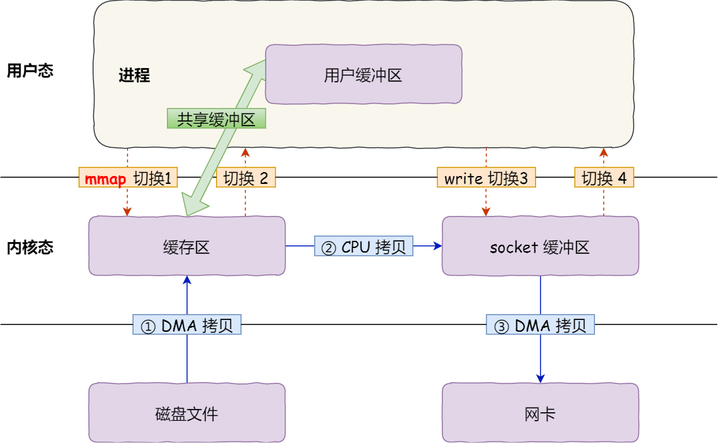
具体过程如下:
- 应用进程调用了
mmap()后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核「共享」这个缓冲区; - 应用进程再调用
write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据; - 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
- DirectByteBuffer
-
ByteBuffer.allocate(10)
- 底层对应 HeapByteBuffer,使用的还是 Java 内存
-
ByteBuffer.allocateDirect(10)
- 底层对应DirectByteBuffer,使用的是操作系统内存
- 这块内存不受 JVM 垃圾回收的影响,因此内存地址固定,有助于 IO 读写
- Java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步
- DirectByteBuffer 对象被垃圾回收,将虚引用加入引用队列
- 当引用的对象ByteBuffer被垃圾回收以后,虚引用对象Cleaner就会被放入引用队列中,然后调用Cleaner的clean方法来释放直接内存
- DirectByteBuffer 的释放底层调用的是 Unsafe 的 freeMemory 方法
- 通过专门线程访问引用队列,根据虚引用释放堆外内存
- DirectByteBuffer 对象被垃圾回收,将虚引用加入引用队列
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少
进一步优化1(transferTo、transferFrom 对应 sendfile)
- sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:
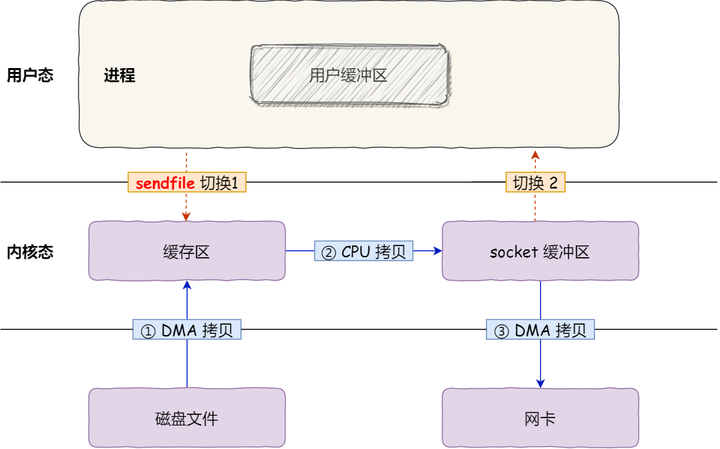
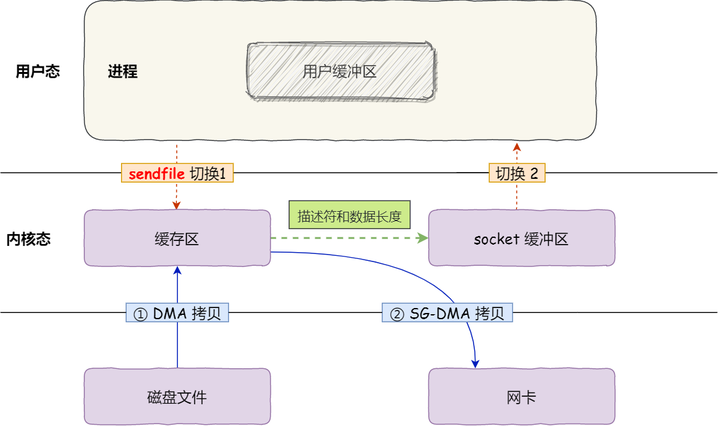
- transferTo
transferTo 无需将数据拷贝到用户缓冲区中(JVM内存中)
底层采用了 linux 2.1 后提供的 sendFile 方法,Java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据
- Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 CPU
- 数据从内核缓冲区传输到 socket 缓冲区,CPU 会参与拷贝
- 最后使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 CPU
这种方法下
- 只发生了1次用户态与内核态的切换
- 数据拷贝了 3 次
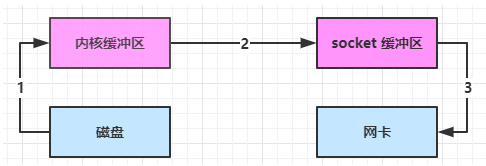
进一步优化2(transferTo、transferFrom 对应 优化后sendfile)
- sendfile 优化
linux 2.4 对上述方法再次进行了优化
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
- transferTo 优化
linux 2.4 对上述方法再次进行了优化
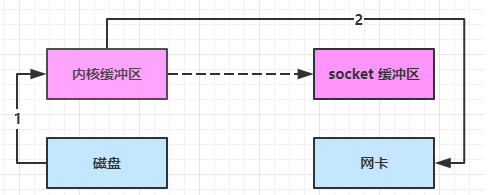
- Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 CPU
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗
- 使用 DMA 将 内核缓冲区的数据写入网卡,不会使用 CPU
整个过程仅只发生了1次用户态与内核态的切换,数据拷贝了 2 次
网络编程 NIO
阻塞模式:一个线程处理多个channel,如果有一个channel的数据没有准备好,就会阻塞下一个channel,即一个网络IO完成系统调用后,另外一个IO才能运行。
public class Server {
public static void main(String[] args) {
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
// 为服务器通道绑定端口
server.bind(new InetSocketAddress(8080));
// 用户存放连接的集合
ArrayList<SocketChannel> channels = new ArrayList<>();
// 循环接收连接
while (true) {
System.out.println("before connecting...");
// 没有连接时,会阻塞线程
SocketChannel socketChannel = server.accept();
System.out.println("after connecting...");
channels.add(socketChannel);
// 循环遍历集合中的连接
for(SocketChannel channel : channels) {
System.out.println("before reading");
// 处理通道中的数据
// 当通道中没有数据可读时,会阻塞线程
channel.read(buffer);
buffer.flip();
ByteBufferUtil.debugRead(buffer);
buffer.clear();
System.out.println("after reading");
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
非阻塞模式:如果一个channel内核缓冲区数据没有准备好,则马上返回用户态,执行下一个channel。如果准备好了就执行当前IO。线程是一直都在执行的。
public class Server {
public static void main(String[] args) {
// 创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
// 为服务器通道绑定端口
server.bind(new InetSocketAddress(8080));
// 用户存放连接的集合
ArrayList<SocketChannel> channels = new ArrayList<>();
// 循环接收连接
while (true) {
// 设置为非阻塞模式,没有连接时返回null,不会阻塞线程
server.configureBlocking(false);
SocketChannel socketChannel = server.accept();
// 通道不为空时才将连接放入到集合中
if (socketChannel != null) {
System.out.println("after connecting...");
channels.add(socketChannel);
}
// 循环遍历集合中的连接
for(SocketChannel channel : channels) {
// 处理通道中的数据
// 设置为非阻塞模式,若通道中没有数据,会返回0,不会阻塞线程
channel.configureBlocking(false);
int read = channel.read(buffer);
if(read > 0) {
buffer.flip();
ByteBufferUtil.debugRead(buffer);
buffer.clear();
System.out.println("after reading");
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
IO多路复用:
另外开启另外一个线程来监控内核缓冲区中各个channel数据的状态,如果有channel在内核缓冲区中数据准备好了,则放入到一个集合中执行,如果没有数据准备好,就把当前线程阻塞。
public class SelectServer {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(16);
// 获得服务器通道
try(ServerSocketChannel server = ServerSocketChannel.open()) {
server.bind(new InetSocketAddress(8080));
// 创建选择器
Selector selector = Selector.open();
// 通道必须设置为非阻塞模式
server.configureBlocking(false);
// 将通道注册到选择器中,并设置感兴趣的事件
server.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 若没有事件就绪,线程会被阻塞,反之不会被阻塞。从而避免了CPU空转
// 返回值为就绪的事件个数
int ready = selector.select();
System.out.println("selector ready counts : " + ready);
// 获取所有事件
Set<SelectionKey> selectionKeys = selector.selectedKeys();
// 使用迭代器遍历事件
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 判断key的类型
if(key.isAcceptable()) {
// 获得key对应的channel
ServerSocketChannel channel = (ServerSocketChannel) key.channel();
System.out.println("before accepting...");
// 获取连接并处理,而且是必须处理,否则需要取消
SocketChannel socketChannel = channel.accept();
System.out.println("after accepting...");
// 处理完毕后移除
iterator.remove();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









