






 本文介绍了如何在Dataphin中创建和管理维度逻辑表,包括普通维度表的创建步骤,如业务对象的选择、字段的引入与配置、调度参数设置,以及后续的修改和关联其他维度表的操作。此外,还提及了维度表的四种类型及其应用场景。
本文介绍了如何在Dataphin中创建和管理维度逻辑表,包括普通维度表的创建步骤,如业务对象的选择、字段的引入与配置、调度参数设置,以及后续的修改和关联其他维度表的操作。此外,还提及了维度表的四种类型及其应用场景。
目录
创建配置普通维度逻辑表
普通维度逻辑表用于描述实体对象,包含对实体对象的各方面描述。例如会员普通维度逻辑表,包含会员名称、 会员ID、会员邮件等数据
创建维度逻辑表
1.在Dataphin首页,单击顶部菜单栏的研发研。 默认进入数据开发页面。
2.在数据开发页面,按照下图操作指引,进入新建维度逻辑表配置页面
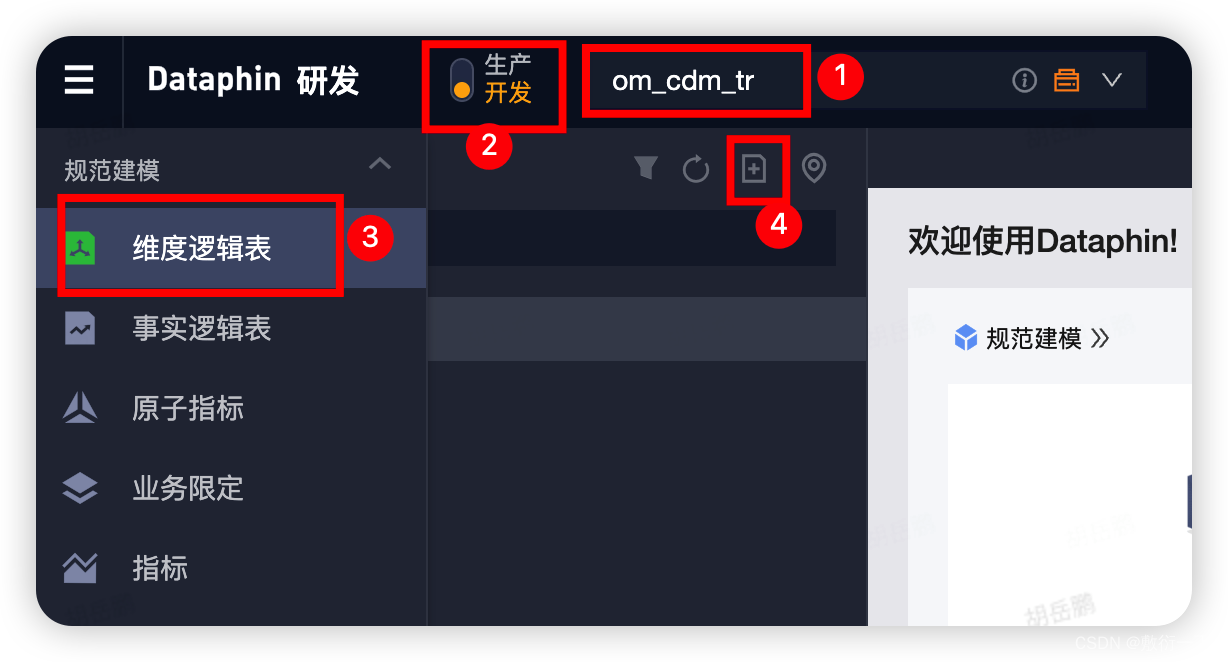
3.新建维度页面如下所示,配置参数后,点击确定
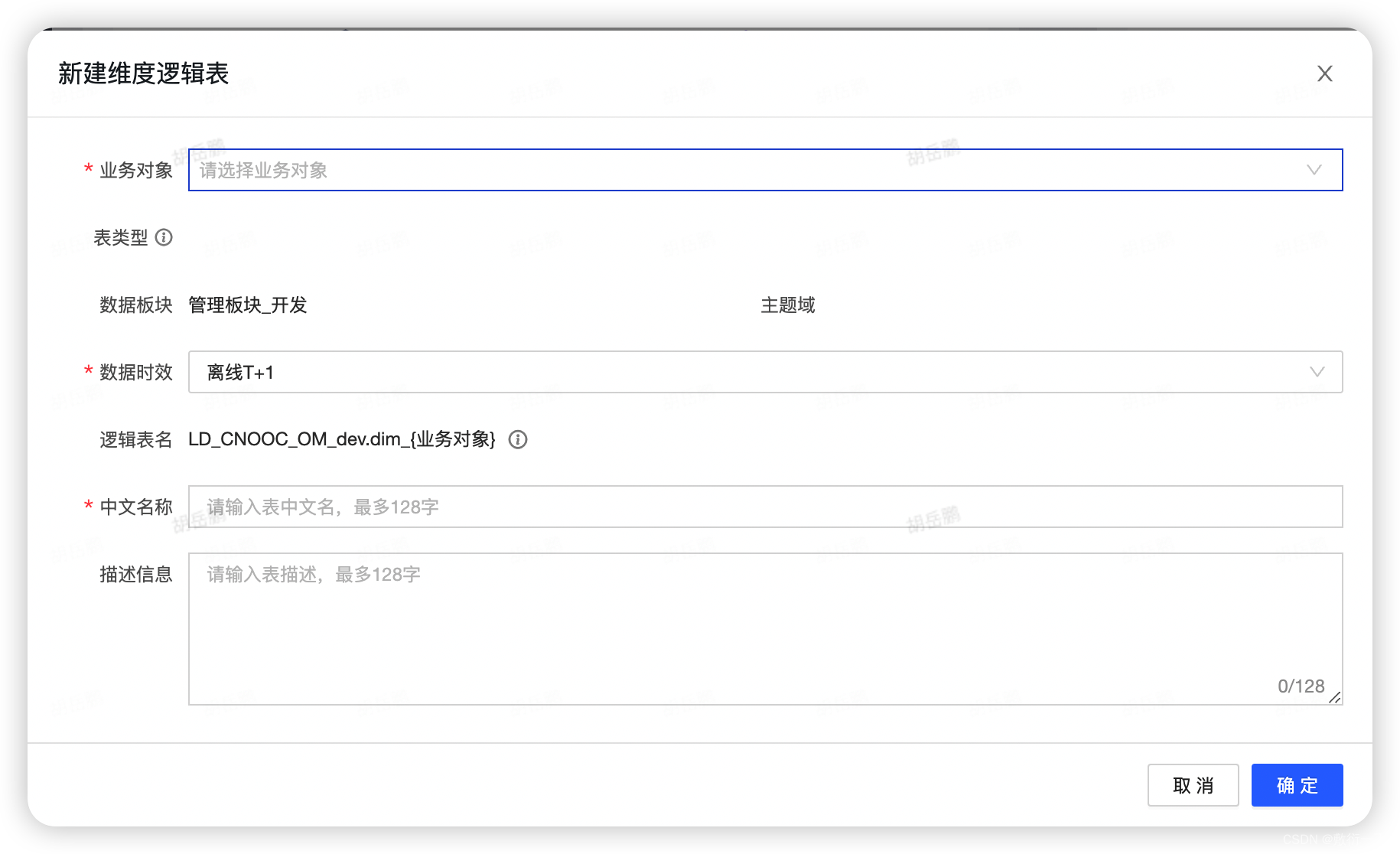
4.业务对象选择普通对象,点击新增
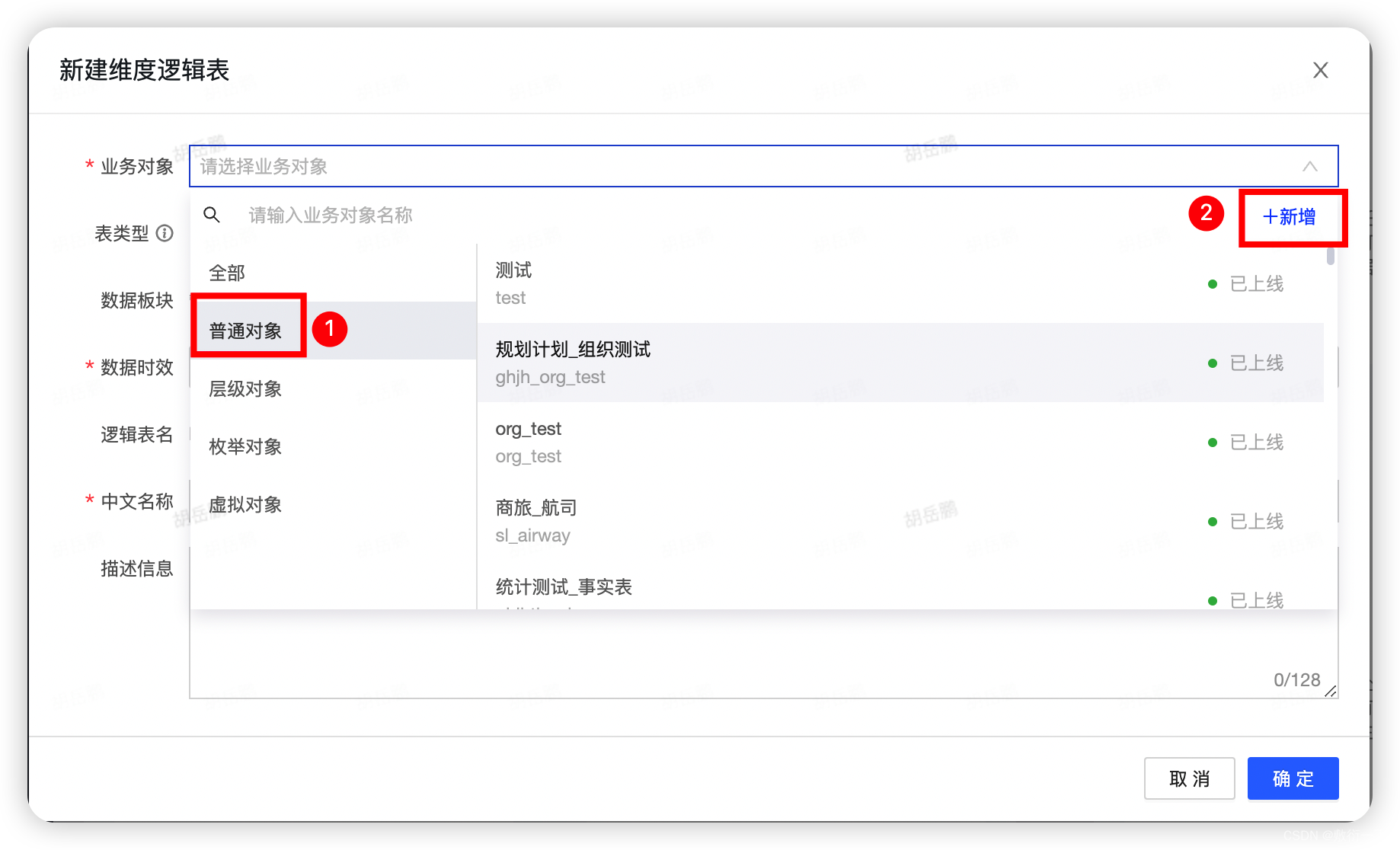
5.创建普通对象,填写实体名称、编码,选择实体类型为“业务对象/普通对象”,选择主题域,点击确定.
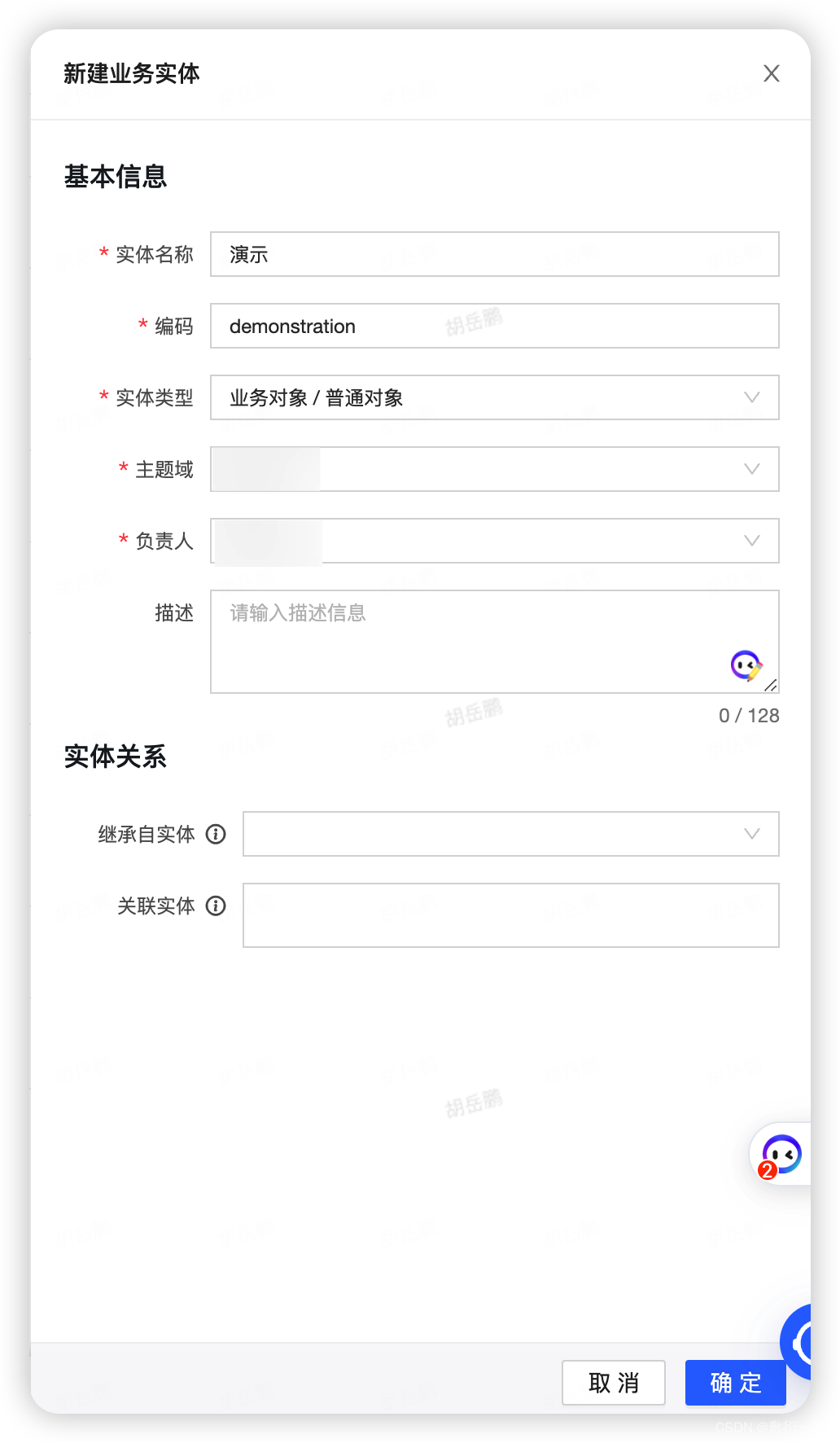
6.创建业务实体成功如下所示,点击发布,即可上线成功

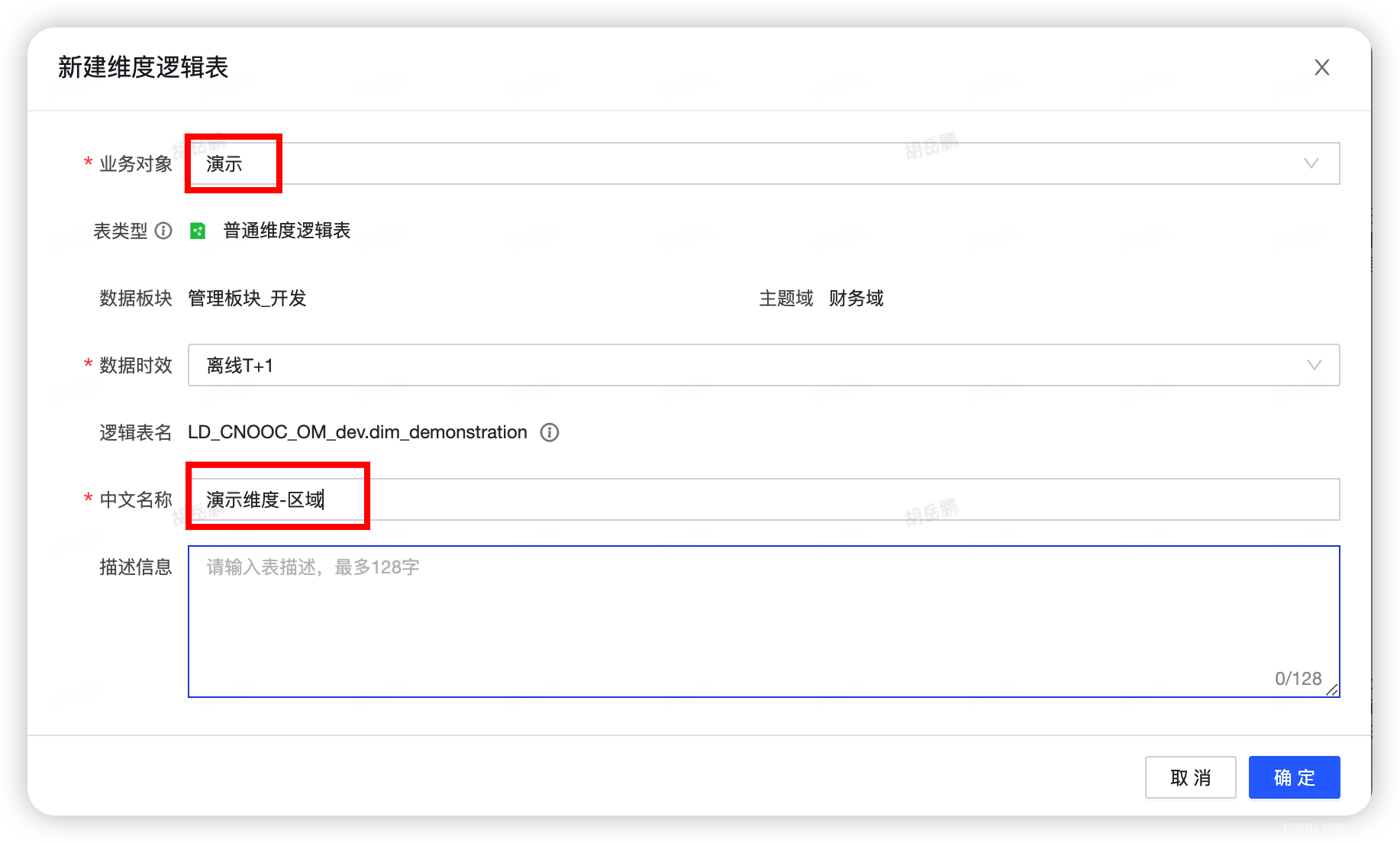
7.返回创建维度表页面,重新创建维度逻辑表模块,新建维度表,如下所示,填写相关配置,点击确定
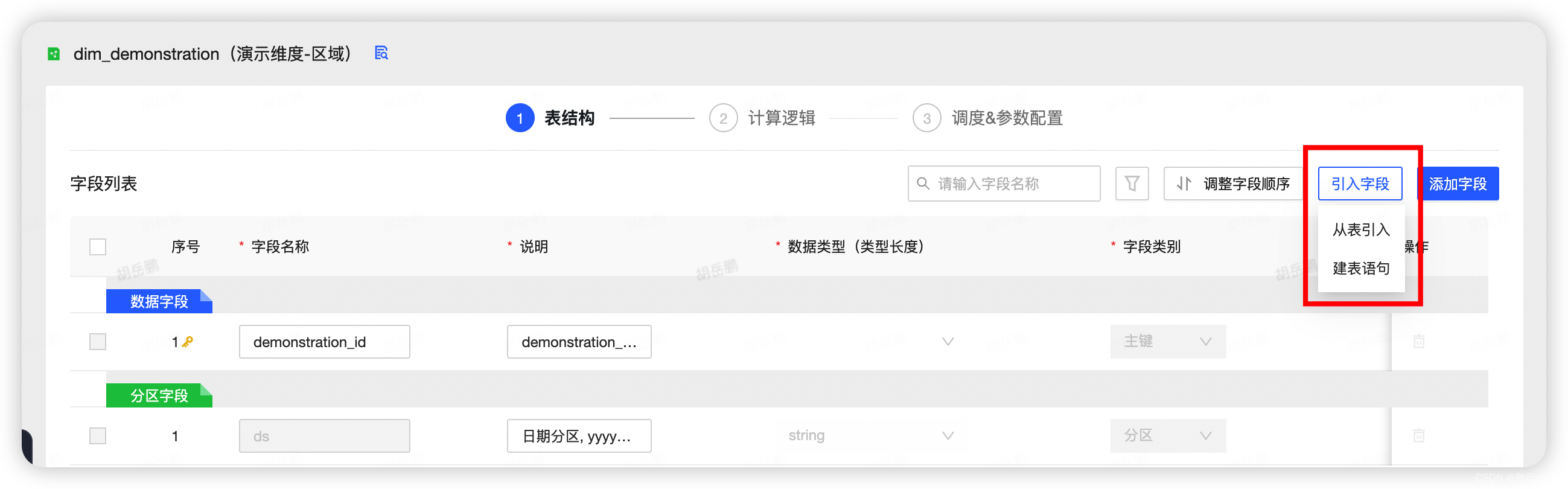
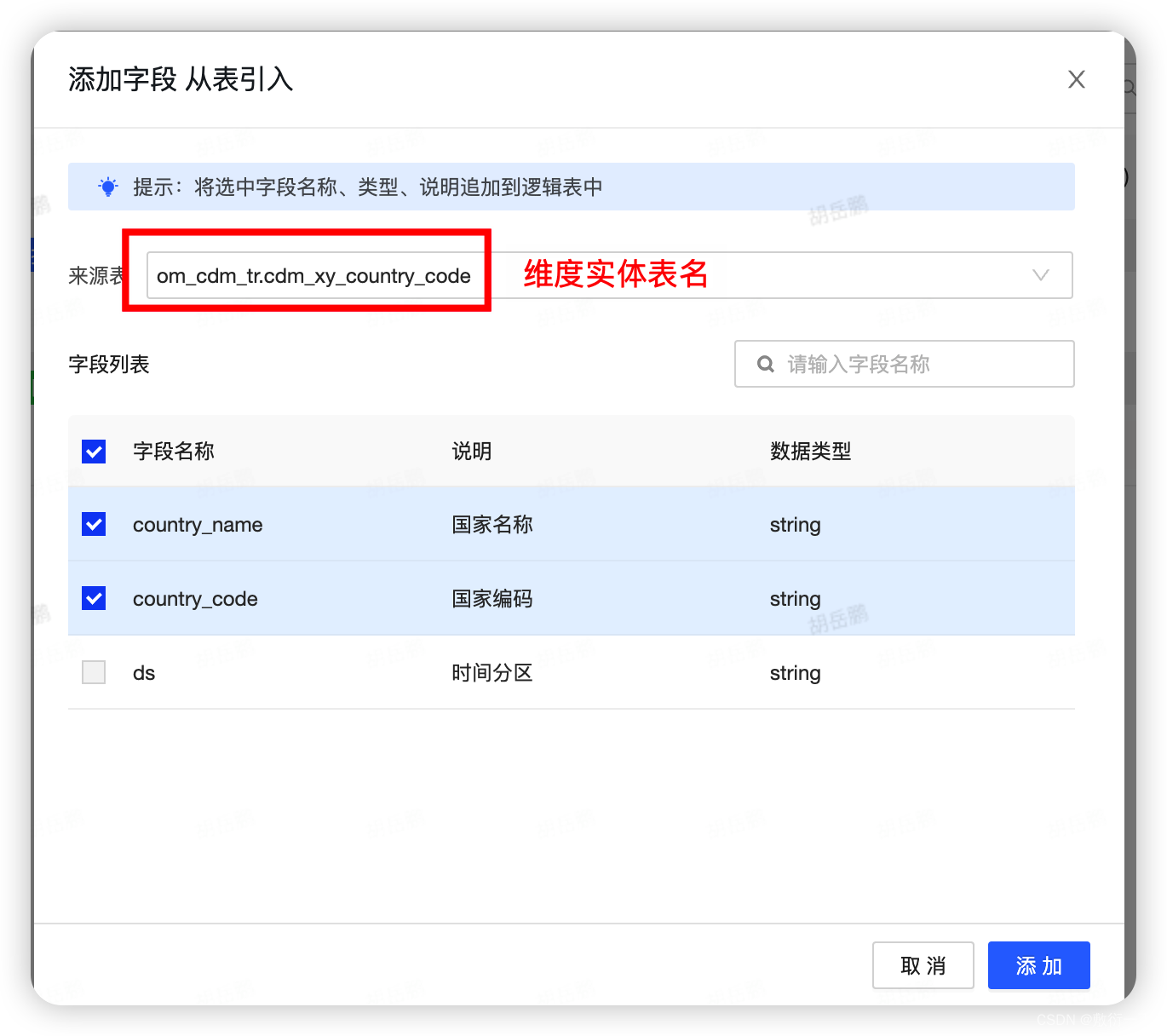
8.点击引入字段,选择区域的实体表,将所需的维度字段引入,点击添加
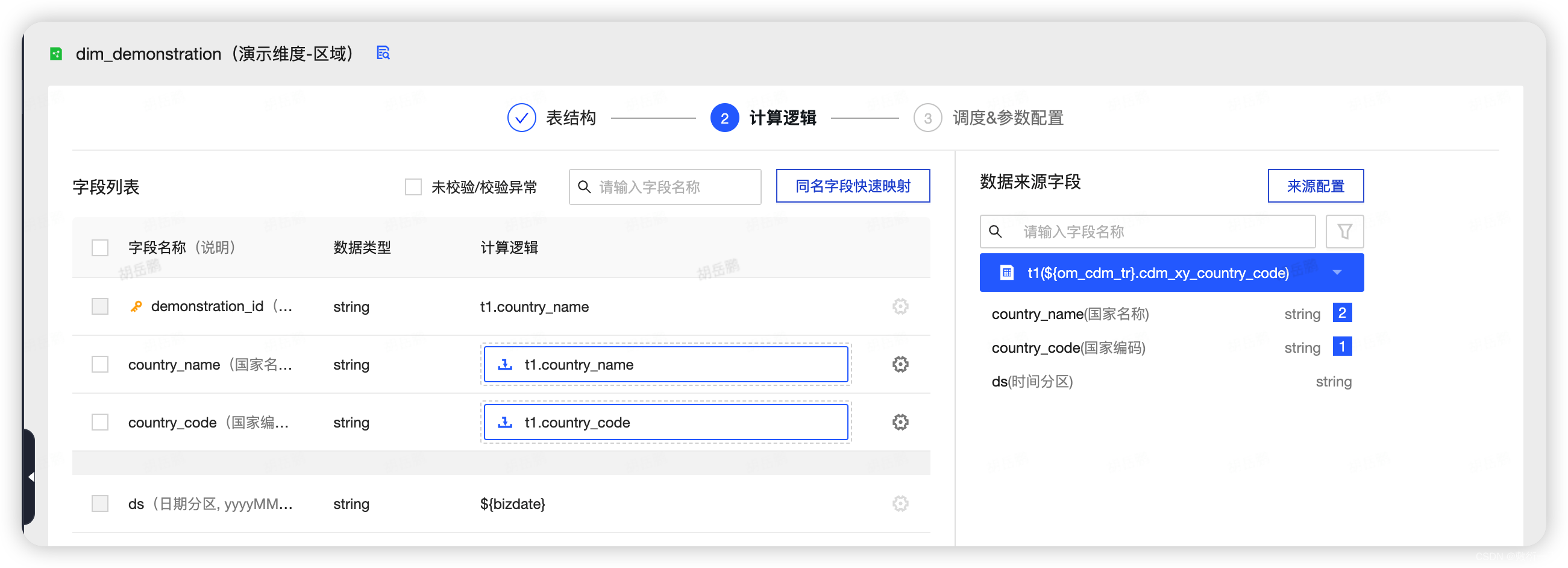
9.按照提示配置计算逻辑,点击下一步
10.调度和参数配置设置,可以点击自动解析,也可手动选择相应的上游依赖以及物理表,保存并且提交
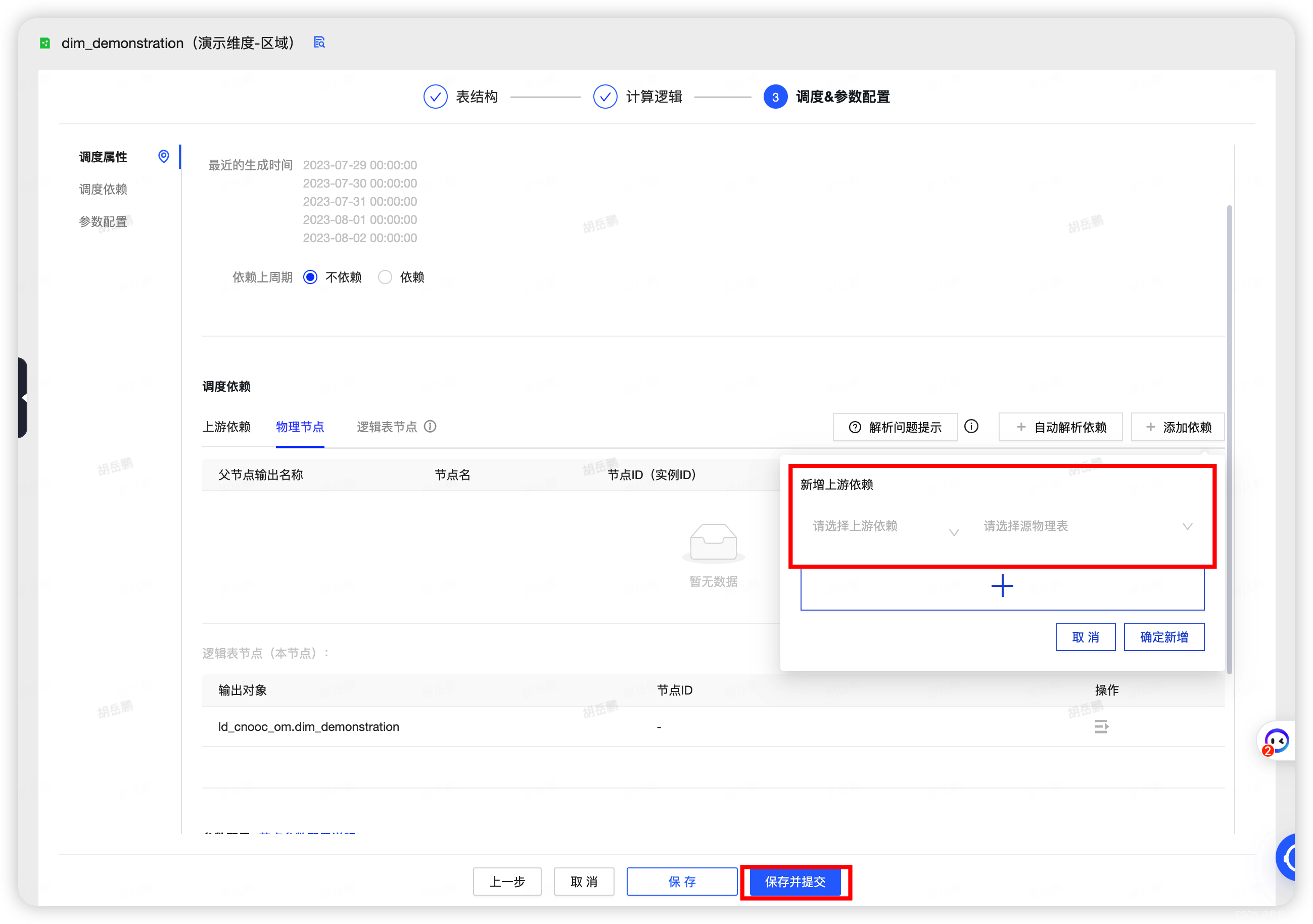
11.最后提交并且发布该维度逻辑表,发不成功即可在维度逻辑表中看到自己创建的维度表
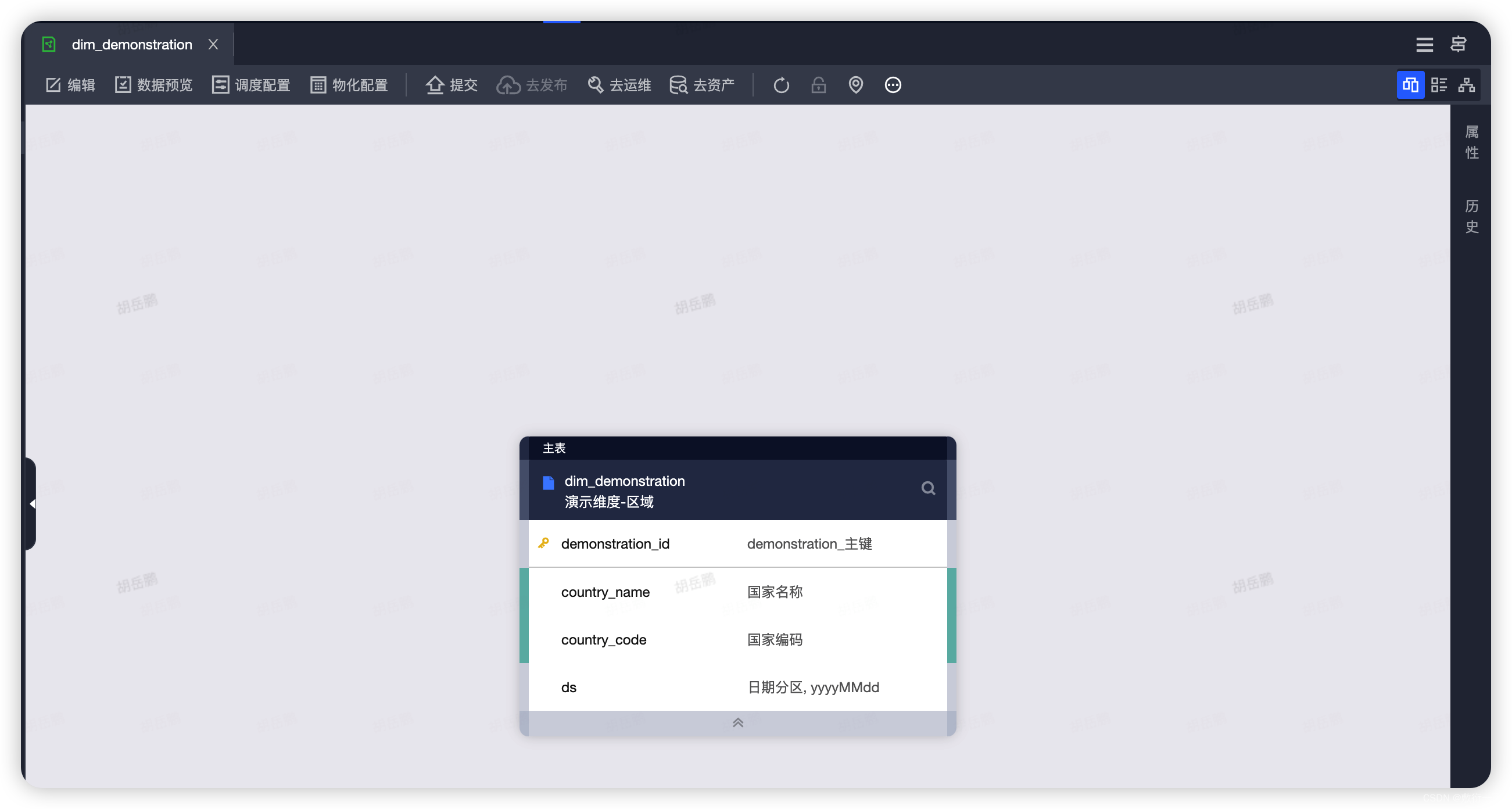
修改和关联维度表
1.如下图所示点击维度表右上角,在点击编辑按钮,即可修改维度表.
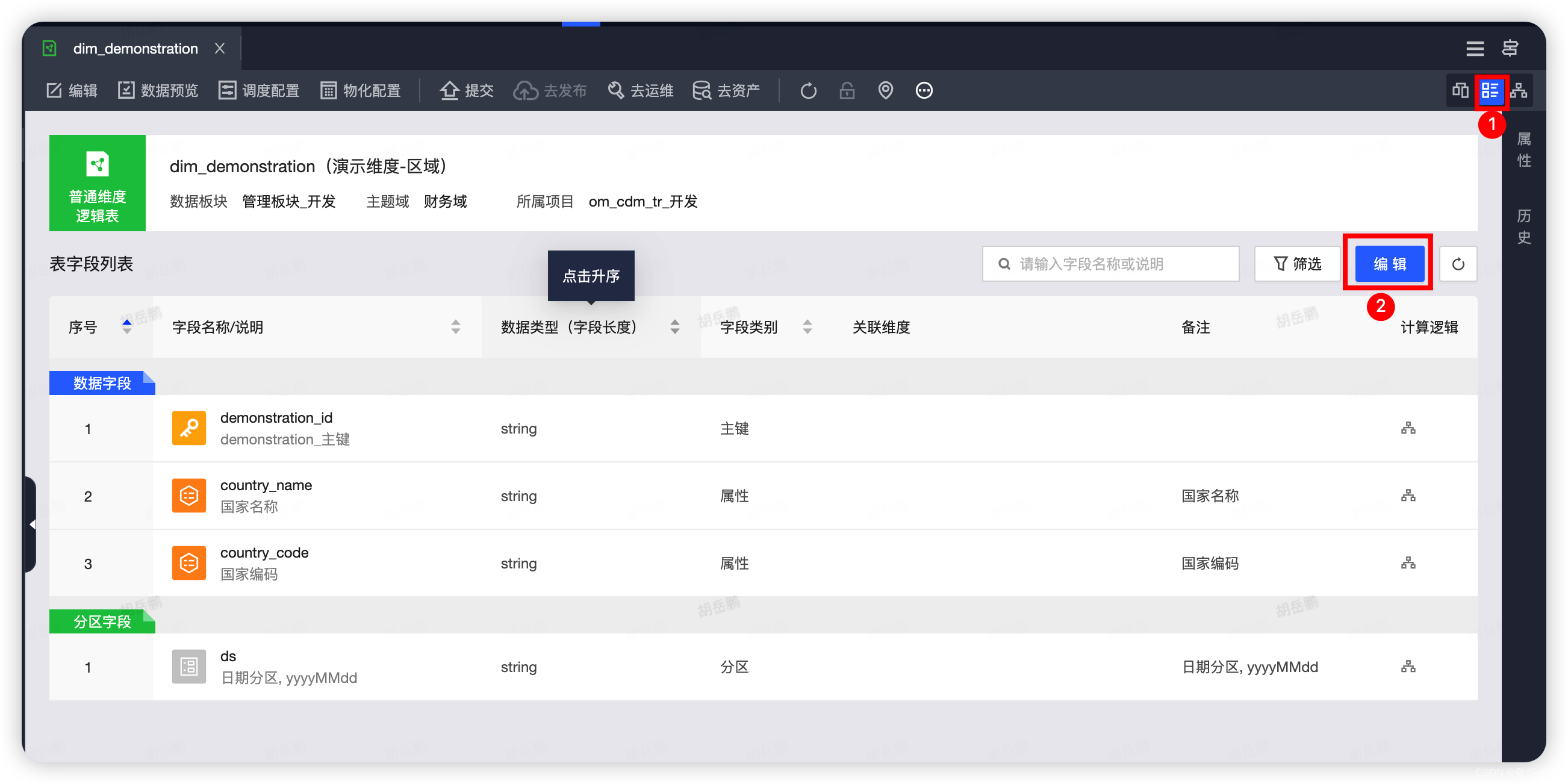
2.点击编辑,即可修改维度逻辑表,可以引入新的字段、自定义添加字段、删除原有的字段、配置字段类型及字段类别等数据,修改完毕之后重新保存发布即可
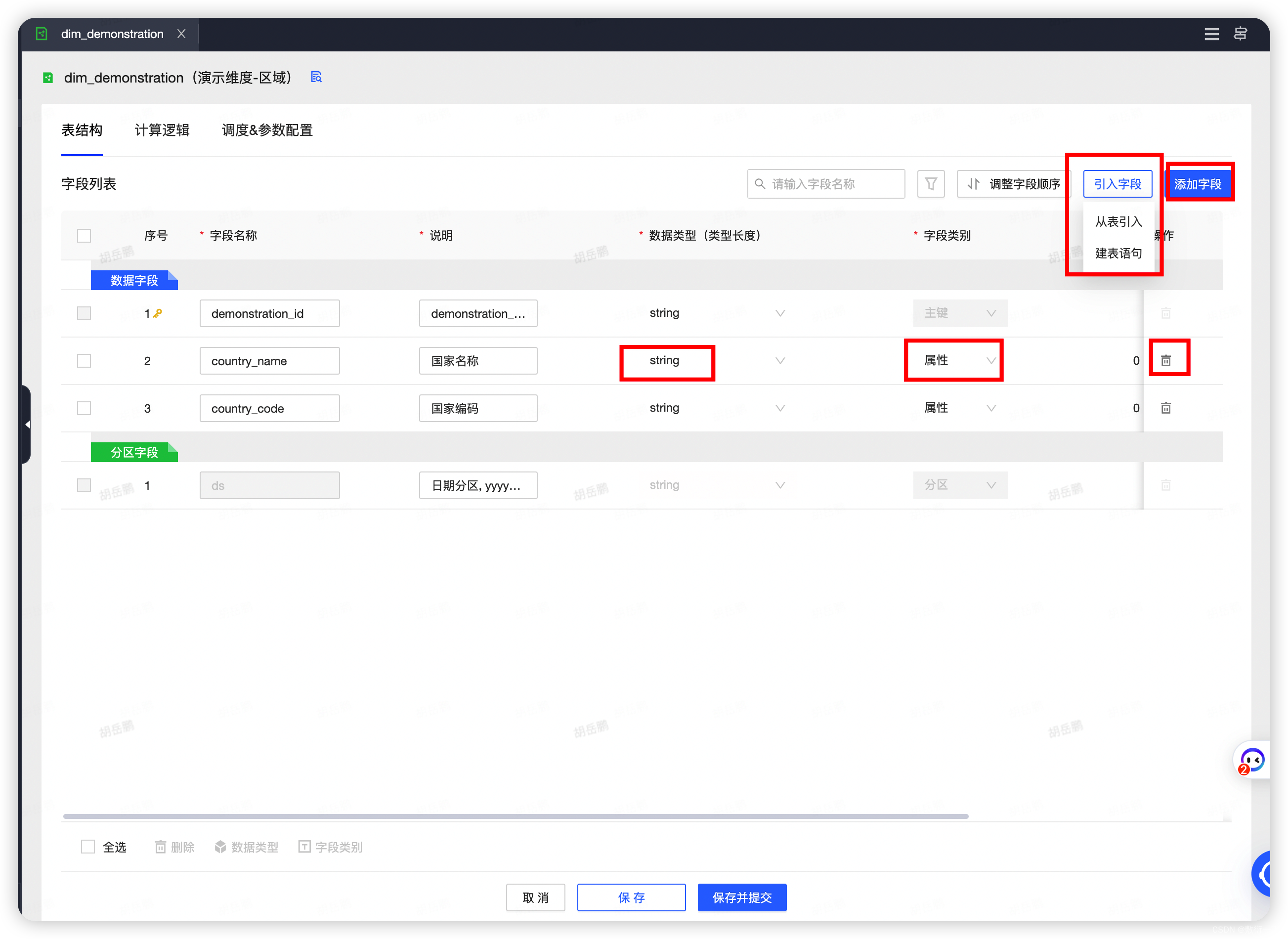
3.添加关联维度,在编辑页面点击关联维度按钮
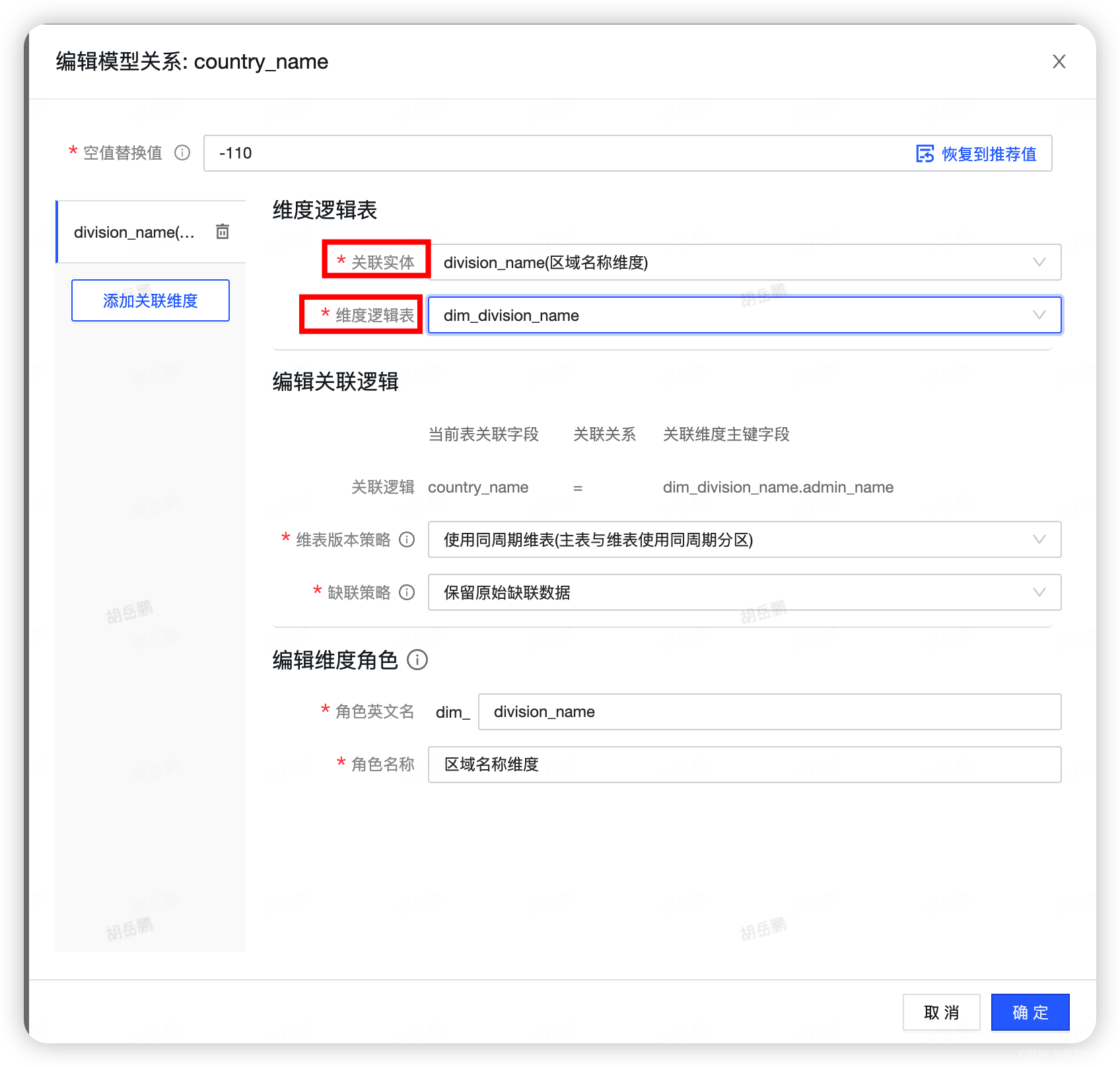
4.选择需要关联的实体以及现有的维度逻辑表,点击确定即可
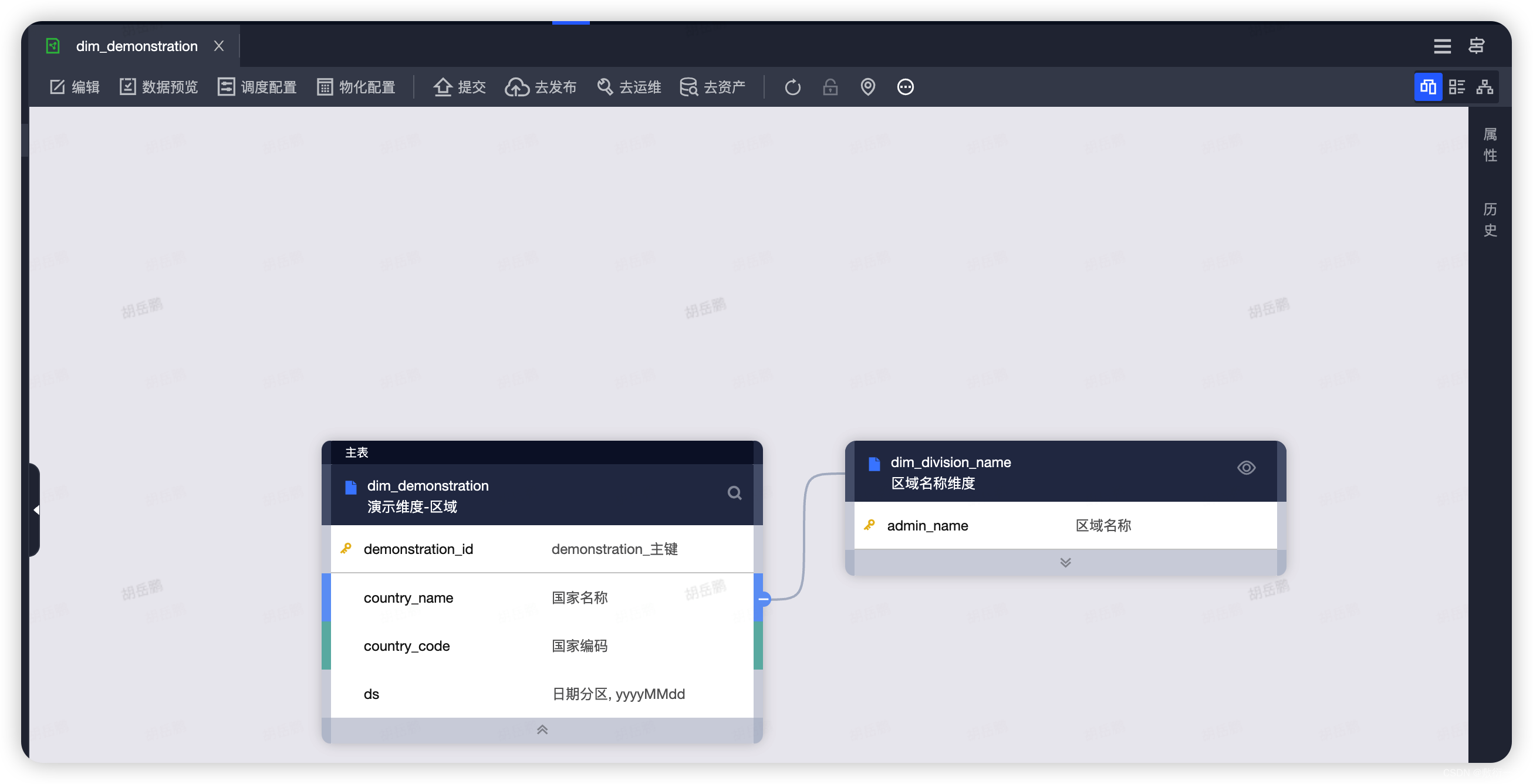
5.保存,提交并且发不成功,即关联维度成功
小结
维度逻辑表主要包括普通对象、层级对象、枚举对象、虚拟对象4种类型,分别对应普通维度表、层级维度表、枚举维度表和虚拟维度表四种不同类型的维度表,具体需要哪种类型的维度表,依据项目过程中具体的需求来定,创建方式和普通维度表一致.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









