







 本文深入探讨浏览器的工作流程,从HTTP/HTTPS请求开始,详细讲解DOM树构建、CSS计算、渲染及合成过程。理解这些原理有助于前端开发者优化网页性能,提升用户体验。重点介绍了HTTP、HTTPS的区别,DOM解析、CSS渲染对JavaScript的影响,以及排版和渲染的细节。
本文深入探讨浏览器的工作流程,从HTTP/HTTPS请求开始,详细讲解DOM树构建、CSS计算、渲染及合成过程。理解这些原理有助于前端开发者优化网页性能,提升用户体验。重点介绍了HTTP、HTTPS的区别,DOM解析、CSS渲染对JavaScript的影响,以及排版和渲染的细节。
大概过程
- 浏览器首先使用 HTTP 协议或者 HTTPS 协议,向服务端请求页面
- 把请求回来的 HTML 代码经过解析,构建成 DOM 树
- 计算 DOM 树上的 CSS 属性
- 最后根据 CSS 属性对元素逐个进行渲染,得到内存中的位图
- 一个可选的步骤是对位图进行合成,这会极大地增加后续绘制的速度
- 合成之后,再绘制到界面上
从 HTTP 请求回来,就产生了流式的数据,后续的 DOM 树构建、CSS 计算、渲染、合成、绘制,都是尽可能地流式处理前一步的产出:即不需要等到上一步骤完全结束,就开始处理上一步的输出,这样我们在浏览网页时,才会看到逐步出现的页面
HTTP
- 详见网络篇
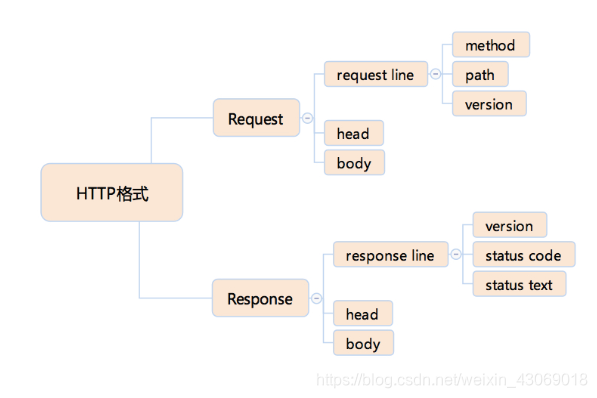
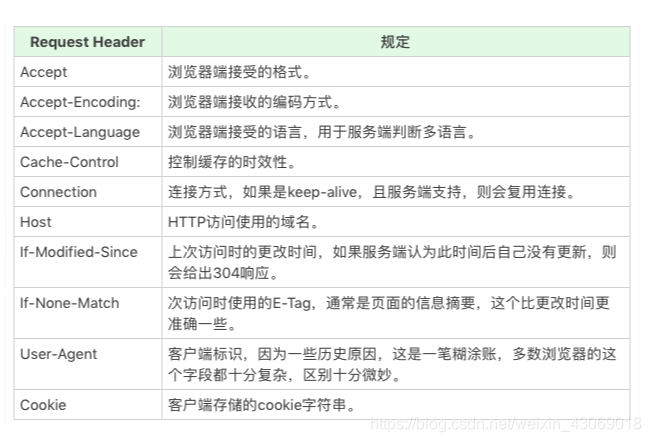

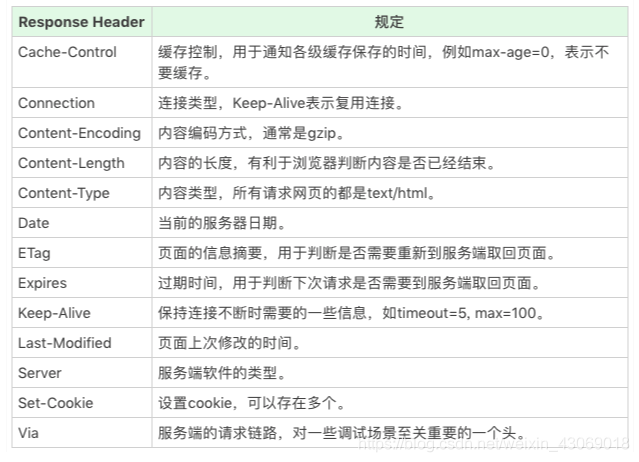

HTTPS - HTTPS 是使用加密通道来传输 HTTP 的内容。但是 HTTPS 首先与服务端建立一条 TLS 加密通道。TLS 构建于 TCP 协议之上,它实际上是对传输的内容做一次加密,所以从传输内容上看,HTTPS 跟 HTTP 没有任何区别
解析请求返回HTML DOM树的构建
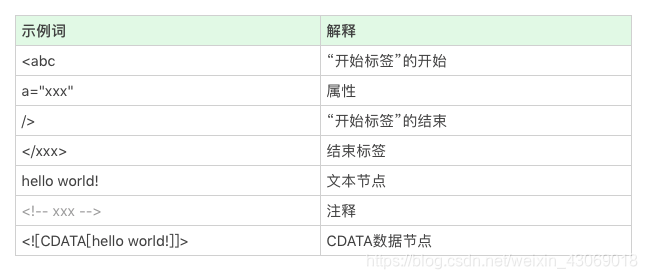
- 我们日常开发需要的 90% 的“词”(指编译原理的术语 token,表示最小的有意义的单元),种类大约只有标签开始、属性、标签结束、注释、CDATA 节点几种
<p class="a">text text text</p>
如果我们从最小有意义单元的定义来拆分,第一个词(token)是什么呢?显然,作为一个词(token),整个 p 标签肯定是过大了(它甚至可以嵌套)
只用 p 标签的开头是不是合适吗?我们考虑到起始标签也是会包含属性的,最小的意义单元其实是“<p” ,所以“ <p” 就是我们的第一个词(token)
<p“标签开始”的开始;
class=“a” 属性;
“标签开始”的结束;
text text text 文本;
</p>标签结束。
大多数语言的词法部分是通过状态机来实现的
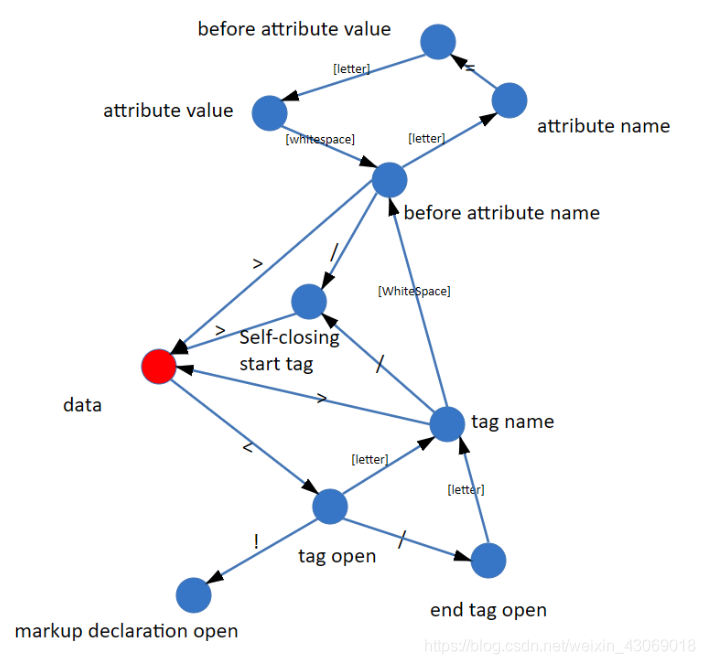
// 状态机
var data = function(c){
if(c=="&") {
return characterReferenceInData;
}
if(c=="<") {
return tagOpen;
}
else if(c=="\0") {
error();
emitToken(c);
return data;
}
else if(c==EOF) {
emitToken(EOF);
return data;
}
else {
emitToken(c);
return data;
}
};
var tagOpenState = function tagOpenState(c){
if(c=="/") {
return endTagOpenState;
}
if(c.match(/[A-Z]/)) {
token = new StartTagToken();
token.name = c.toLowerCase();
return tagNameState;
}
if(c.match(/[a-z]/)) {
token = new StartTagToken();
token.name = c;
return tagNameState;
}
if(c=="?") {
return bogusCommentState;
}
else {
error();
return dataState;
}
};
// 状态迁移代码
var state = data;
var char
while(char = getInput())
state = state(char);
// 词法分析器接受字符
function HTMLLexicalParser(){
// 状态函数们……
function data() {
// ……
}
function tagOpen() {
// ……
}
// ……
var state = data;
this.receiveInput = function(char) {
state = state(char);
}
}
我们就把字符流拆成了词(token)
构建DOM树
- 接下来我们要把这些简单的词变成 DOM 树,这个过程我们是使用栈来实现的,任何语言几乎都有栈,为了给你跑着玩,我们还是用 JavaScript 来实现吧,毕竟 JavaScript 中的栈只要用数组就好了
function HTMLSyntaticalParser(){
var stack = [new HTMLDocument];
this.receiveInput = function(token) {
//……
}
this.getOutput = function(){
return stack[0];
}
}
- 为了构建 DOM 树,我们需要一个 Node 类,接下来我们所有的节点都会是这个 Node 类的实例
function Element(){
this.childNodes = [];
}
function Text(value){
this.value = value || "";
}
CSS渲染
- 构建 DOM 的过程是:从父到子,从先到后,一个一个节点构造,并且挂载到 DOM 树上的,那么这个过程中, CSS 属性也可同步计算出来
- 我们依次拿到上一步构造好的元素,去检查它匹配到了哪些规则,再根据规则的优先级,做覆盖和调整。所以,从这个角度看,所谓的选择器,应该被理解成“匹配器”才更合适
空格: 后代,选中它的子节点和所有子节点的后代节点。
>: 子代,选中它的子节点。
+:直接后继选择器,选中它的下一个相邻节点。
~:后继,选中它之后所有的相邻节点。
||:列,选中表格中的一列。
- CSS 选择器按照 compound-selector 来拆成数段,每当满足一段条件的时候,就前进一段
a#b .cls {
width: 100px;
}
- 在上面的例子中,当我们找到了匹配 a#b 的元素时,我们才会开始检查它所有的子代是否匹配 .cls
<a id=b>
<span>1<span>
<span class=cls>2<span>
</a>
<span class=cls>3<span>
当遇到 时,必须使得规则 a#b .cls 回退一步,这样第三个 span 才不会被选中。后代选择器的作用范围是父节点的所有子节点,因此规则是在匹配到本标签的结束标签时回退。
#a .cls {
}
#a span {
}
#a>span {
}

css加载不会阻塞DOM树的解析
css加载会阻塞DOM树的渲染
css加载会阻塞后面js语句的执行
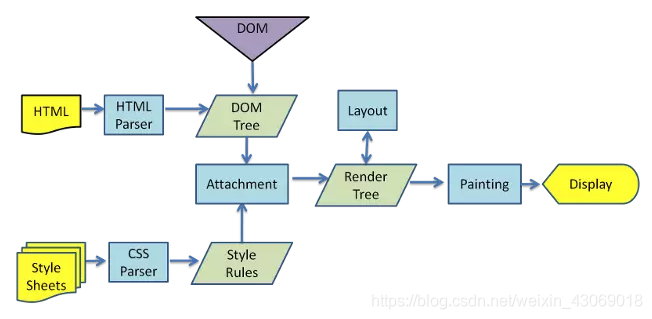
- webkit渲染过程
- Gecko渲染过程
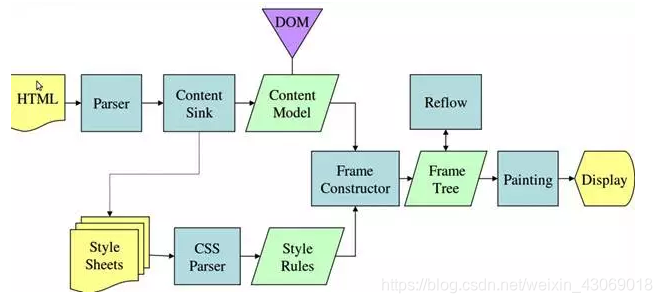
DOM解析和CSS解析是两个并行的进程,所以这也解释了为什么CSS加载不会阻塞DOM的解析。
然而,由于Render Tree是依赖于DOM Tree和CSSOM Tree的,所以他必须等待到CSSOM Tree构建完成,也就是CSS资源加载完成(或者CSS资源加载失败)后,才能开始渲染。因此,CSS加载是会阻塞Dom的渲染的。
由于js可能会操作之前的Dom节点和css样式,因此浏览器会维持html中css和js的顺序。因此,样式表会在后面的js执行前先加载执行完毕。所以css会阻塞后面js的执行。
DOMContentLoaded
对于浏览器来说,页面加载主要有两个事件,一个是DOMContentLoaded,另一个是onLoad。而onLoad没什么好说的,就是等待页面的所有资源都加载完成才会触发,这些资源包括css、js、图片视频等。
而DOMContentLoaded,顾名思义,就是当页面的内容解析完成后,则触发该事件。那么,正如我们上面讨论过的,css会阻塞Dom渲染和js执行,而js会阻塞Dom解析。
排版
- 浏览器最基本的排版方案是正常流排版,它包含了顺次排布和折行等规则,这是一个跟我们提到的印刷排版类似的排版方案,也跟我们平时书写文字的方式一致,所以我们把它叫做正常流
- 浏览器又可以支持元素和文字的混排,元素被定义为占据长方形的区域,还允许边框、边距和留白,这个就是所谓的盒模型
- 正常流的基础上,浏览器还支持两类元素:绝对定位元素和浮动元素
- 绝对定位元素把自身从正常流抽出,直接由 top 和 left 等属性确定自身的位置,不参加排版计算,也不影响其它元素。绝对定位元素由 position 属性控制
- 浮动元素则是使得自己在正常流的位置向左或者向右移动到边界,并且占据一块排版空间。浮动元素由 float 属性控制
- 除了正常流,浏览器还支持其它排版方式,比如现在非常常用的 flex 排版,这些排版方式由外部元素的 display 属性来控制(注意,display 同时还控制元素在正常流中属于 inline 等级还是 block 等级)
- position 属性为 absolute 的元素,我们需要根据它的包含块来确定位置,这是完全跟正常流无关的一种独立排版模式,逐层找到其父级的 position 非 static 元素即可
- float 元素非常特别,浏览器对 float 的处理是先排入正常流,再移动到排版宽度的最左 / 最右(这里实际上是主轴的最前和最后)
渲染
- 模型变成位图过程
- 位图就是在内存里建立一张二维表格,把一张图片的每个像素对应的颜色保存进去(位图信息也是 DOM 树中占据浏览器内存最多的信息
合成
- 渲染过程不会把子元素渲染到位图上面,合成的过程,就是为一些元素创建一个“合成后的位图”(我们把它称为合成层),把一部分子元素渲染到合成的位图上面
绘制
- 位图最终绘制到屏幕上,变成肉眼可见的图像
- 一般来说,浏览器并不需要用代码来处理这个过程,浏览器只需要把最终要显示的位图交给操作系统即可
- 绘制过程,实际上就是按照 z-index 把它们依次绘制到屏幕上


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









