






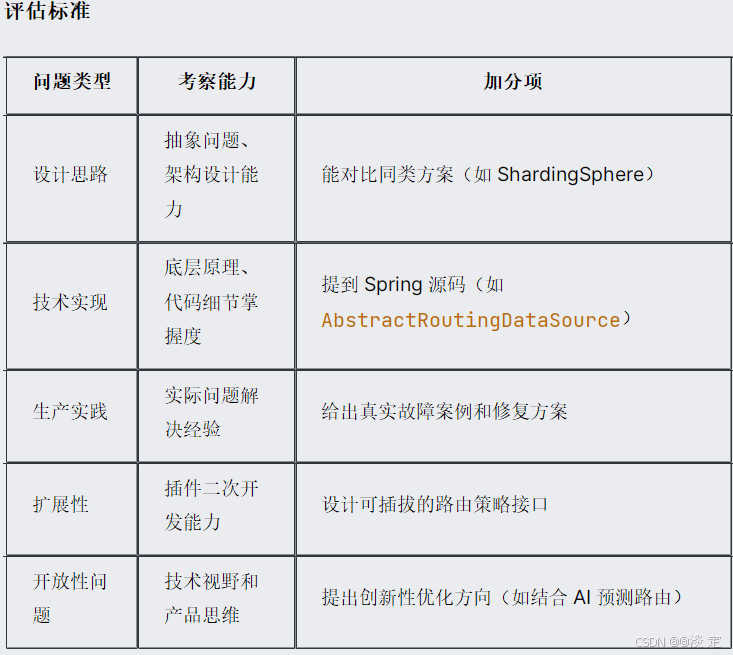
围绕该数据库路由插件的 设计思路、技术实现、扩展性、事务处理 和 生产实践 等方面提出以下问题:
一、设计思路
-
核心目标 “这个插件的核心目标是什么?它解决了哪些传统分库分表方案的痛点?”
考察点:对分库分表中间件价值的理解,如透明化路由、无侵入式集成、动态切换等。 -
透明化设计 “如何让业务代码无需感知分库分表的存在?插件在哪些层级(DAO/Service)做了透明化处理?” 考察点:对 AOP、MyBatis 拦截器、动态数据源等技术的综合应用理解。

二、技术实现
- 动态数据源
“动态数据源 DynamicDataSource 如何实现运行时切换?请解释AbstractRoutingDataSource 的工作原理。” 考察点:对 Spring 动态数据源机制和 ThreadLocal上下文传递的掌握。

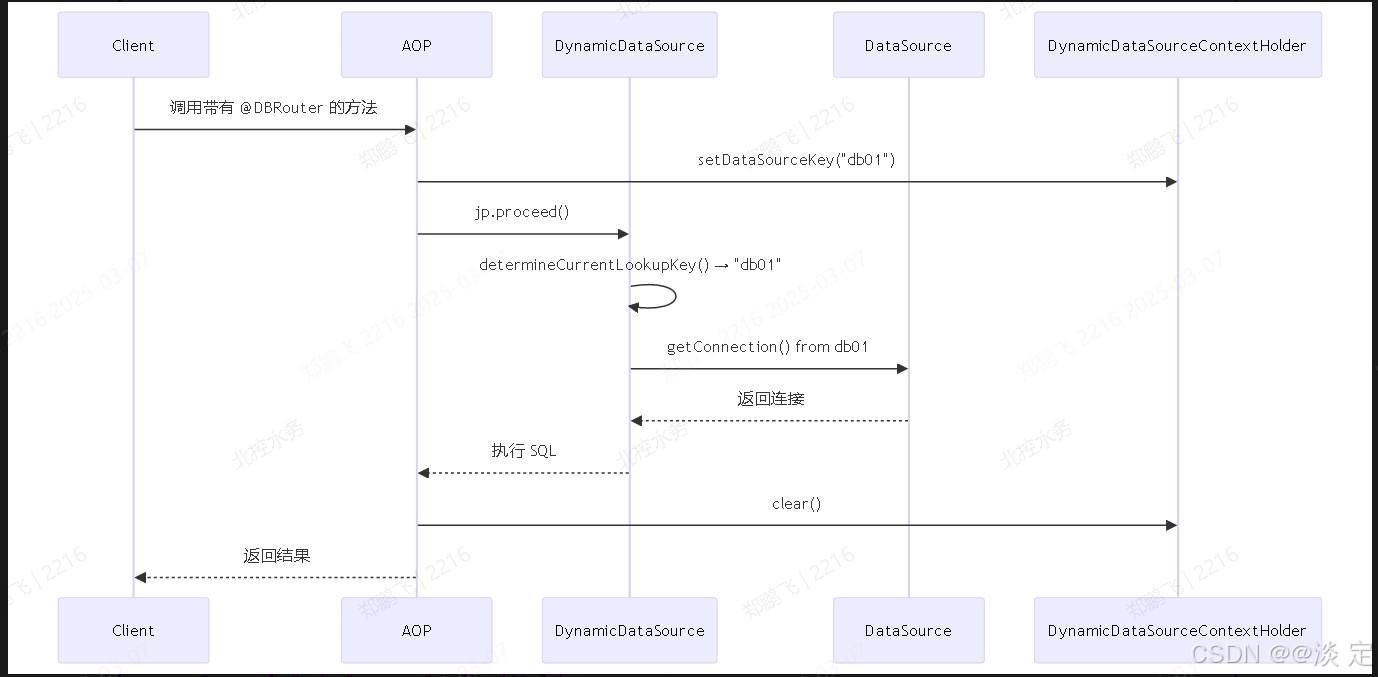
-
路由策略 “哈希取模策略在数据扩容时有什么问题?如果改用一致性哈希或范围分片,插件需要如何改造?”
考察点:分库分表算法的优缺点理解和扩展能力。

-
SQL 重写 “MyBatis 拦截器如何实现表名动态替换?如何处理 JOIN 操作或子查询中的分表逻辑?” 考察点:对 SQL解析和复杂场景的覆盖能力。

-
事务一致性 “在跨库事务场景中,如何保证数据一致性?插件是否支持分布式事务(如 Seata)?”
考察点:对事务边界和分布式事务方案的理解。

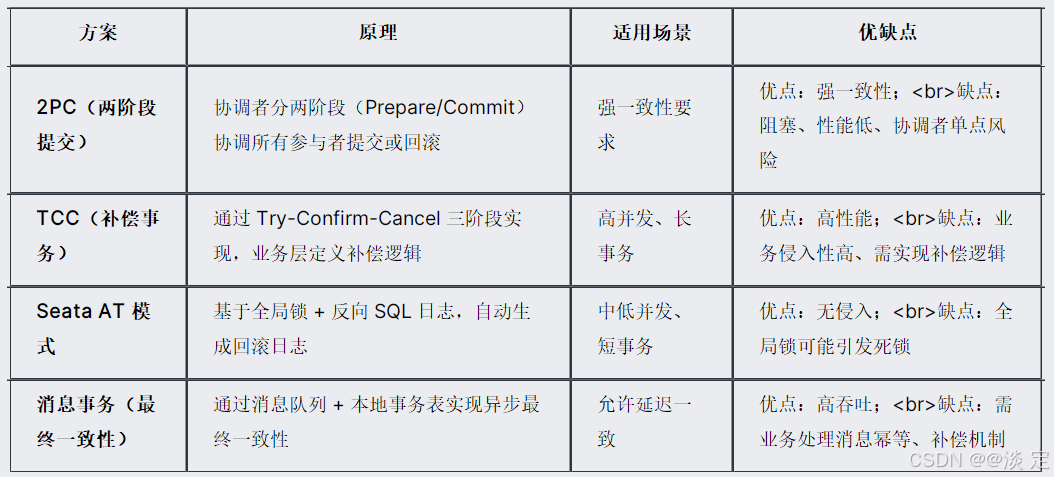
三、扩展性与容错
-
配置热更新 “如何实现分库分表配置(如新增数据源)的动态加载,而无需重启应用?” 考察点:对配置中心(如 Apollo、Nacos)和运行时刷新的设计思路。
Nacos 实现分库分表配置动态加载和问题

-
故障转移 “当某个分库不可用时,插件如何实现自动故障转移?是否支持降级到默认数据源?” 考察点:高可用设计和容错机制。

四、生产实践
-
数据倾斜问题 “如果路由键(如 userId)分布不均匀导致数据倾斜,如何通过插件优化?”
考察点:实际问题解决能力,如引入二级路由、盐值哈希等方案。

-
监控与排查 “如何监控数据源的健康状态?如果发现某个分库查询延迟高,如何快速定位问题?”
考察点:对监控体系(Prometheus、日志追踪)和排查工具的设计经验

五、代码细节
-
Bean 加载顺序 “为什么 mysqlDataSource 会先于 dbRouterStrategy初始化?如果强制让路由策略先初始化,如何修改代码?” 考察点:对 Spring Bean 生命周期和 @DependsOn 的实际应用。

-
ThreadLocal 风险 “DynamicDataSourceContextHolder 使用 ThreadLocal可能存在什么隐患?如何避免内存泄漏?” 考察点:对线程池环境下 ThreadLocal 的清理机制的理解。

-
连接池配置 “在 createDataSource 方法中,如何确保不同分库的连接池参数(如最大连接数)独立配置?”
考察点:对连接池精细化管理的实现细节

六、场景题
- 跨库查询 “业务需要根据非路由键字段(如 orderTime)查询全量数据,插件如何支持?” 期望答案:广播查询(所有分库并行执行)+结果聚合。

- 分布式主键 “分库分表后如何生成全局唯一 ID?插件是否集成雪花算法或其他方案?” 考察点:对分布式 ID 生成器的了解。

七、开放性问题
-
与 ShardingSphere 对比 “你们的插件与 ShardingSphere的核心差异是什么?在什么场景下会选择自研而非使用成熟方案?” 考察点:技术选型能力和对开源方案的认知

-
未来优化方向 “如果继续迭代这个插件,下一步你会优先优化什么功能?为什么?” 考察点:技术前瞻性和需求洞察力。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











