









https://blog.youkuaiyun.com/qq_39938758/article/details/108047840?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-1.control
网上找了一篇文章做补充
为什么学习Kafka
最近开始学习Kafka,至于为什么公司要用Kafka,处于懵懂的状态。老大说过公司的200多个应用服务,每个服务每天等访问量都很大,听说其中一个应用会达到百万/天的QPS,而Kafka的优势就是高吞吐,使用Kafka可以很好的满足场景。后面会开发一个监控系统,对应用的访问指标进行监控、告警等。
什么是Kafka
根据维基百科的定义,消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。也就是系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。
胡夕的《Kafka核心技术与实战》中提到过,Kafka是一个消息引擎系统,就像消息引擎一样,具备某种能量转换传输的能力。游客笔记的解释是:将上游的巨大能力平稳的输出到下游。个人感觉比较好理解。
Kafka相比其他消息系统的优势和劣势
吞吐量
- Kafka:17.3W/s
- RocketMQ:11.6W/s
- RabbitMQ:5.95W/s
Rabbitmq比kafka可靠,kafka更适合IO高吞吐的处理
- 以下场景你比较适合使用Kafka。你有大量的事件(10万以上/秒)、你需要以分区的,顺序的,至少传递成功一次到混杂了在线和打包消费的消费者、你希望能重读消息、你能接受目前是有限的节点级别高可用。
- 以下场景你比较适合使用RabbitMQ。你有较少的事件(2万以上/秒)并且需要通过复杂的路由逻辑去找到消费者、你希望消息传递是可靠的、你并不关心消息传递的顺序、你需要现在就支持集群-节点级别的高可用。
发送消息的方法
- 点对点模型
- 也叫做消息队列模型,系统A发送的消息只能被系统B接收,其他系统都不能接收A系统发送的消息
- 发布/订阅模型
- 有主题(Topic)的概念,可以理解成逻辑语义相近的的消息容器。有发送方和接收方,可以有多个发布者向相同的Topic发送消息,也可以有斗个订阅者接收同样主题的消息
Kafka术语
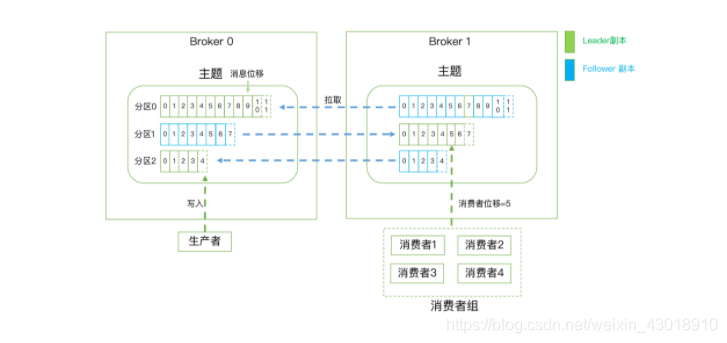
- Kafka体系架构=M个producer +N个broker +K个consumer+ZK集群
- server
- Broker:服务代理节点,Kafka服务实例。n个组成一个Kafka集群,通常一台机器部署一个Kafka实例,一个实例挂了其他实例仍可以使用,体现了高可用
- client
- producer:生产者
- consumer:消费者。消费topic 的消息, 一个topic 可以让若干个consumer消费,若干个consumer组成一个 consumer group ,一条消息只能被consumer group 中一个consumer消费,若干个partition 被若干个consumer 同时消费,达到消费者高吞吐量
- topic :主题
- partition: 一个topic 可以拥有若干个partition(从 0 开始标识partition ),分布在不同的broker 上, 实现发布与订阅时负载均衡。producer 通过自定义的规则将消息发送到对应topic 下某个partition,以offset标识一条消息在一个partition的唯一性。
- 一个partition拥有多个replica,提高容灾能力。
- 备份机制 Replication
- replica 包含两种类型:leader 副本、follower副本,
- leader副本负责读写请求,follower 副本负责同步leader副本消息,通过副本选举实现故障转移。
partition在机器磁盘上以log 体现,采用顺序追加日志的方式添加新消息、实现高吞吐量
为什么需要分区Partition
Kafka的消息组织方式时间上是三级结构:主题 -> 分区 -> 消息。主题小每条消息只会保存在某一个分区中,而不回在多个分区被保存多份。其中消息是Kafka处理的对象,分区是Kafka设计的负载均衡能力,提高吞吐率,实现Kafka的弹性伸缩。主题是Kafka对消息的分类,同一类消息被放在同一个Kafka队列中。
为什么要有两种类型的副本
- 前者对外提供服务,这里的对外指的是与客户端程序进行交互;而后者只是被动地追随领导者副本而已,不能与外界进行交互。副本的工作机制很简单,生产者总是向领导者副本写消息;而消费者总是从领导者副本读消息。至于追随者副本,它只做一件事:向领导者副本发送请求,请求领导者把最新生产的消息发给它,这样它能保持与领导者的同步。
- Kafka副本不对外提供服务的意义: 如果允许follower副本对外提供读服务(主写从读),首先会存在数据一致性的问题,消息从主节点同步到从节点需要时间,可能造成主从节点的数据不一致。主写从读无非就是为了减轻leader节点的压力,将读请求的负载均衡到follower节点,如果Kafka的分区相对均匀地分散到各个broker上,同样可以达到负载均衡的效果,没必要刻意实现主写从读增加代码实现的复杂程度
为什么要有分区
- 虽然有了副本机制可以保证数据的持久化或消息不丢失,但没有解决伸缩性的问题。Kafka设计把数据分割成多分保存在不同broker上,这种机制就是所谓的分区(Partitioning)
Kafka是如何决定将数据存放在哪个分区的
默认分区策略实际上实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
- 顺序分配:
- 比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
- 随机策略
- 所谓随机就是我们随意地将消息放置到任意一个分区上
- 按消息键保序策略
- Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略,

什么是Kafka的Offset
表示分区中每条消息的位置信息,是一个单调递增且不变的值
什么是Kafka的消费者位移:Consumer Offset。
表征消费者消费进度,每个消费者都有自己的消费者位移。
关于消息丢失
- Kafka如何保证消息不丢失 : 一句话概括,Kafka只对已经提交的消息做有限度的持久化保证
-
生产者程序丢失数据
- Producer 永远要使用带有回调通知的发送 API,也就是说不要使用 producer.send(msg),而要使用 producer.send(msg, callback)它能准确地告诉你消息是否真的提交成功了。一旦出现消息提交失败的情况,你就可以有针对性地进行处理。
-
消费者程序丢失数据
- Kafka 是能做到不丢失消息的,只不过这些消息必须是已提交的消息,而且还要满足一定的条件
要对抗这种消息丢失,办法很简单:维持先消费消息(阅读),再更新位移(书签)的顺序即可。这样就能最大限度地保证消息不丢失。这种处理方式可能带来的问题是消息的重复处理,类似于同一页书被读了很多遍
- Kafka 是能做到不丢失消息的,只不过这些消息必须是已提交的消息,而且还要满足一定的条件
-
关于消息重复处理
-
kafka对消息有三种处理方式
- 最多一次(at most once):消息可能会丢失,但绝不会被重复发送。
- 至少一次(at least once):消息不会丢失,但有可能被重复发送。
- 精确一次(exactly once):消息不会丢失,也不会被重复发送。
-
Kafka 默认提供的交付可靠性保障是第二种,即至少一次
- Kafka 是怎么做到精确一次的呢,简单来说,这是通过两种机制:
- 幂等性(Idempotence) : 只保证单分区的幂等性
- 指定 Producer 幂等性的方法很简单,仅需要设置props.put(“enable.idempotence”, ture),Kafka 自动帮你做消息的重复去重。
- 底层具体的原理很简单,就是经典的用空间去换时间的优化思路,即在 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们“丢弃”掉,
- 首先,它只能保证单分区上的幂等性,即一个幂等性 Producer 能够保证某个主题的一个分区上不出现重复消息,它无法实现多个分区的幂等性。其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。这里的会话,你可以理解为 Producer 进程的一次运行。当你重启了 Producer 进程之后,这种幂等性保证就丧失了。
- 事务(Transaction) : 能保证消息原子性的写入到多个分区中,而且不惧进程重启
- 事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
- 设置事务型 Producer 的方法也很简单,满足两个要求即可:
- 和幂等性 Producer 一样,开启 enable.idempotence = true。
- 设置 Producer 端参数 transactional. id。最好为其设置一个有意义的名字。
- 幂等性(Idempotence) : 只保证单分区的幂等性
- Kafka 是怎么做到精确一次的呢,简单来说,这是通过两种机制:
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}

















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









