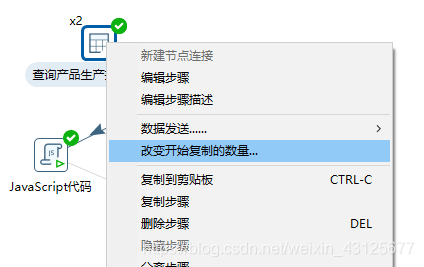
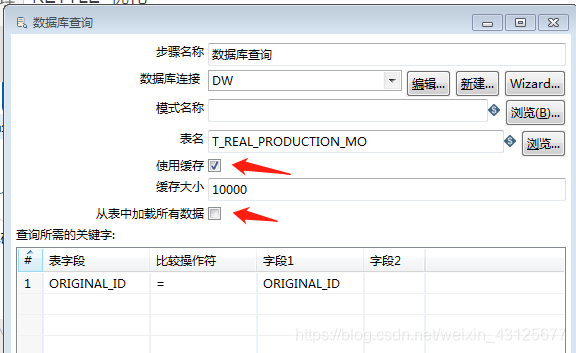
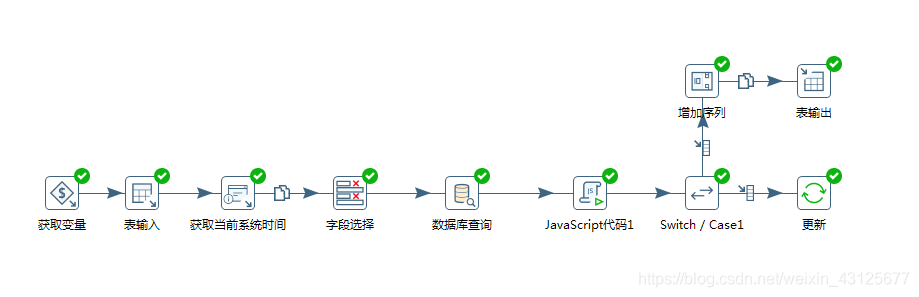
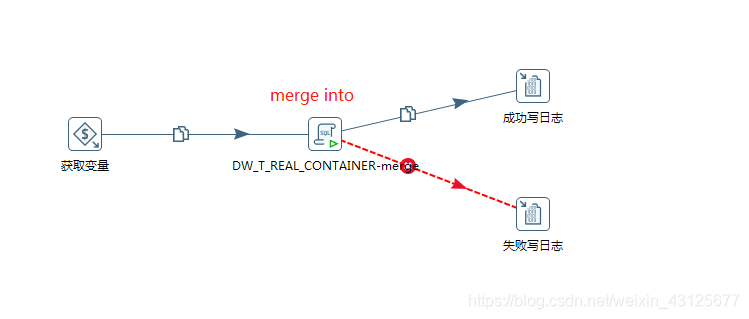
KETTLE -优化 1. 最直接的办法: 加内存 spoon.bat2. 通过改变开始复制的数量3. 查询控件使用缓存,内存够大还可以直接加载全表数据4. 设置合理的流程方案(避免查询组件)5. 设置表输出时批量提交的条数 commit 1. 最直接的办法: 加内存 spoon.bat 2. 通过改变开始复制的数量 (针对查询控件或者耗时的控件,这种方式比较简单,需要多长尝试合理的复制数量) 3. 查询控件使用缓存,内存够大还可以直接加载全表数据 kettle是一个流式的处理过程,步骤与步骤之间的数据传递是通过缓存来完成的,调整缓存的大小可以对kettle的运行产生明显的影响。 4. 设置合理的流程方案(避免查询组件) 最好避免查询主键 , 可以使用merge into 实现更新 , 或者先通过sql脚本执行批量的删除,再进行插入 改 5. 设置表输出时批量提交的条数 commit




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






