






hive面试题
-
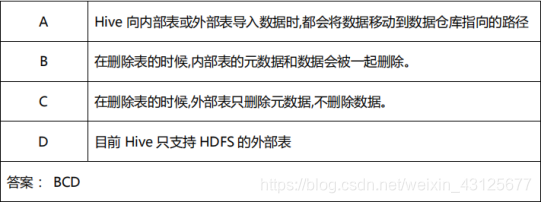
多选题:关于 Hive 内部表和外部表的说法,正确的是()
-
hive介绍
hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。
其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专 门的 MapReduce 程序,只要会sql就行。 -
简述 HIve, sparkSQL 的用途和区别
(1)Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为 一 张数据库表,并提供 SQL语句查询功能。本质是将 SQL 转换为 MapReduce 程序
(2)Sparksql 是 spark 生态中的一员 不但兼容 hive,还可以从 RDD、parquet 文件、JSON 文件中获取数据 , 底层转为spark程序 -
hive内部表和外部表的区别
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。, 在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,方便共享源数据
-
hive 跟 hbase 的区别是?
hive和Hbase是两种基于Hadoop的不同技术–Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的列存储数据库数据库。当然,这两种工具是可以同时使用的。数据也可以从Hive写到Hbase,设置再从Hbase写回Hive
-
hive有哪些方式保存元数据,各有哪些优点?
(1)默认 : 存储于 derby 数据库,此方法只能开启一个 hive 客户端,不推荐使用
(2)存储于 mySQL 数据库中,可以多客户端连接,推荐使用。 -
请说明 hive 中 Order By,Sort By,Distrbute By,Cluster By 各代表什么意思 ?
order by:会对输入做全局排序,多个 reducer 无法保证全局有序 ,只有一个 reducer时,当输入数据较大时,需要较长的计算时间。
sort by:不是全局排序,其在数据进入 reducer 前完成排序。
distribute by:按照指定的字段对数据进行划分到不同的输出 reduce 中。
cluster by:除了具有 distribute by 的功能外还兼具 sort by 的功能。 -
Hive中追加导入数据的4种方式是什么?请写出简要语法
从本地导入: load data local inpath ‘/home/1.txt’ (overwrite)into table student;
从Hdfs导入: load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
查询导入: create table student1 as select * from student;(也可以具体查询某项数据) -
分区和分桶的区别
分区
从形式上可以理解为文件夹 , 将一个表数据划分为多个文件夹 , 可以避免数据表的内容过大,在查询时进行全表扫描耗费的资源非常多。我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,查询时指定分区字段的值即可。
分桶 --使用场景 , 抽样
分桶是相对分区进行更细粒度的划分。从形式上可以理解为文件。
分桶将整个数据内容按照某列属性值得hash值进行区分,如要按照name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。
如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件
语法 : select * from bucket_table tablesample(bucket 1 out of 4 on columns); -
动态分区和静态分区
静态分区
hive 是如何实现分区的?
建表语句:
create table tablename (id) partitioned by (dt string)
增加分区:
alter table tablenname add partition (dt = ‘2016-03-06’)
删除分区:
alter table tablename drop partition (dt = ‘2016-03-06’)
动态分区
from psn21
insert overwrite table psn22 partition(age, sex)
select id, name, age, sex, likes, address distribute by age, sex;
hive.exec.dynamic.partition=true :是否允许动态分区
hive.exec.dynamic.partition.mode=strict :分区模式设置
strict:最少需要有一个是静态分区
nostrict:可以全部是动态分区
hive.exec.max.dynamic.partitions=1000 :允许动态分区的最大数量
hive.exec.max.dynamic.partitions.pernode =100 :单个节点上的 mapper/reducer 允许创建的最大分区
设置非严格模式动态分区
set hive.exec.dynamic.partition.mode=nostrict; -
hive 操作中动态分区与静态分区的区别
静态分区与动态分区的主要区别在于静态分区是手动指定,分区的值是确定的。
而动态分区是通过数据来进行判断,分区的值是非确定的,由输入数据来确定。 -
UDF UDAF UDTF
UDF 一进一出 —继承UDF , 实现eveluete方法
UDAF 多进一出 —sum avg ,继承UDAF , 实现很多歌方法
UDTF 一进多出 -
数据倾斜问题
group by 和 join 容易数据倾斜,数据倾斜的原因: shuffle 阶段 造成reduce 分配不均,数据倾斜直接结果:效率低,闲置资源多,任务错误指数上升
(1)开启Map端聚合功能 , 能够使map传送给reduce的数据量大大减少 ,减少网路io
(2)通过开启group by数据倾斜优化开关skewindata=true。注:开启优化开关后group by会启动两个MR , 第一个MR Job中的Map的输出结果集合会随机分布到第一个MR Job的Reduce中,每个Reduce做局部聚合操作作为输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而实现负载均衡的目的; 第二个MR Job再根据预处理的数据结果按照Group By Key分布到相应的Reduce中,最后完成最终的聚合操作。 -
Hive的索引
创建格式:
create index zxz_5_index
on table zxz_5 (nid)
as ‘bitmap’
with deferred rebuild
建立索引之后快的原因 : 建立索引会生成一张索引表 , 里面字段包括 : 索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量。在查询涉及到索引字段时,首先到索引表查找索引列值对应的HDFS文件路径及偏移量,这样就避免了全表扫描
缺点 : 无法自动的rebuid , 有数据新增或者删除要手动rebuid
Hive 3.0支持的物化视图可以达到类似的效果 , 而且ORCFile RCFile parquet 这些按列存储的格式能进过滤列 , 所以在hive 3.0时候 , hive会去掉索引
注意: as 后面跟的是索引处理器,bitmap处理器普遍应用于排重后值较小的列;
with deferred rebuild 他是必须要填加的
分区表建立的索引是分区索引
重建索引
普通重建索引: alter index zxz_5_index on zxz_5 rebuild
分区重建索引:alter index zxz_5_index on zxz_5 partition (year=“2018”) rebuild
删除索引
drop index zxz_5_index on table zxz_5; 注意:如果我们把原表删除索引表会自动删除 -
视图 (简化操作)
创建视图: create view v_psn as select * from psn;
修改视图: ALTER view v_psn as select * from psn;
删除视图:drop view v_psn;
查看视图:show tables;
普通视图 , 只是建立一份元数据, 一张逻辑表。查询视图时转为SQL子查询执行。这样并不能提高查询效率 , 普通视图只能查询
物化视图 , 是一张物理表 , 会实际占用磁盘空间 , 实际存储着数据
Hive在3.0开始支持物化视图 ! 自动重写的物化视图 ! -
insert into 和 insert overwrite 区别 ?
都是向hive表中插入数据,但是insert into直接追加到表中数据的尾部,而insert overwrite会重写数据,既先进行删除,再写入。如果存在分区的情况,insert overwrite会只重写当前分区数据。
-
hive调优
hive最终都会转化为mapreduce来运行,要想hive调优,实际上就是mapreduce调优,可以有一下几方面。
模式方面
本地模式 : 数据量少的时候 , 可以开启本地模式运行
并行模式 : hive默认是一个job执行完之后再执行下个job ,开启并行模式可以job可以并行
严格模式 : 避免一些人为的误操作 , 导致运行效率慢 限制查询 : 分区表必须要加分区条件查询, order by 要加limit条件,限制笛卡尔积查询
查询方面优化
(1)join 优化,尽量将小表放在 join 的左边,左边的表会加载到内存中 , 避免内存溢出 , 还可以开启MapJoin , 自动将小表加载到内存
(2)分区优化 ,对数据进行分区, 查询时对于表进行分区字段的条件过滤 , 避免全表扫描,减少查询的数据量
(3)查询数据只查需要用到的列 , 不用的列不查询, 不要用*查询所有列
(4)避免使用order by全局排序 , order by只用一个Reducer产生结果,对于大数据集,这种做法效率很低。如果不需要全局有序,则可以使用sort by 为每个reducer生成一个排好序的文件。如果需要控制一个特定数据行流向哪个reducer,可以使用distribute by子句
(5)将重复的子查询结果保存到中间表
运行计算方面优化
避免数据倾斜 :
(3)开启Map端聚合功能 , 能够使map传送给reduce的数据量大大减少 ,减少网路io
(4)通过开启group by数据倾斜优化skewindata=true。注:开启优化开关后group by会启动两个MR , 第一个MR Job中的Map的输出结果集合会随机分布到第一个MR Job的Reduce中,每个Reduce做局部聚合操作作为输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而实现负载均衡的目的; 第二个MR Job再根据预处理的数据结果按照Group By Key分布到相应的Reduce中,最后完成最终的聚合操作。
(5)开启合并小文件,启动较多的map或reduce能够提高并发度,加快任务运行速度;但同时生成的文件数目也会越来越多,给HDFS的NameNode造成内存上压力,进而影响HDFS读写效率。NameNode管理用户的读写请求 .
(6)索引列的值、该值对应的HDFS文件路径、该值在文件中的偏移量。在查询涉及到索引字段时,首先到索引表查找索引列值对应的HDFS文件路径及偏移量,这样就避免了全表扫描
(7)对数据进行压缩,减少io数据量 gzip
(8)文件格式的优化 , hive主要有3种格式
Textfile 默认格式
sequence[西捆死]file , 使用方便 , 可压缩 [BLOCK]
Rcfile 行列存储相结合的存储方式
ORCFile
Parquet
(9)设置合适的map数量和reduce数量
当输入文件很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,来使得每个map处理的数据量减少,从而提高任务的执行效率。
当输入文件很小,任务逻辑简单,map任务启动和初始化的时间远远大于逻辑处理的时间 , 这时可以考虑减少map
对应调整切片大小即可! 参数 :minsize maxsize blocksize 默认切片=block大小
未完…待续!!! 各位同仁如有补充可在下方留言

















 8062
8062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









