






一. 基础理论
1. 进程与线程
什么是进程?什么是线程?
百度百科中是这样解释的:
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。程序是指令、数据及其组织形式的描述,进程是程序的实体
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
生活举例:
当你打开电脑,你下意识的打开微信和TIM,如果这时你注意你的任务管理器,你会发现已经增加了两个进程:
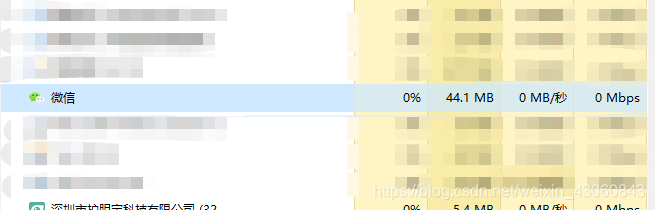
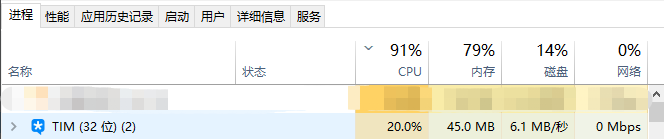
进程就是你运行了某一个软件。在这个软件中,比如你用微信和人聊天,和人视频,传输文件都是这一个进程下的多个线程。
2. 进程与线程的使用场景
我们在使用 requests 请求 URL、查询远程数据库或者读写本地文件的时候,就是 I/O操作。这些操作的共同特点就是要等待。
以 request 请求URL 为例,requests 发起请求,也许只需要0.01秒的时间。然后程序就卡住,等待网站返回。请求数据通过网络传到网站服务器,网站服务器发起数据库查询请求,网站服务器返回数据,数据经过网线传回你的电脑。requests 收到数据以后继续后面的操作。
大量的时间浪费在等待网站返回数据。如果我们可以充分利用这个等待时间,就能发起更多的请求。
但对于需要大量计算任务的代码来说,CPU 始终处于高速运转的状态,没有等待,所以就不存在利用等待时间做其它事情的说法。
所以:
- IO密集型使用多线程
- 计算密集型使用多进程
3. 进程和线程的区别
- 多线程可以共享全局变量,多进程不能(多线程可以在一个进程中运行同样的程序)
- 线程共享内存空间;进程的内存是独立的
- 一个进程至少有一个线程,线程不能够独立执行,必须依存在进程中
二. 代码实现
- 操作系统:Ubuntu 18.04
- Python版本:python 3.8
- 编辑器:Jupyter
1. 准备工作
引包
import requests
import json
import multiprocessing
import time
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
目标网址:图片网站Unsplash
下载程序:
## 获取图片下载地址
def get_urls(url):
urls = []
response = requests.get(url)
results= json.loads(response.text)["results"]
for data in results:
down_url = data["links"]["download"]
urls.append(down_url)
return urls
## 下载图片到本地
def download_pic(urls):
response = requests.get(urls)
with open("./pic/"+str(time.time())+".png","wb") as f:
f.write(response.content)
print("下载完成")
2. 单线程抓取
%%time
origin_url = "https://unsplash.com/napi/search/photos?query=desert&xp=&per_page=20&page={}"
for i in range(1,2):
urls = get_urls(origin_url.format(i))
for url in urls:
download_pic(url)
结果:
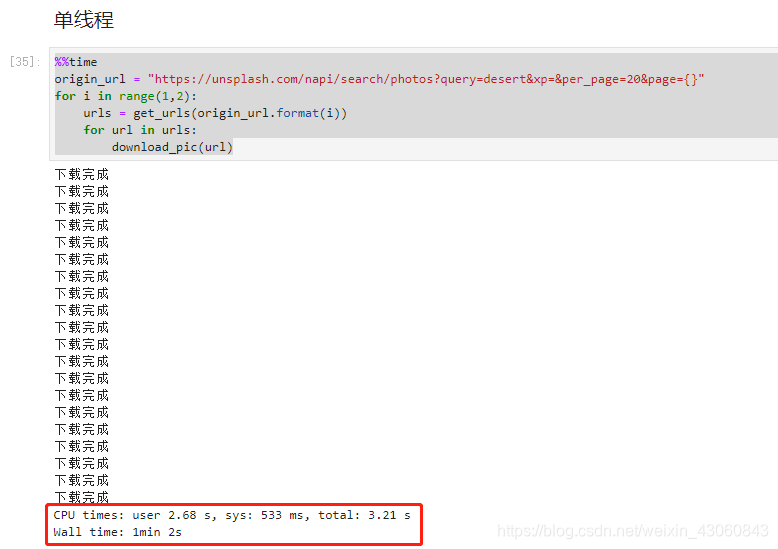
如图所示,我们只是使用for循环一个接一个地遍历url并下载图片。我们可以使用IPython的%%time函数对消耗的时间进行统计,这个读取13个网页的任务总时间需要1分2秒,CPU计算时间为2.68秒。
3. 多线程抓取
%%time
urls = get_urls(origin_url.format(1))
t_pool = ThreadPool(20)
t_pool.map(download_pic,urls)
t_pool.close()
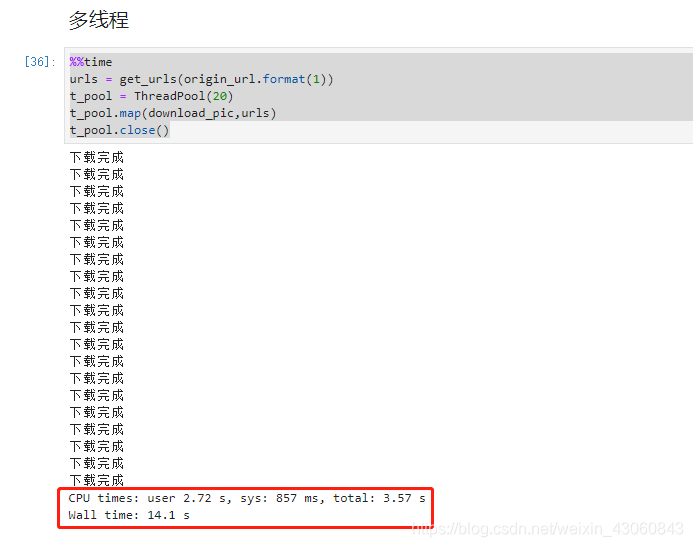
当我们不使用for循环,而是使用多线程(20个线程)来爬取图片时,总用时为12.1s,CPU计算时间为2.72秒。比单线程所用时间快了5倍左右。
这是因为读取url所花费的大部分时间是由于网络延迟。与io绑定的程序大部分时间都在等待输入/输出,无所事事。这可能是来自网络、数据库、文件甚至用户的I/O。这种I/O往往要花费大量的时间。
scrapy使用的是基于Twisted框架的多线程,而不是多进程!!!
所以,多线程可以显著提高我们爬取网页任务的效率。
。
4. 多进程抓取
%%time
urls = get_urls(origin_url.format(1))
pool = multiprocessing.Pool(processes=4)
pool.map(download_pic,urls)
pool.close()
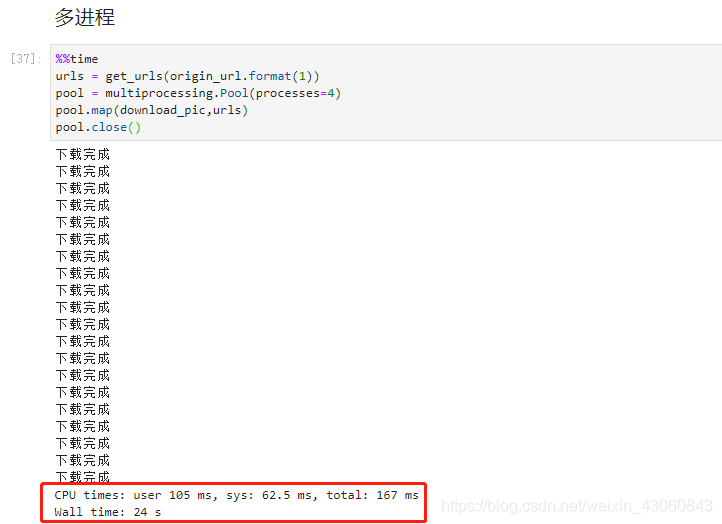
当我们使用多进程时,总用时为24秒,CPU计算速度为105ms。虽然总用时是多线程用时的两倍,但是CPU计算速度时间大大缩减。因为图片下载本身是IO密集型操作,所以多线程是明显更占优势的。但是CPU耗时更少,因为相当于本来一个人的工作现在分担给四个人做,所以处理时间会大大缩短。但是多线程还是比单线程要快的多。
当我们在爬虫中需要更多的计算,如需要计算经纬度,转换坐标,以及数据处理时,我们可以选择多进程的方法编写代码。效率会得到显著提高。但是并不意味这进程越多,速度越快。如果你的进程数远远超过你计算机内核数,可能会导致性能下降。
三. 总结
所以,当我们爬取数据时,如果数据量大且不使用类似scrapy这样的框架时,我们可以根据IO密集型或者是计算密集型任务,来使用多线程或多进程。因为目前爬虫与数据处理更多是分离的,所以爬虫更多是IO密集型,多线程可以显著提升速度,当存储关系型数据库时,也可以使用连接池配合多线程来使用,但具体使用本篇不做赘述。下篇文章将对scrapy框架的性能提升进行讲解。That’s All!!!

















 5869
5869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









