







Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
官方文档地址:
https://flink.apache.org/zh/flink-architecture.html
数据可以被作为 无界 或者 有界 流来处理。
**
- 无界流
** 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
- 有界流
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
window10 运行 Flink 程序
flink run -c com.szc.WordCountStreaming -p 2 D:\develop\ideaWorkspace\flinkDemo\target\flinkDemo-1.0-jar-with-dependencies.jar --host 192.168.57.133
提交jar 包的的时候,注意替换下如下代码:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// val env = StreamExecutionEnvironment.createLocalEnvironment()
不然在linux 上运行会报如下错误:
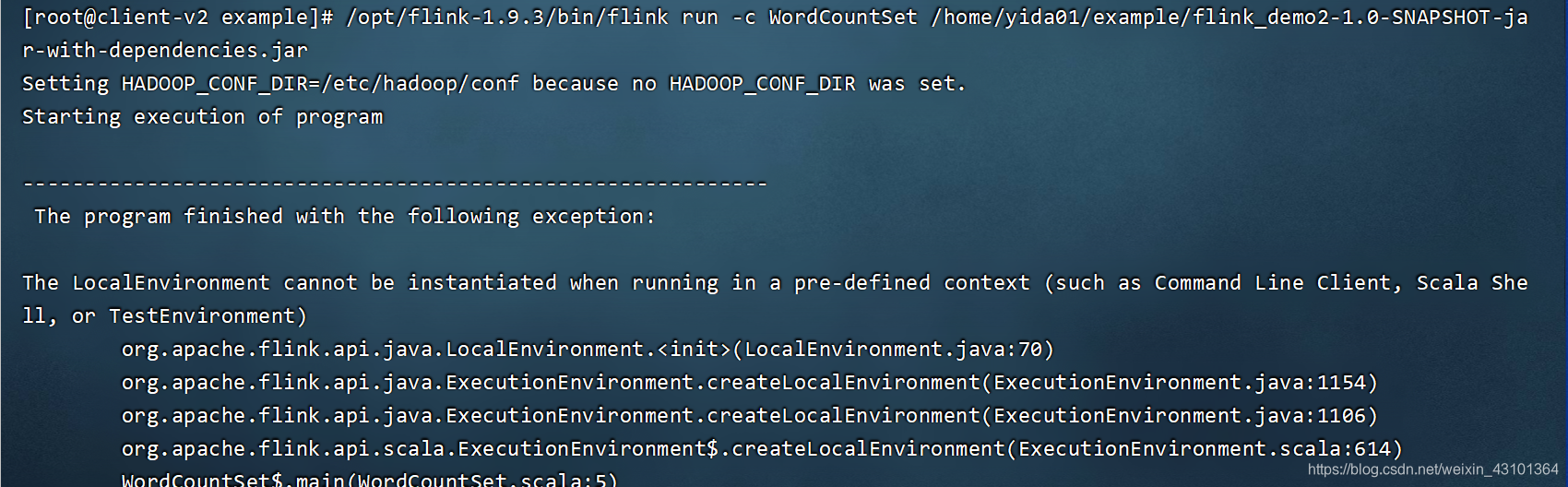
linux 上运行 flink 单词案例:
单机执行
/opt/flink-1.9.3/bin/flink run /opt/flink-1.9.3/examples/streaming/WordCount.jar
提交到yarn上执行
/opt/flink/flink-1.11.3/bin/flink run -t yarn-per-job --detached /opt/flink-1.9.3/examples/streaming/WordCount.jar
由于本地没有配置hadoop的环境变量,所以在执行之前需要先
export HADOOP_CLASSPATH=hadoop classpath
运行报错1:
Caused by: java.lang.NoSuchMethodError: scala.Predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
at World_CountStream$$anonfun$1.apply(World_CountStream.scala:13)
at World_CountStream$$anonfun$1.apply(World_CountStream.scala:13)
at org.apache.flink.streaming.api.scala.DataStream$$anon$6.flatMap(DataStream.scala:675)
at org.apache.flink.streaming.api.operators.StreamFlatMap.processElement(StreamFlatMap.java:50)
分析:
查资料发现是 scala 版本问题导致的问题,查看idea在进行打包的时候报如下错误,怀疑问题就是出在这里
org.apache.flink:flink-runtime_2.11:1.8.1 requires scala version: 2.11.12
org.scala-lang:scala-reflect:2.11.12 requires scala version: 2.11.12
org.apache.flink:flink-streaming-scala_2.11:1.8.1 requires scala version: 2.11.12
org.apache.flink:flink-streaming-scala_2.11:1.8.1 requires scala version: 2.11.12
org.scala-lang:scala-compiler:2.11.12 requires scala version: 2.11.12
org.scala-lang.modules:scala-xml_2.11:1.0.5 requires scala version: 2.11.7
Multiple versions of scala libraries detected!
解决方法如下:
<properties>
<scala.version>2.**</scala.version>
<scala.binary.version>2.**</scala.binary.version>
</properties>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.0.1</version>
<configuration>
<scalaCompatVersion>${scala.binary.version}</scalaCompatVersion>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
<pligin>
不幸的是,还是出现同样的问题,
后面项目计划用java写,暂时不在这死磕了
运行报错2:
(YarnClusterDescriptor.java:1036)- Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
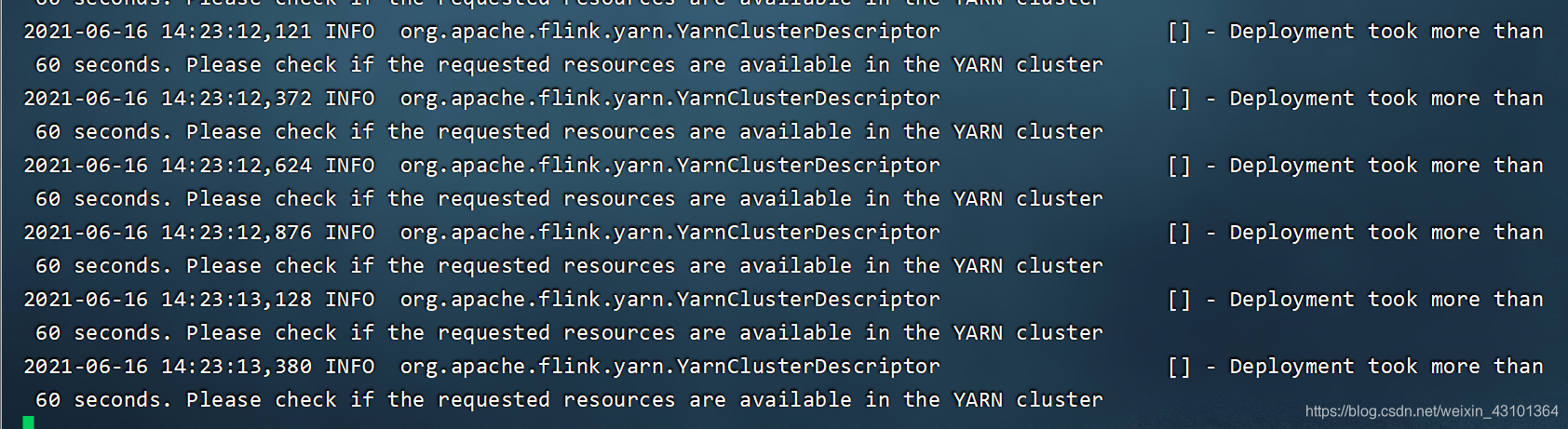
参考链接:
https://cloud.tencent.com/developer/article/1759954
借鉴大佬的分析思路,最终确定是 yarn分配的资源不足导致job一直处于 pending 状态,如下
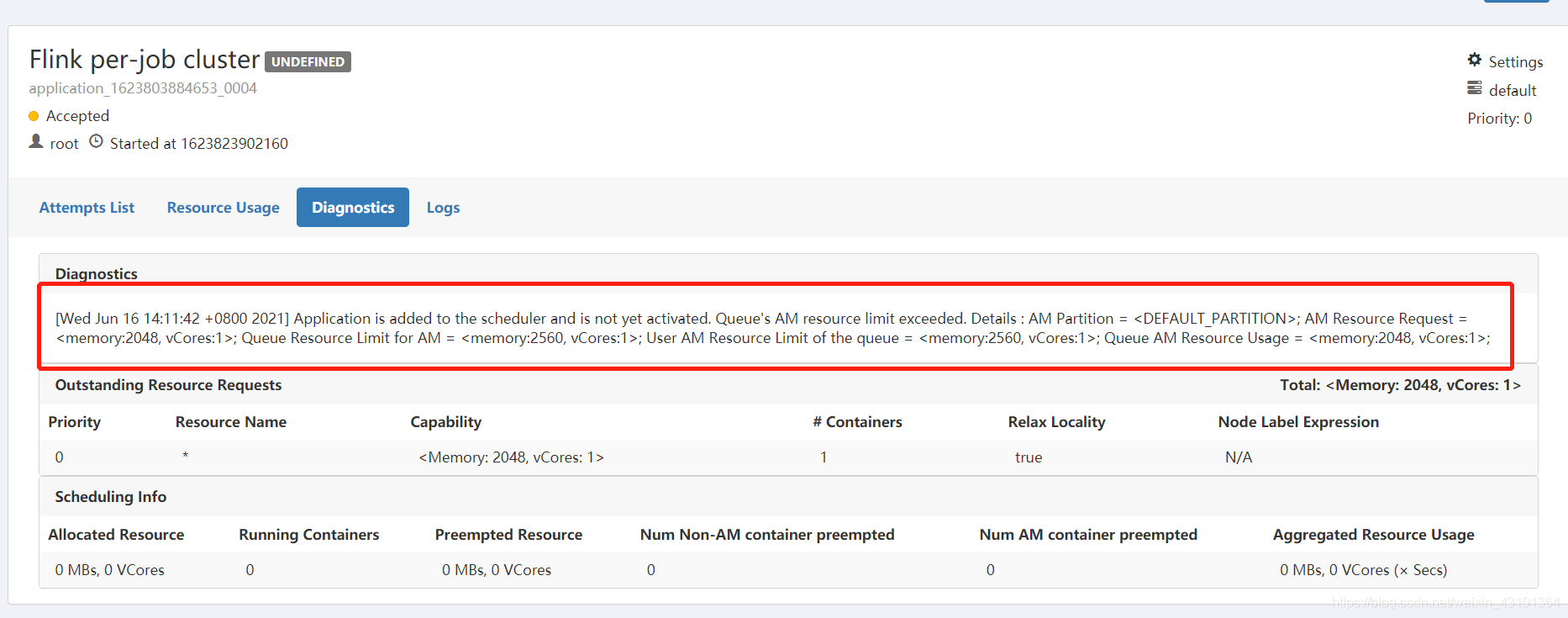
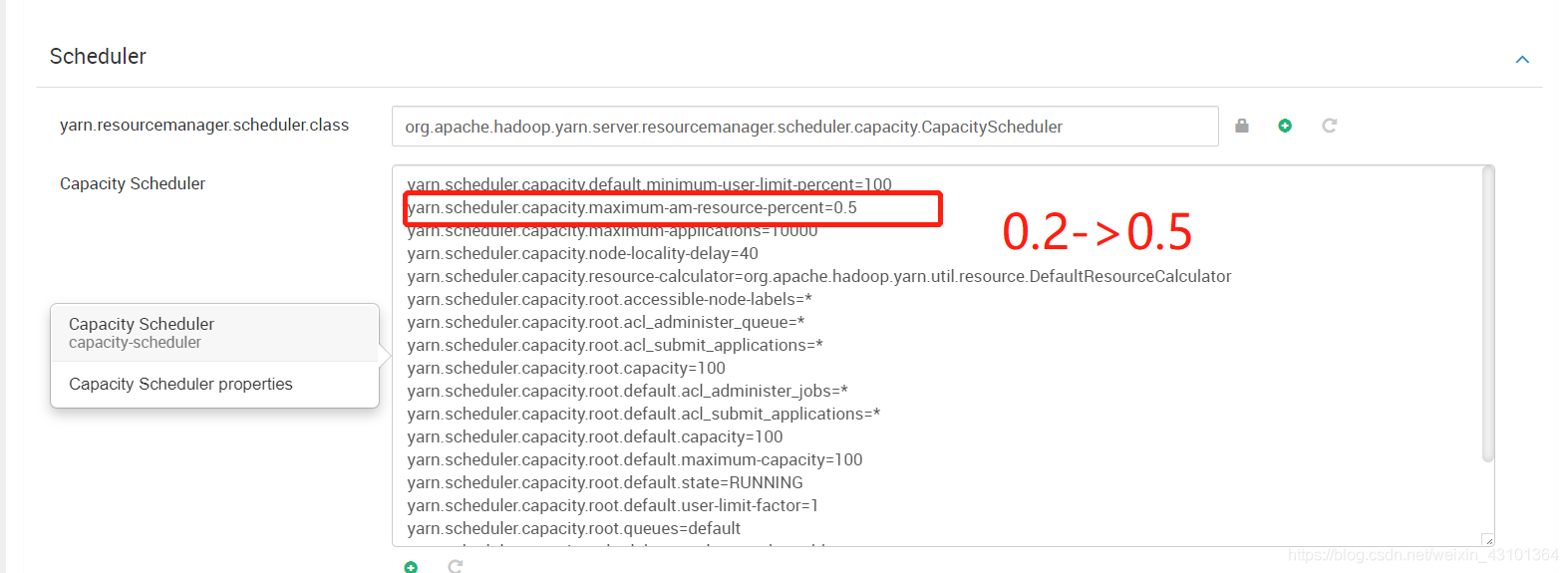
解决方法:
我采用的是 Ambari 搭建的yarn,所以修改平台上配置,修改后job执行成功。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









