







1.决策树是如何工作的
决策树是一种非参数的有监督学习方法。
决策树核心解决两个问题:
①如何从数据表中找出最佳节点和最佳分枝
②如何让决策树停止生长,防止过拟合
2.Decision Tree与红酒数据集
2.1.1 criterion
信息熵(Entropy)和基尼系数(Gini Impurity)
相比基尼系数,信息熵对不纯度更加敏感,对不纯度的惩罚最强。
通常选取基尼系数就可以。当数据维度大,噪声很大时使用基尼系数;数据维度低,信息熵和基尼系数没区别;对训练集的拟合程度不够时,使用信息熵。
1.将wine.data和wine.target转化为dataframe的同时,进行合并:
pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1)
2.特征名称和目标名称
wine.feature_names
wine.target_names
3.特征重要性
clf是用Xtrain和Ytrain拟合过的模型
每个特征的重要性:[*zip(feature_name,clf.feature_importances_)]
2.1.2 random_state&splitter
splitter选择best或random
best:分枝时虽然随机,但还是会优先选择更重要的特征进行分枝;
random:分枝会更加随机。
1.建立模型的时候,参数中要有random_state,这样可以保证模型返回分数的稳定性。
2.1.3.剪枝参数
决策树太大太深会造成它在训练集上表现很好,在测试集上表现糟糕。
1.max_depth
建议从3开始尝试
2.min_samples_leaf&min_samples_split
①min_samples_leaf:一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本。(针对分枝后的子节点)
②min_samples_split:一个节点必须要包含min_samples_split个训练样本,这个节点才能被分枝。(针对分枝节点)
3.max_features&min_impurity_decrease
max_feature限制最多的特征数
min_impurity_decrease限制最小信息增益
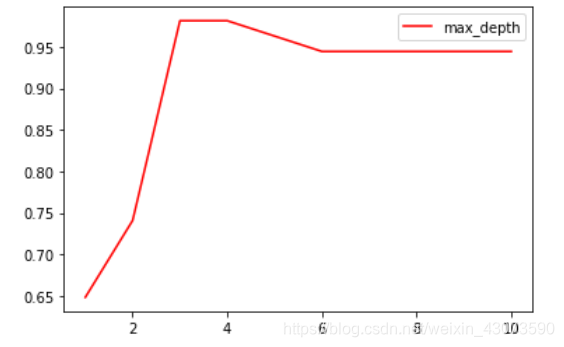
4.确定最优的剪枝参数
用学习曲线
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion='entropy'
,random_state=30
,splitter='random'
)
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
test.append(score)#把10次score的值都输入test
plt.plot(range(1,11),test,color='red',label='max_depth')
plt.legend()
plt.show()
2.1.4 目标权重参数
class_weight:对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类。
2.2 重要属性及接口
apply中输入测试集,返回每个测试样本所在的叶子节点的索引
predict中输入测试集返回每个测试样本的标签
3.DecisionTreeRegressor
3.1 重要参数,属性及接口
1.criterion:
①mse均方误差;②friedman_mse费尔德曼均方误差;③mae绝对平均误差
3.2 实例:一维回归的图像绘制
画正弦曲线
rng = np.random.RandomState(1)#随机种子,括号内的数字随便填
#np.random.rand() 通过本函数可以返回一个或一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。
x = np.sort(5*rng.rand(80,1),axis=0) #必须是二维的数组,因为fit等接口不允许有一维的数组输入;axis=0表示排序方向
y = np.sin(x).ravel() #X可以是多维的,但y必须是一维的,所以用ravel函数进行降维
加噪音
#y[::5]表示所有行所有列每隔5个取一个,80个数据一共可以去16个
y[::5] += 3*(0.5 - rng.rand(16)) #在正弦曲线上加噪声
4.实例:泰坦尼克号幸存者的预测
1.导入数据的方法
data = pd.read_csv(r"E:\菜菜的机器学习\课件\01 决策树课件数据源码\data.csv",index_col=0)#如果去掉r,左斜杠(/)则改成右斜杠
2.观察数据
data.info()
#object是文本类型,需要转化为数值类型

3.删除没用的列
#删除列:缺失值过多的列(Cabin),和观测值无关的列(Name,Ticket)
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)#axis=1表示删除的是整列
4.处理缺失值
①用平均值填充
data.loc[:,'Age'] = data['Age'].fillna(data['Age'].mean())
②删除缺失值所在行
#Embark的缺失值只有两个——直接删除缺失值所在行
data = data.dropna()#默认axis=0
5.将分类变量转换为数值变量
三分类的情况
#转换Embarked列(三分类)
labels = data['Embarked'].unique().tolist()#unique函数看到底有几个取值;tolist函数---将数组变成一个列表
####labels = ['S','C','Q']
data['Embarked'] = data['Embarked'].apply(lambda x:labels.index(x))#将列表里所有的项转换为列表的索引
二分类的情况
#转换Sex列(二分类)
#完全可以用上面同样的方法,此次介绍另一种方法
data['Sex'] = (data['Sex']=='male').astype('int') #将bool值转化为int类型
6.将整个data分两块
一块儿是x,一块儿是y
x = data.loc[:,data.columns != 'Survived']#特征矩阵
y = data.loc[:,data.columns == 'Survived']#标签
7.重置索引
for i in [Xtrain,Xtest,Ytrain,Ytest]:#记得冒号
i.index = range(i.shape[0])#将数据集i中的索引转化为0至621的整数。#range是一个可迭代函数
#Xtrain.shape的输出为(622,8);Xtrain.shape[0]的输出为622

















 7297
7297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









