数据解释
t_user 观众表(6000+ 条数据)
- 字段为:UserID, Sex, Age, Occupation, Zipcode
- 字段中文解释:用户 id,性别,年龄,职业,邮编
t_movie 电影表(共 3000+ 条数据)
- 字段为:MovieID, MovieName, MovieType
- 字段中文解释:电影 ID,电影名,电影类型
t_rating 影评表(100 万 + 条数据)
- 字段为:UserID, MovieID, Rate, Times
- 字段中文解释:用户 ID,电影 ID,评分,评分时间
-
1.数据放到服务器上(略)
2.将数据放hdfs上(略)
3.从/data/hive copy一份数据到自己的hdfs文件夹下(/data/hive学习的时候该文件是共享的,为了不破坏大家使用,所以需要cp一份到自己的目录)
hadoop fs -cp /data/hive/users /user/jean/week4
hadoop fs -cp /data/hive/movies /user/jean/week4
hadoop fs -cp /data/hive/ratings /user/jean/week4
数据准备:
-- 建t_movie表
CREATE TABLE `t_movie`(
`movie_id` bigint COMMENT '电影id',
`movie_name` string COMMENT '电影名字',
`movie_type` string COMMENT '电影类型')
ROW FORMAT SERDE
'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES (
'field.delim'='::') -- 按::进行分隔,如果数据本身是别的分隔符,按具体情况选择,例如:\t
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/user/jean/week4/movies' -- hdfs文件路径
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1648533877');
-- 建t_rating表
CREATE TABLE `t_rating`(
`user_id` int COMMENT '用户id',
`movie_id` bigint COMMENT '电影id',
`rate` int COMMENT '评分',
`times` string COMMENT '评分时间')
ROW FORMAT SERDE
'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES (
'field.delim'='::')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/user/jean/week4/ratings' -- hdfs文件路径
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1648534400');
-- 建t_user表
CREATE TABLE `t_user`(
`user_id` int COMMENT '用户id',
`sex` string COMMENT '性别',
`age` int COMMENT '年龄',
`occupation` string COMMENT '职业',
`zip_code` bigint COMMENT '邮编')
ROW FORMAT SERDE
'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES (
'field.delim'='::')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'/user/jean/week4/users' -- hdfs文件路径
TBLPROPERTIES (
'bucketing_version'='2',
'transient_lastDdlTime'='1648534260')
题目一(简单):展示电影 ID 为 2116 这部电影各年龄段的平均影评分。
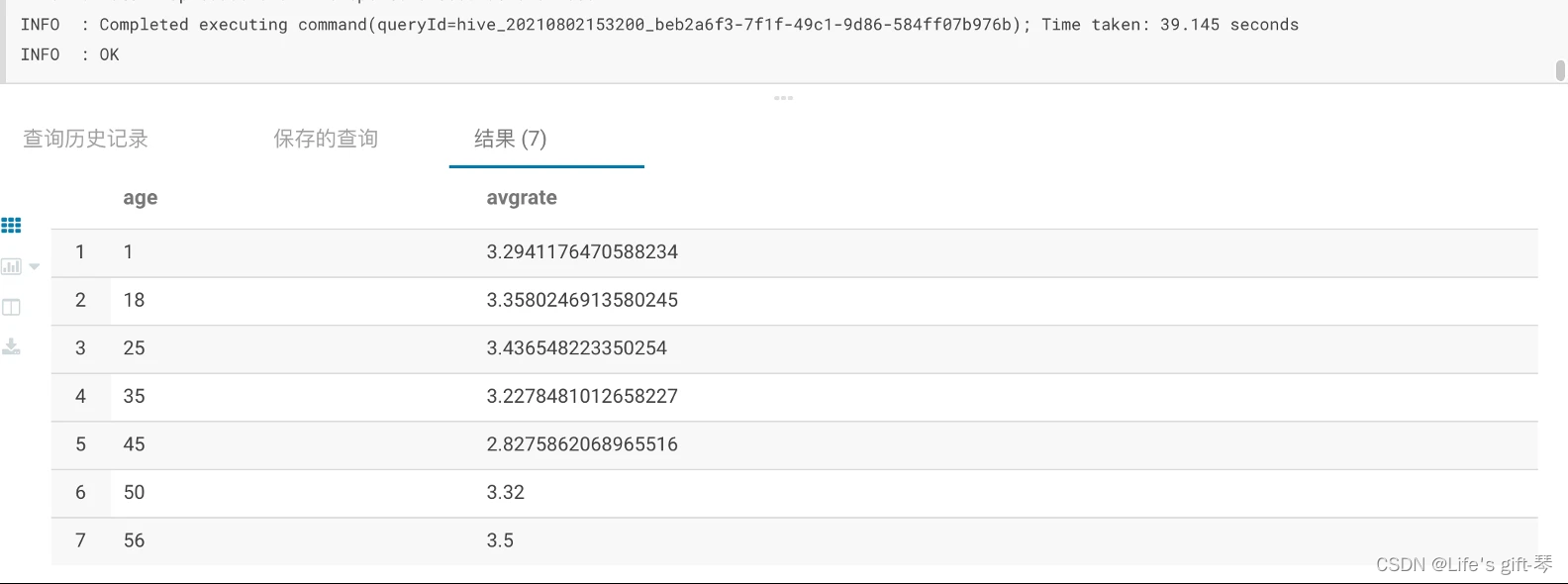
解析:方法一(比较冗余)
SELECT
u.age AS age,
AVG(m.rate) AS avgrate
FROM
t_user AS u
JOIN (
SELECT
b.rate AS rate,
b.user_id AS user_id
FROM
t_movie AS a
INNER JOIN (
SELECT
*
FROM
t_rating
WHERE
movie_id = 2116
) AS b ON a.movie_id = b.movie_id
WHERE
a.movie_id = 2116
) m ON u.user_id = m.user_id
GROUP BY
age
ORDER BY
age;
解析:方法二 (推荐)
SELECT
c.age,
avg(b.rate)
FROM
t_movie a
JOIN t_rating b ON a.movie_id = b.movie_id
JOIN t_user c ON c.user_id = b.user_id
WHERE
a.movie_id = 2116
GROUP BY
c.age
ORDER BY
c.age;
解题思路:3表联合join 的使用
题目二(中等):找出男性评分最高且评分次数超过 50 次的 10 部电影,展示电影名,平均影评分和评分次数。
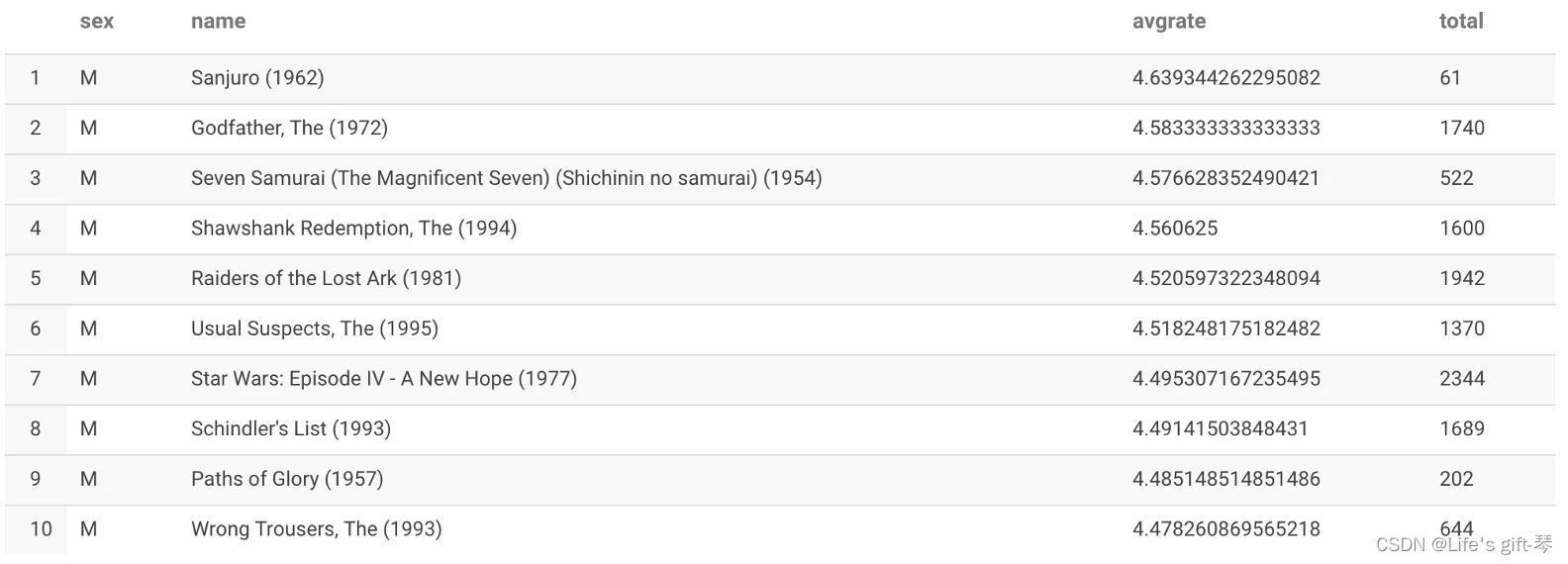
解析:(注意:先平均 在排序取高)
create temporary table answer2 as
select
"M" as sex, c.movie_name as name, avg(a.rate) as avgrate, count(c.movie_name) as total
from t_rating a
join t_user b on a.user_id=b.user_id
join t_movie c on a.movie_id=c.movie_id
where b.sex="M"
group by c.movie_name
having total > 50
order by avgrate desc
limit 10;
题目三(选做):找出影评次数最多的女士所给出最高分的 10 部电影的平均影评分,展示电影名和平均影评分(可使用多行 SQL)。
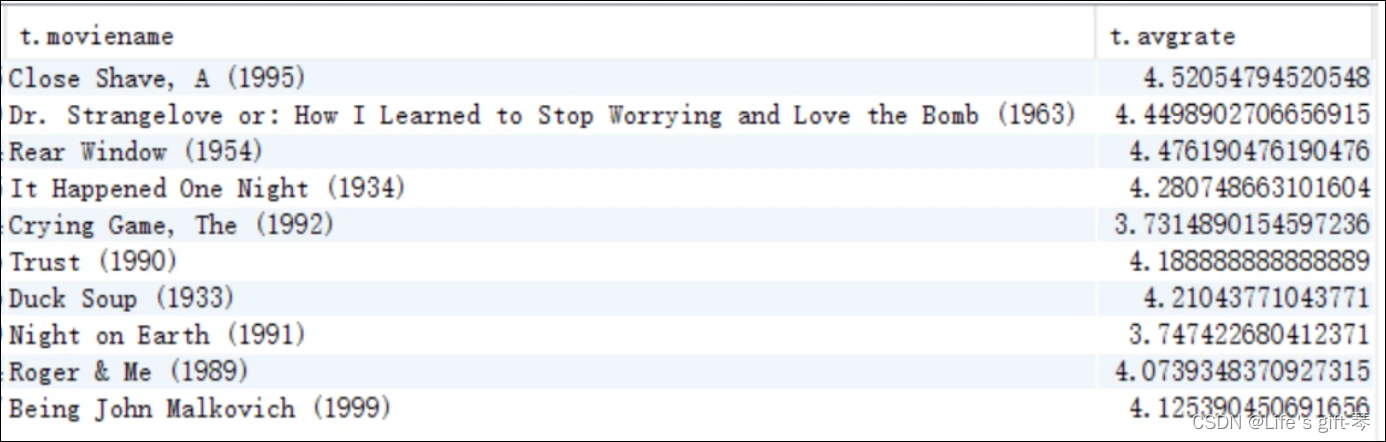
解析:可以创键临时表 (注意:先排序取高 在取平均)
# 女性影评次数最多,use_id=1150
create table answer1_f as
select a.user_id from t_user a join t_rating b on a.user_id=b.user_id where a.sex = "F" group by a.user_id ORDER BY COUNT(1) DESC limit 1;
# 评分最高的电影
create table answer2 as
select movie_id,rate from t_rating where user_id = 1150 order by rate desc limit 10;
create table answer3 as
select b.movie_id as movieid, c.movie_name as moviename, avg(b.rate) as avgrate
from answer2 a
join t_rating b on a.movie_id=b.movie_id
join t_movie c on b.movie_id=c.movie_id
group by b.movie_id,c.movie_name;










 本文介绍了如何在Hive中处理和分析电影评分数据,包括创建表、数据导入以及进行复杂查询。通过展示不同年龄段对电影ID为2116的平均评分,找出男性评分最高且评分次数超过50次的10部电影,以及找出影评次数最多的女士给出的最高分电影的平均评分。内容涉及多表联合查询、聚合函数和条件筛选,对于Hive数据处理和分析具有实践指导意义。
本文介绍了如何在Hive中处理和分析电影评分数据,包括创建表、数据导入以及进行复杂查询。通过展示不同年龄段对电影ID为2116的平均评分,找出男性评分最高且评分次数超过50次的10部电影,以及找出影评次数最多的女士给出的最高分电影的平均评分。内容涉及多表联合查询、聚合函数和条件筛选,对于Hive数据处理和分析具有实践指导意义。

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









