






识别的表格类型
文本行pdf
使用pdfplumber库直接读取pdf中的表格数据,准确率很高,pdf顶部或者底部表格不完整的地方,数据需要单独处理,这种方式的pdf都需要预处理一下,在顶部和顶部加上表格线,或者单独处理数据首位行,现有代码没有加入此功能
图片型pdf
pdf中是图片类的,以及图片型的表格数据,这种需要先定位表格位置,然后调用ocr接口识别表格数据,如果不定位表格位置页面干扰太多,大大增加识别难度
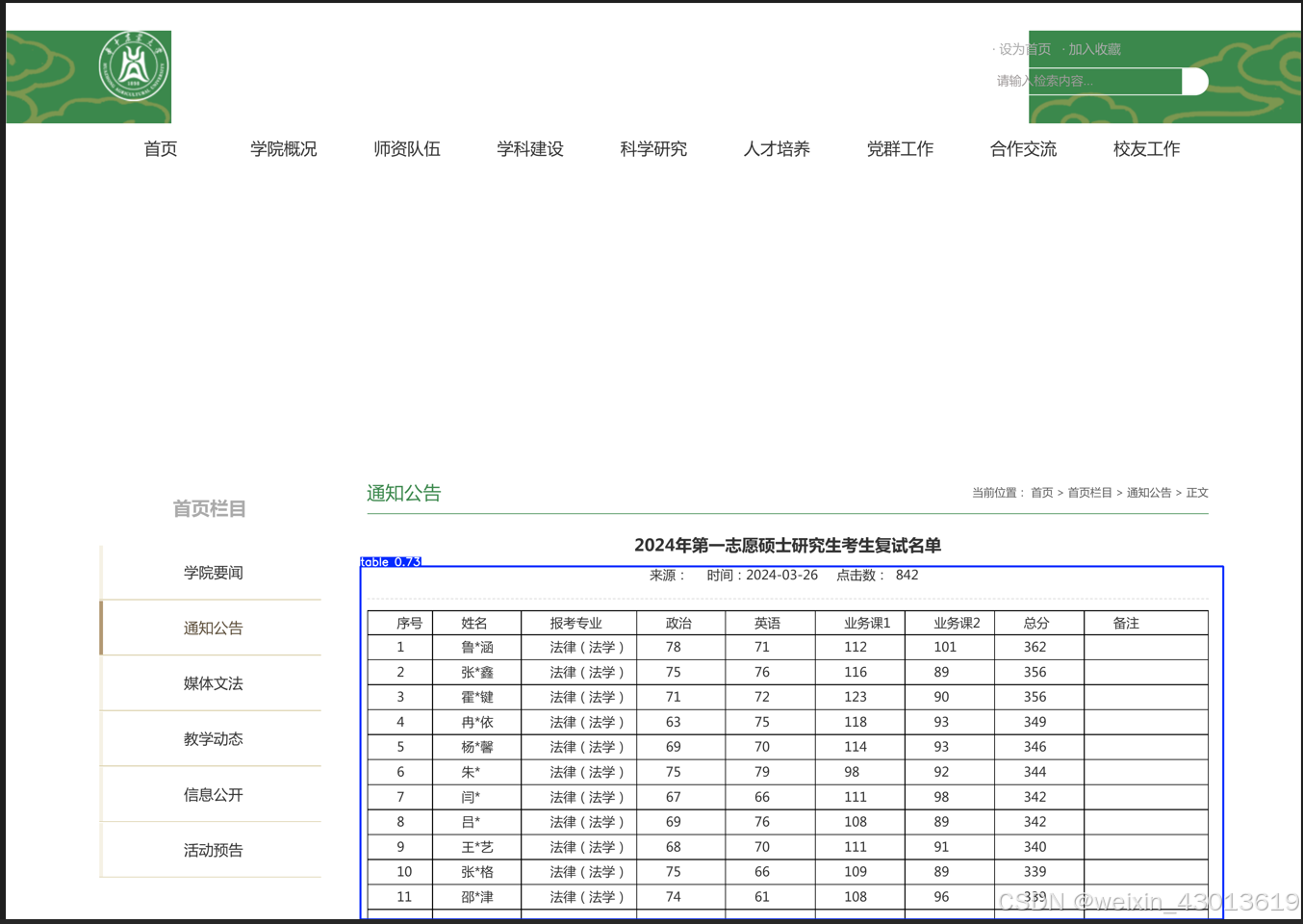
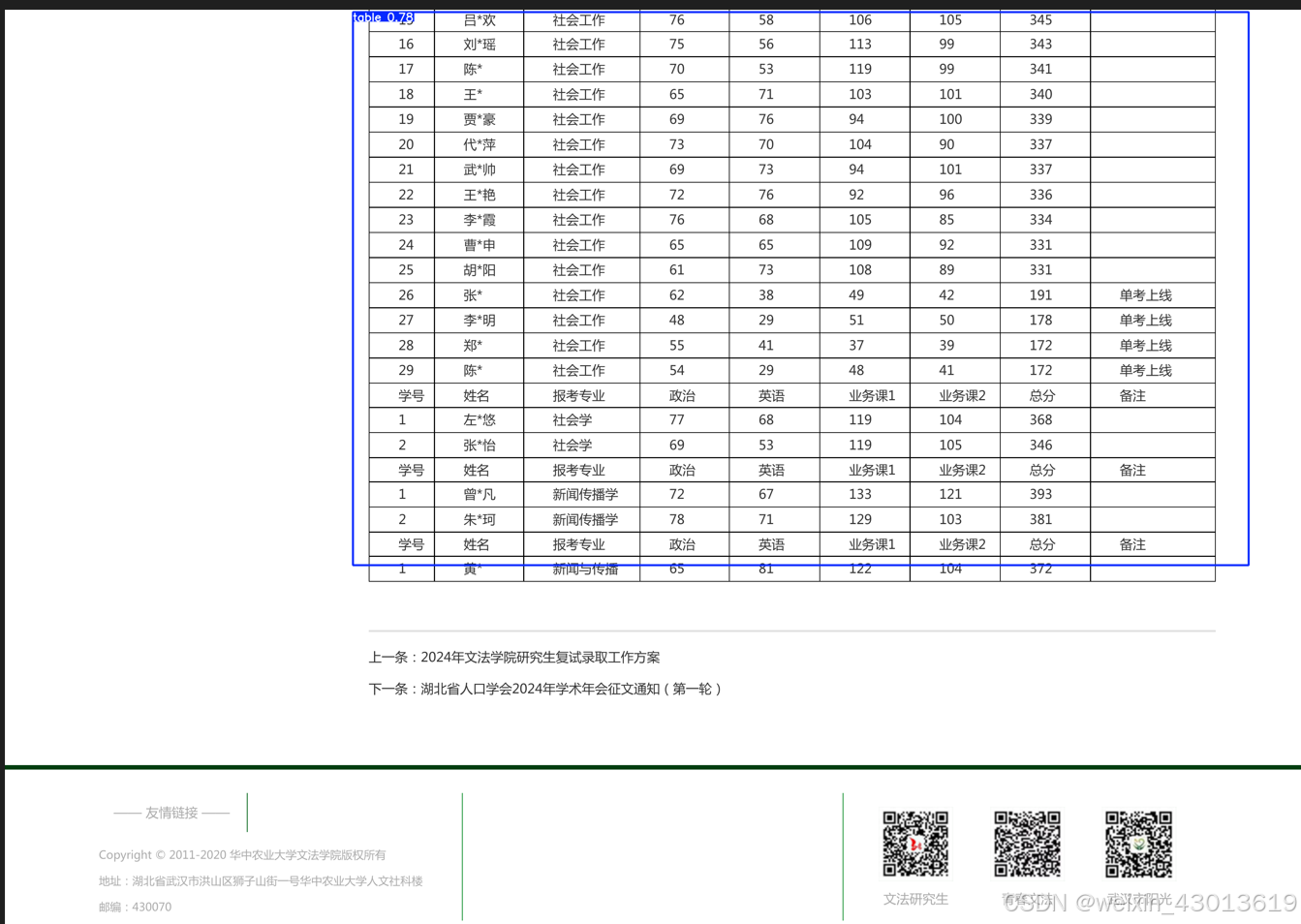
如果这是一张图片中的表格,那么直接使用ocr会得到大量多余信息,处理难度比较大,定位后截取在用ocr识别
但是由于当前的数据样本太少,只有三十张图左右,需要更多样本提升精度
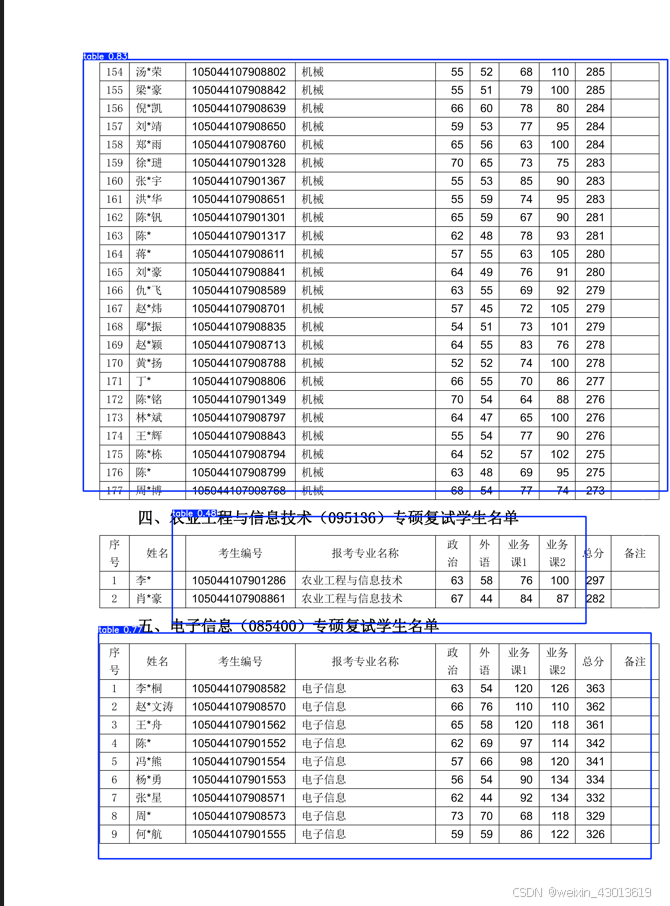
excel类表格
这种直接使用pandas将excel转成DataFrame就可以处理
表格分类的语义识别
MODEL_COLUMNS = [
'专业代码', '专业', '考生编号', '姓名', '学习方式全日制/非全日制', '科目一(政治)',
'科目二(英语)', '科目三(专业课一)', '科目四(专业课二)', '初试成绩', '复试成绩',
'总成绩', '照顾政策士兵计划/少干计划/其它', '录取类别定向/非定向',
'研究方向请填写研究方向写具体细分方向', '是否是调剂生', '年份', '备注'
]
由于每个表格的标题分类都不同,如果后面分类名称不多的情况下
人工统计后,直接使用计算字符串相似度的方法来匹配分类
如果分类标签太多,需要使用NLP模型来进行语义分类

















 3690
3690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









