









文章目录
前言
限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。
这往往也是权衡了软件系统的稳定性之后得到的最优解。
- 本文设计实现JAVA高可用的限流算法、分布式限流、熔断框架、服务治理、熔断器、网关、Spring Cloud Gateway

一、常见限流算法
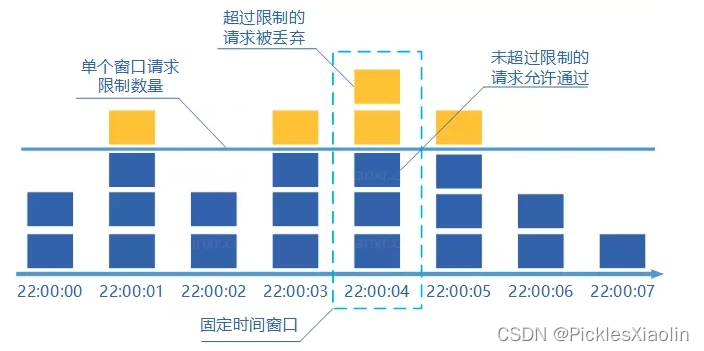
1.1 固定窗口计数器算法(严重的临界问题)
- 规定了我们单位时间处理的请求数量。
- 1 分钟之内每处理一个请求之后就将 counter+1 ,当 counter=33 之后(也就是说在这1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。下一秒清零。
- 这种限流算法无法保证限流速率,因而无法保证突然激增的流量。
- 比如说我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为
500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。在当前场景下,这 1000 个请求在 1s内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
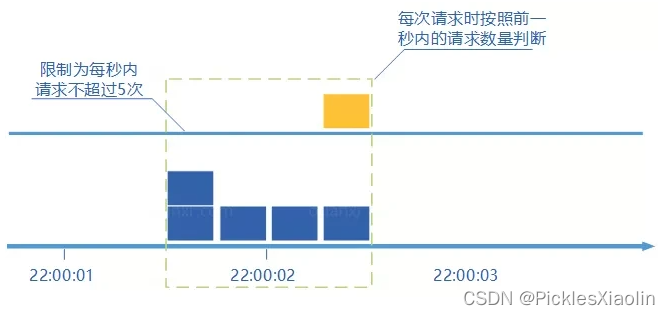
1.2 滑动窗口计数器算法(细化颗粒度)
- 是固定窗口计数器算法的升级版。
- 它把时间以一定比例分片,每隔 1 秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求,如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
- 很显然, 当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
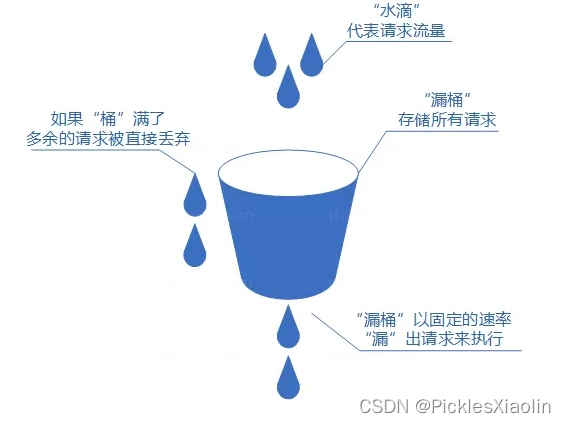
1.3 漏桶算法(缓存队列)
- 我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。
- 准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
1.4 令牌桶算法(同漏,处理不一样)
令牌桶算法是目前应用最广泛的一种限流算法,它的基本思想由两部分组成:生成令牌 和 消费令牌。
- 生成令牌:假设有一个装令牌的桶,最多能装 M 个,然后按某个固定的速度(每秒 r 个)往桶中放入令牌,桶满时不再放入
- 消费令牌:我们的每次请求都需要从桶中拿一个令牌才能放行,当桶中没有令牌时即触发限流,这时可以将请求放入一个缓冲队列中排队等待,或者直接拒绝(同样要缓存等待)
1.4.1 令牌桶和漏桶的区别:
- 将请求放在一个缓冲队列中,可以看出这一部分的逻辑和漏桶算法几乎一模一样,只不过在处理请求上,一个是以固定速率处理,一个是从桶中获取令牌后才处理。
- 桶大小的设置,正是这个参数可以让令牌桶算法具备处理突发流量的能力。譬如将桶大小设置为 100,生成令牌的速度设置为每秒 10个,那么在系统空闲一段时间的之后(被装满),突然来了 50 个请求,这时系统可以直接按每秒 50个的速度处理,随着桶中的令牌很快用完,处理速度又会慢慢降下来,和生成令牌速度趋于一致。
- 漏桶算法无论来了多少请求,只会一直以每秒 10个的速度进行处理 令牌桶可以提高系统性能,但需要设置合理的桶大小。
二、单机限流
- RateLimiter 基于令牌桶算法,可以应对突发流量。除了最基本的令牌桶算法**(平滑突发限流)**实现之外,Guava 的
RateLimiter还提供了 平滑预热限流 的算法实现。 - 平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。
- Spring Cloud Gateway 中自带的单机限流的早期版本就是基于 Bucket4j 实现的。后来,替换成了 Resilience4j。
- 一般情况下,为了保证系统的高可用,项目的限流和熔断都是要一起做的。
Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重试等保障系统高可用开箱即用的功能。并且,Resilience4j 的生态也更好,很多网关都使用 Resilience4j 来做限流熔断的。
三、分布式限流
分布式限流常见的方案:
借助中间件架限流 :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
网关层限流 :比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。比如 Spring Cloud Gateway 整合 Sentinel 来做限流。
四、服务治理
4.1 轻量级熔断框架:Resilience4
- 如果你新建了一条街道(相当于启动了一个新的服务节点),那么就要通知所有的车辆(流量)有新的道路可以走了;你关闭了一条街道,你也要通知所有车辆不要从这条路走了,这就是服务的注册和发现
- 在道路上安装监控,监视每条道路的流量情况,这就是服务的监控。
- 一旦出现拥堵或者道路需要维修,那么就需要暂时封闭这条道路,由城市来统一调度车辆,走不堵的道路,这就是熔断以及引流。
- 道路从头堵到尾,说明事故并不是发生在这条道路上,那么就需要从整体链路上来排查事故究竟处在哪个位置,这就是分布式追踪。
- 不同道路上的车辆有多有少,那么就需要有一个警察来疏导,在某一个时间走哪一条路会比较快,这就是负载均衡。
4.2 雪崩:
在分布式环境下,系统最怕的反而不是某一个服务或者组件宕机,而是最怕它响应缓慢,因为,某一个服务或者组件宕机也许只会影响系统的部分功能,但它响应一慢,服务调用方等待服务提供方的响应时间过长,它的资源被耗尽,才引发了级联反应,发生雪崩,进而拖垮整个系统。
4.3 熔断
熔断就是在检测到某一个服务的响应时间出现异常时,切断调用它的服务与它之间的联系,从而释放这次请求持有的资源。
4.4 历史发展
Netflix Hystrix 断路器是 Spring Cloud 中最早就开始支持的一种服务调用容错解决方案,Resilience4j 是一个轻量级的容错组件,其灵感来自于 Hystrix。自Netflix 宣布不再积极开发 Hystrixopen in new window 之后,Spring 官方和 Netflix 都更推荐使用 Resilience4j 来做限流熔断。
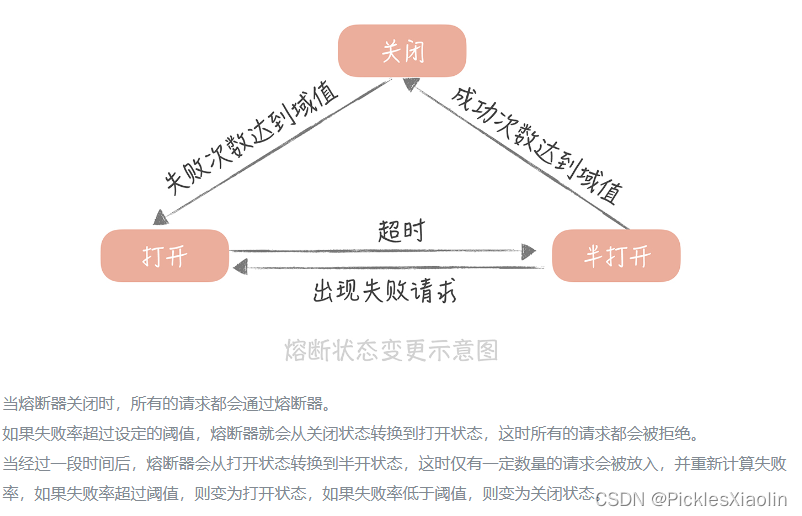
4.5 熔断状态更改
4.6 环形缓冲区
- Resilience4j 记录请求状态的数据结构和 Hystrix 不同,Hystrix 是使用滑动窗口来进行存储的,而
Resilience4j 采用的是 Ring Bit Buffer(环形缓冲区)。 - Ring Bit Buffer 在内部使用 BitSet 这样的数据结构来进行存储。计算失败率需要填满环形缓冲区。
- 当经过一段时间后,熔断器的状态会从 OPEN 变为 HALF_OPEN,HALF_OPEN 状态下同样会有一个 Ring Bit
Buffer,用来计算 HALF_OPEN 状态下的故障率,如果高于配置的阈值,会转换为 OPEN,低于阈值则装换为 CLOSE。
与 CLOSE 状态下的缓冲区不同的地方在于,HALF_OPEN 状态下的缓冲区大小会限制请求数,只有缓冲区大小的请求数会被放入。
五、程序实现
5.1 熔断器的线程安全
熔断器的状态使用 AtomicReference 保存的
更新熔断器状态是通过无状态的函数或者原子操作进行的
更新事件的状态用 synchronized 关键字保护
意味着同一时间只有一个线程能够修改熔断器状态或者记录事件的状态。
5.2 参数设置:
return CircuitBreakerConfig.custom()
// 环形缓冲区大小是 10,填满 10 个请求后,才开始计算失败率,达到 60%即熔断
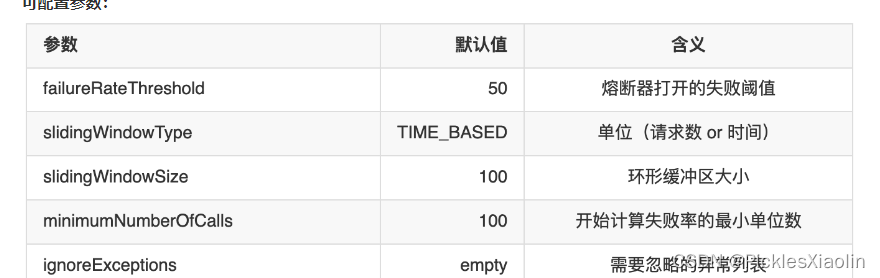
.failureRateThreshold(60) // 熔断器打开的失败阈值
.slidingWindowType(SlidingWindowType.COUNT_BASED)
.slidingWindowSize(10)
.minimumNumberOfCalls(10)
.slidingWindow(10, 10, SlidingWindowType.COUNT_BASED)// 替代上面三个属性
5.3 程序可配置参数
六、SpringCloudGateway
6.1 发展优势:
不仅支持响应式和无阻塞式的 API,而且支持 WebSocket,和 Spring 框架紧密集成。优于Netflix的zuul,其阻塞式API,不支持WebSocket,被人诟病。
6.2 生态:
Spring Cloud Gateway 可以很方便的和 Spring Cloud 生态中的其他组件进行集成(比如:断路器和服务发现),而且提供了一套简单易写的 断言(Predicates,有的地方也翻译成 谓词)和 过滤器(Filters)机制,可以对每个 路由(Routes)进行特殊请求处理。
6.3 限流场景
缓存、降级 和 限流 被称为高并发、分布式系统的三驾马车,网关作为整个分布式系统中的第一道关卡,限流功能自然必不可少。
6.4 限流的对象
请求频率限流(Request rate limiting)和 并发量限流(Concurrent requests limiting)传输速率限流。
6.5 限流的处理方式
-
拒绝服务:最简单的做法是拒绝服务,直接抛出异常,返回错误信息(比如返回 HTTP 状态码 429 Too Many
Requests),或者给前端返回 302 重定向到一个错误页面,提示用户资源没有了或稍后再试。 -
排队等待:比较重要的接口不能直接拒绝,比如秒杀、下单等接口,我们既不希望用户请求太快,也不希望请求失败,这种情况一般会将请求放到一个消息队列中排队等待,消息队列可以起到削峰和限流的作用
-
服务降级:当触发限流条件时,直接返回兜底数据,比如查询商品库存的接口,可以默认返回有货。
6.6 限流的架构
-
单机模式的限流非常简单,可以直接基于内存就可以实现,
-
集群模式的限流必须依赖于某个“中心化”的组件,比如网关或
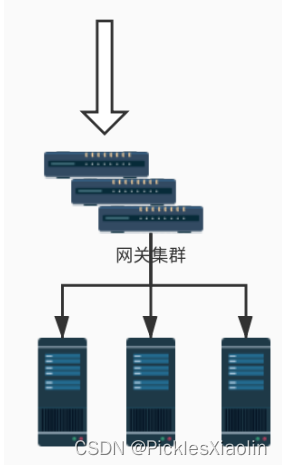
Redis,从而引出两种不同的限流架构:1、网关层限流:除了我们使用的 Spring Cloud Gateway, 最常用的网关层组件还有 Nginx, 2、中间件限流:将限流的逻辑下沉到服务层。集群中的每个服务必须将 自己的流量信息统一汇总到某个地方供其他服务读取,一般来说用 Redis 的比较多。 3、网关中间件限流:将网关改为集群模式,还是网关层限流架构。但是 由于网关变成了集群模式,所以网关必须依赖于中间件进行限流。

















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









