






 重启Hive的metadata数据库后,CDH的Yarn节点报错,提示3个NodeManager丢失,重启CDH问题依旧,直接访问Yarn提示不存在。经测试发现NodeManager运行状况不良,原因是Yarn重启时恢复任务异常致节点掉线,删除指定目录下任务后重启Yarn恢复正常。
重启Hive的metadata数据库后,CDH的Yarn节点报错,提示3个NodeManager丢失,重启CDH问题依旧,直接访问Yarn提示不存在。经测试发现NodeManager运行状况不良,原因是Yarn重启时恢复任务异常致节点掉线,删除指定目录下任务后重启Yarn恢复正常。
问题描述:重启hive的metadata数据库,cdh的yarn节点报错,提示3个 NodeManager丢失。重启cdh,yarn仍然报同样错误。直接访问yarn提示不存在。
运行状态测试提示:
NodeManager 运行状况 不良
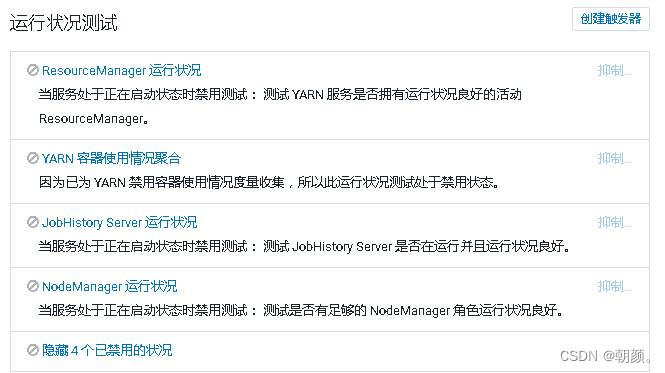
1.登录丢失的节点,查看yarn日志
2.原因:yarn在重启时,恢复任务异常,导致 NodeManager节点掉线
3.删除 /var/lib/hadoop-yarn/yarn-nm-recovery/ 下的任务
4.重启yarn,yarn正常
参考连接:https://community.cloudera.com/t5/Support-Questions/Yarn-NodeManager-fails-to-start-and-crashing-with-SIGBUS/m-p/67382#M33991

















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









