









和图像数据增强不同,NLP中文本数据增强比较少见。图像的一些增强操作,如图像旋转、灰度处理等等都不会改变图像的语义,语义不变变换的存在使得增广成为计算机视觉研究中必不可少的工具。但在NLP中进行数据增强很容易就改变了文本的语义,这样就失去了增强的意义。接下来给大家介绍几种能够在不改变基础语言前提下,进行文本数据扩增的方法。
同义词替换
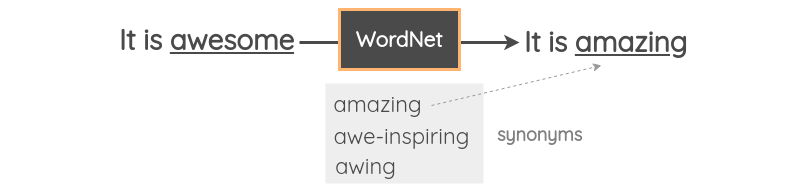
即采用同义词替换文本中的词,丰富程度取决于同义词的数量,且基本不会改变语义。
词向量替换
NLP中常见的embeding方式由bert、word2vec、tf-idf等等,我们可以选择使用词向量余弦夹角最相近的几个词进行替换。
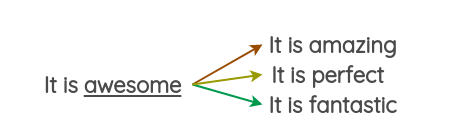
使用像Gensim这样的python包很容易得到预先训练好的单词向量并获得最相近的词向量。例如,这里我们使用在tweet上训练的单词向量找到单词“awesome”的同义词。
# pip install gensim
import gensim.downloader as api
model = api.load('glove-twitter-25')
model.most_similar('awesome', topn=5)
# 五个最相近的词向量
[('amazing', 0.9687871932983398),
('best', 0.9600659608840942),
('fun', 0.9331520795822144),
('fantastic', 0.9313924312591553),
('perfect', 0.9243415594100952)]
Masked Language Model 遮盖词替换
像BERT、ROBERTA和ALBERT这样的Transformer模型已经在大量的文本上进行了训练,使用了一个称为MLM的模型,会随机对文本中的单词进行遮盖,再利用上下文对该遮盖词进行预测。
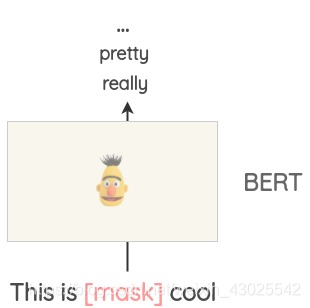
基于这一机制,我们可以遮盖需要增强文本的任一单词,再使用MLM模型对该词进行预测,选取前几个高概率单词进行替换。
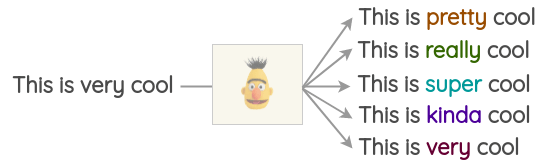
采用transformers包能够很容易实现这一方法,我们能够通过设置来标记我们想要遮盖的词,并生成多个预测词汇。
from transformers import pipeline
nlp = pipeline('fill-mask')
nlp('This is <mask> cool')
# Result
[{'score': 0.515411913394928,
'sequence': '<s> This is pretty cool</s>',
'token': 1256},
{'score': 0.1166248694062233,
'sequence': '<s> This is really cool</s>',
'token': 269},
{'score': 0.07387523353099823,
'sequence': '<s> This is super cool</s>',
'token': 2422},
{'score': 0.04272908344864845,
'sequence': '<s> This is kinda cool</s>',
'token': 24282},
{'score': 0.034715913236141205,
'sequence': '<s> This is very cool</s>',
'token': 182}]
但这种方式存在一个重要问题,如果选择的遮盖词过于重要,很容易预测出影响原文本语义的词汇。

这里可以采用tf-idf算法,筛选出数值较低的单词,表明对于文本的重要性较低,再进行mask标记预测。


















 2693
2693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











